
01 初始MYSQL
02 MYSQL数据管理
数据库 database
用户可以对文件中的数据进行新增、截取、更新、删除等操作
存储大量数据,存储结构便于管理和访问
可以有效保障数据一致性、完整性、降低数据冗余
可以满足应用的共享和安全方面的要求
故障恢复,防止数据被破坏
关系型数据库和非关系型数据库???
nosql=not only sql
1 关系型数据库与非关系型数据库的区别 图解

DBMS数据库关系系统
包括相互联系的数据集合 (数据库)和存取这些数据的一套程序 (数据库管理系统软件)
mySQL、SQL Server 是关系数据库管理系统 (RDBMS)
Mysql 开源免费 小巧

一个SQL语句,如select * from tablename ,从支持接口进来后,进入连接池后做权限、验证等环节,然后判断是否有缓存,有则直接放回结果,否则进入SQL接口,在查询之前查询优化器进行优化,最后进行解析,查询。并通过存储引擎与文件交互
名词解释:
支持接口:不同的编程语言与SQL的交互
连接池:管理缓冲用户连接,线程处理等需要缓存的需求
SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL接口
解析器:SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的;例如将 select * from tablename where 1=1;分解为select、*、from、tablename、where 、1=1,并去解析。
如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的。
查询优化器:SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
例: select uid,name from user where gender = 1;
a.先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
b.先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果。
缓存:
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
存储引擎:
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。
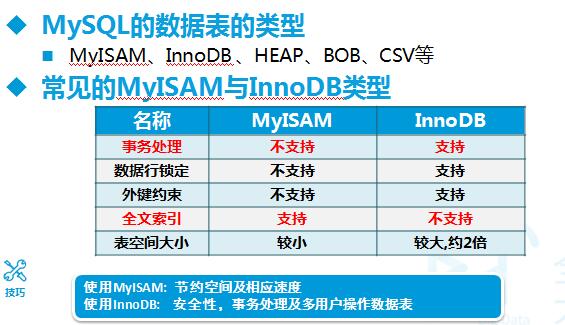
现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的MyISAM,InnoDB,BDB。
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务。
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛。 Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的
mysql的安装:
数据目录不要在系统盘,以免卸载时删除数据包
my.ini
配置环境变量
开启mysql服务
命令行连接数据库:
![]()
DDL:
#创建数据库 CREATE DATABASE [IF NOT EXISTS] 数据库名; #删除数据库 DROP DATABASE [IF EXISTS] 数据库名; #查看数据库 SHOW DATABASES; #使用数据库 USE 数据库名; #建表 CREATE TABLE [ IF NOT EXISTS ] `表名` ( `字段名1` 列类型 [ 属性 ] [ 索引 ] [注释] , --各个属性之间的顺序没有影响 `字段名2` 列类型 [ 属性 ] [ 索引 ] [注释] , … `字段名n` 列类型 [ 属性 ] [ 索引 ] [注释] ) [ 表类型 ] [ 表字符集 ] [注释] ;

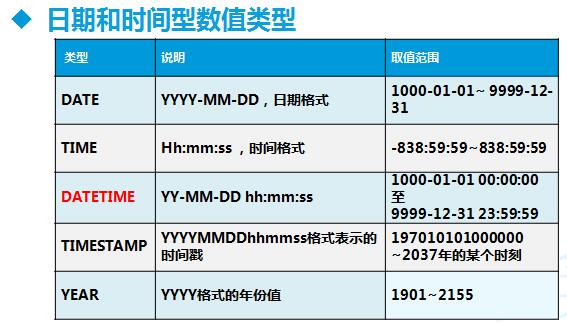
列类型:数值、字符串、日期时间、null



属性:
unsigned 无符号型不允许为负数
zerofill 不足位数用0补充,例如int(3)表示5为005
auto_increment 配合主键使用自增长,可设置步长
not null和null 是否允许为空
default设置默认值
注释:comment
表类型:
引擎 ENGINE = MyISAM
字符集:

#修改表(ALTER TABLE) #修改表名 ALTER TABLE 旧表名 RENAME AS 新表名 #添加字段 ALTER TABLE 表名 ADD 字段名 列类型 [ 属性 ] #修改字段 ALTER TABLE 表名 MODIFY 字段名 列类型 [ 属性 ] ALTER TABLE 表名 CHANGE 旧字段名 新字段名 列类型 [ 属性 ] #删除字段 ALTER TABLE 表名 DROP 字段名 #删除表 DROP TABLE [ IF EXISTS ] 表名
DML:
![]()
insert可同时插入多条记录

