前言
HashMap线程安全的问题,在各大面试中都会被问到,属于常考热点题目。虽然大部分读者都了解它不是线程安全的,但是再深入一些,问它为什么不是线程安全的,仔细说说原理,用图画出一种非线程安全的情况?1.8之后又做了什么改善了这点?很多读者可能一时想不出很好的答案。
其实在网上已经有很多优秀的博主讨论过这个问题,本文的写作意图是通过更加详细的画图分析和1.7与1.8之间版本对比来帮助大家通过java面试。
1.7版本的HashMap
我们关注下面的代码
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
这段代码的主要做的是rehash,其中的核心代码是12~16行,下面画图分析,当有多个线程同时做rehash时,会发生什么。
假设条件如下:
-
扩容前数据长度为2,扩容后为4,并且有key为3,5,7的三个entry需要rehash
-
有两个线程都在做rehash,第一个线程执行到12行挂起,第二个线程rehash结束
扩容前的图示如下:

线程2执行完成rehash和线程1执行到12挂起的图示如下:
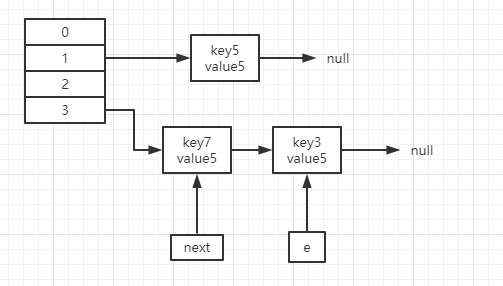
然后我们一步一步的分析线程1继续rehash的情况
当e为key3时,经过12~16步后的图示如下,我们发现3被插入到了头部,并且形成了环形链表

因为e不为null,所以我们继续执行12~16行,执行完毕后如图所示
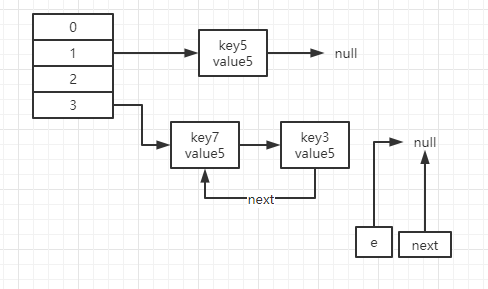
至此两个线程的扩容都完毕,形成了环形链表。
所以当调用get方法时,因为环形链表的存在,形成一个死循环,占满cpu。
1.8版本的HashMap
首先说明,1.8版本的resize方法做了一些优化,优化的点主要在于,当hashmap的size扩容为2倍时,其实不需要每个元素都计算hash值,元素在新数组中的位置只有以下两种情况:
- 原位置
- 原位置+原数组长度
为什么只有这两种情况呢?我们看下图:

a是原数组长度-1,b是扩容为2倍的新数组长度-1,对于第一行n-1来说,其实就多了从右往左的第五位的1。
对于key1和key2来说,key1的第五位是0,key2的第五位是1,所以rehash后:
- key1的元素位置仍为原来的位置不变 仍为5
- key2的元素位置为 原来位置 + 原数组长度 5+16 = 21
明白这点后,我们继续关注下面的代码,因为resize方法中还有一些和问题领域不那么相关的代码,所以我只粘贴出分析问题的必需代码。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//原数组遍历,拿到链表头
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//关注这里的rehash代码
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//代表了多出来的第X位为0的情况
if ((e.hash & oldCap) == 0) {
if (loTail == null)
//没有元素时,设置头部为e
loHead = e;
else
//有元素时,把e插入到尾部
loTail.next = e;
//更新链表尾部指针到最新结点
loTail = e;
}
//代表了多出来的第X位为1的情况
else {
if (hiTail == null)
//没有元素时,设置头部为e
hiHead = e;
else
//有元素时,把e插入到尾部
hiTail.next = e;
//更新链表尾部指针到最新结点
hiTail = e;
}
} while ((e = next) != null);
//走到这里,就已经把原链表结点分成了两组
//设置位置不变组的数组头结点为loHead结点
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//设置新数组的头结点为loHead结点
//设置位置变为原位置 + 原数组长度 组的数组头结点为hiHead结点
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
多线程分析
我们依旧按照上面的假设画图分析
假设条件如下:
-
扩容前数据长度为2,扩容后为4,并且有key为3,5,7的三个entry需要rehash
-
有两个线程都在做rehash,第一个线程执行到19行挂起,第二个线程rehash结束
因为1.8版本的插入过程修改为了尾插法,插入前的图示变为如下所示
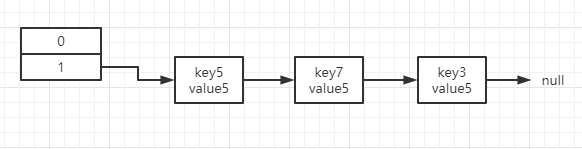
线程2执行完成rehash和线程1执行到19行挂起时状态如下:

线程1继续rehash,走完7和3之后的结果如下
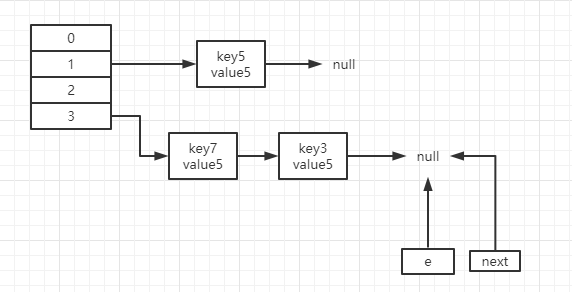
这里我们可以看到,并没有形成环形链表,所以使用尾插法解决了1.7版本在文中分析情况下的环形链表问题。
总结
通过上文的分析,我们解决了前言中提出的两个问题。
- 我们画图分析出1.7版本的形成环形链表的具体情况
- 了解了1.8版本使用的resize的尾插法,可以解决环形链表问题
- 学习了1.8版本针对resize的优化策略