![]()
删除:delete和truncate的区别
truncate删除后自增长序列 会从初始值 计数,delete不会
truncate不支持事务

外键:用来约束字表中某个字段的取值
外键 references 父表的字段必须为父表的逐渐

-----------------------------------------------------------------------------------------
插入时可以插入多个值
INSERT into grade VALUES (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班');
修改时可以用自身查出来的值做运算
update student set classHour = classHour + 100;
修改表的引擎engine
alter table subject engine = innode;
表的外键在创建时和修改时的语句
建表时添加外键:
create table student(
studentId int not null,
gradeId int,
foreign key (gradeId) references grade(gradeID)
)
建表后增加外键时:
alter table systudent add foreign key (gradeId) references grade(gradeID);
gradeID必须是grade父表的主键,才可以被用作外键关联
删除外键(外键创建时系统自动取名,删除时使用该名删除):
alter table student drop foreign key 'subject_ibfk_1';

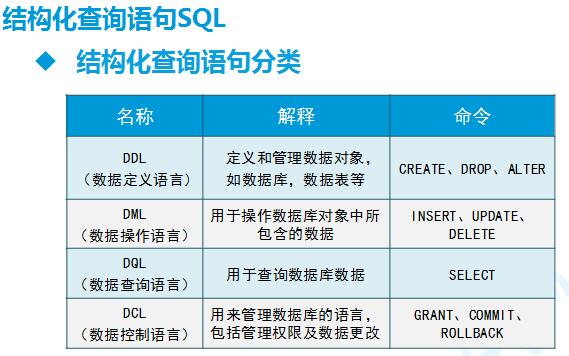
DDL create drop alter
DML insert update delete truncate
navicate保存的sql存放位置:
C:UsersAdministratorDocumentsNavicatMySQLserversjavaXXX
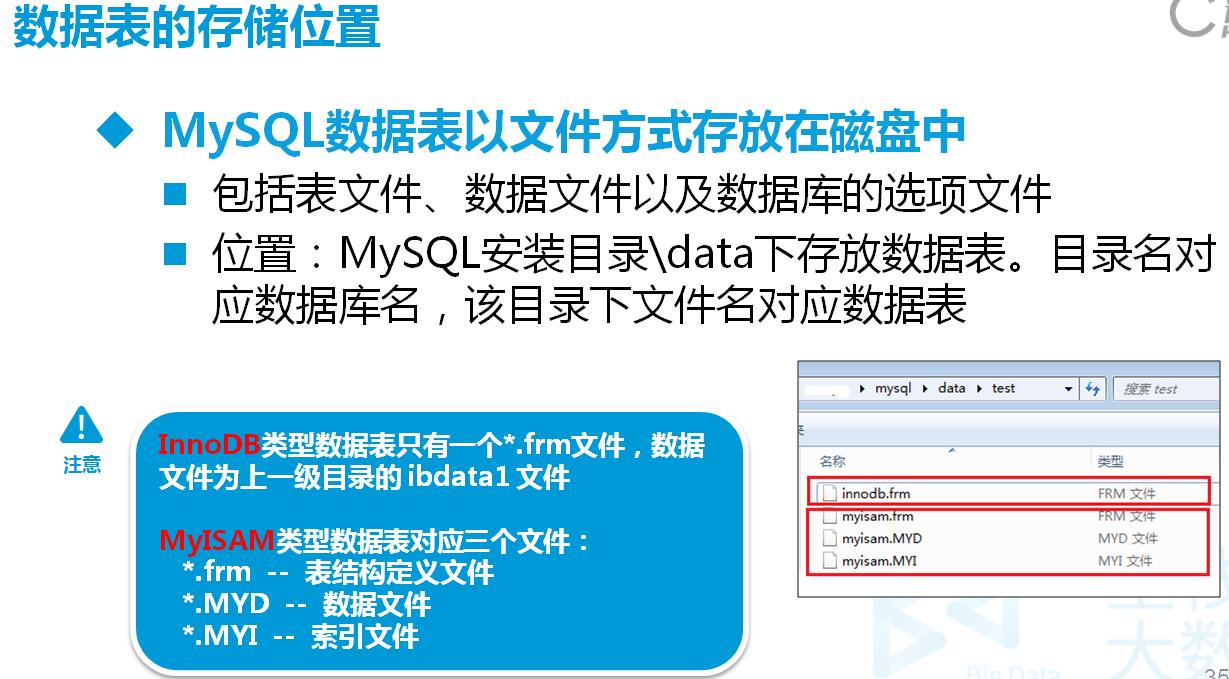
创建的表数据存放位置:
C:ProgramDataMySQLMySQL Server 5.7Datajy81
反引号 是为了防止和关键字冲突,例如 order字段
字段名区分大小写
关键字不区分大小写