需求
读取HDFS中CSV文件的指定列,并对列进行重命名,并保存回HDFS中
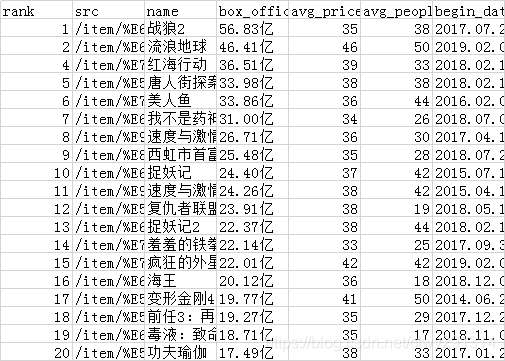
原数据展示
movies.csv
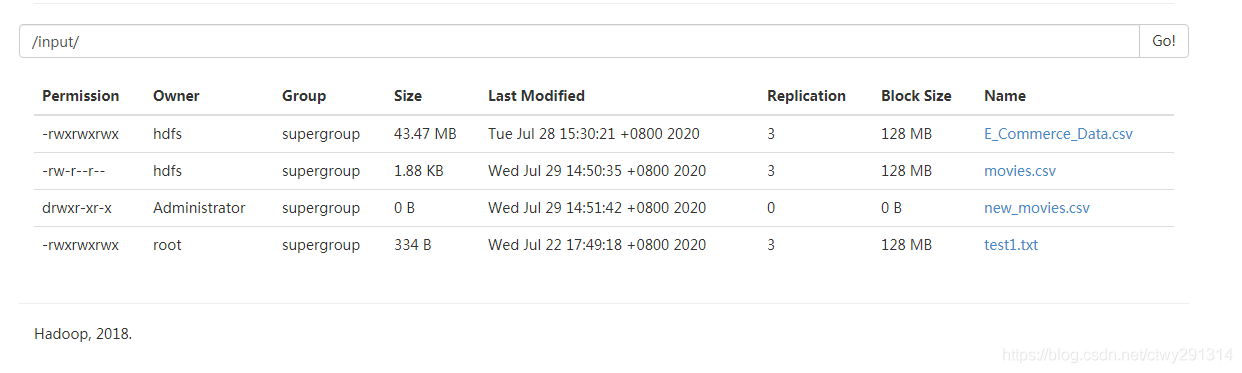
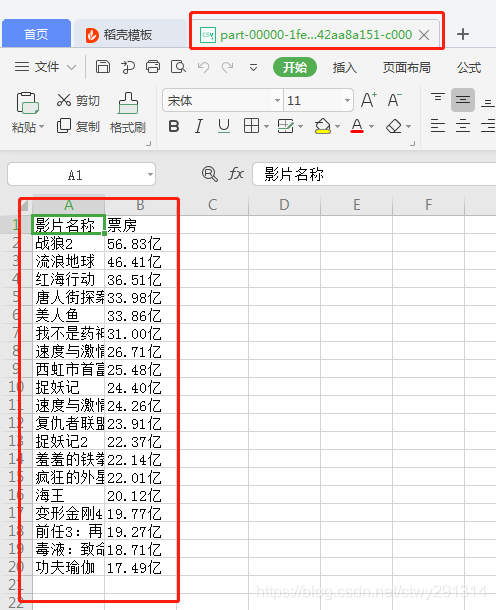
操作后数据展示
注:
write.format()支持输出的格式有 JSON、parquet、JDBC、orc、csv、text等文件格式
save()定义保存的位置,当我们保存成功后可以在保存位置的目录下看到文件,但是这个文件并不是一个文件而是一个目录。
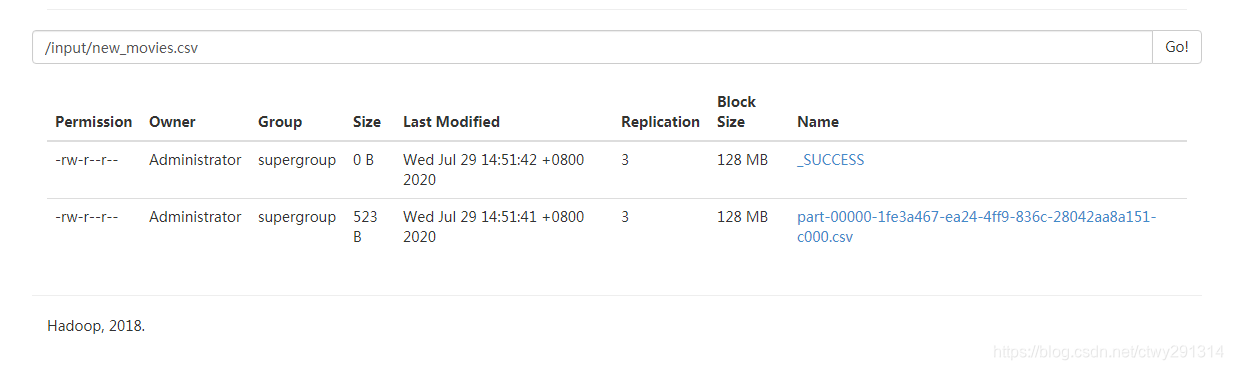
不用担心,这是没错的,我们读取的时候,
并不需要使用文件夹里面的part-xxxx文件,直接读取目录即可。
代码
# -*- coding: utf-8 -*-
from pyspark import SparkContext
from pyspark.sql import SparkSession
import json
import pandas as pd
'''
当需要把Spark DataFrame转换成Pandas DataFrame时,可以调用toPandas();
当需要从Pandas DataFrame创建Spark DataFrame时,可以采用createDataFrame(pandas_df)。
但是,需要注意的是,在调用这些操作之前,
需要首先把Spark的参数spark.sql.execution.arrow.enabled设置为true,
因为这个参数在默认情况下是false
'''
# 所需字段和新老字段映射关系
columns_json_str = '{"name":"影片名称","box_office":"票房"}'
columns_dict = json.loads(columns_json_str)
# 获取spark的上下文
sc = SparkContext('local', 'spark_file_conversion')
sc.setLogLevel('WARN')
spark = SparkSession.builder.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
# 读取本地或HDFS上的文件【.load('hdfs://192.168.3.9:8020/input/movies.csv')】
df = spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('hdfs://192.168.3.9:8020/input/movies.csv')
print(df.dtypes)
# 将spark.dataFrame转为pandas.DataFrame,在此处选取指定的列
df = pd.DataFrame(df.toPandas(),columns=columns_dict.keys())
print(df)
data_values=df.values.tolist()
data_coulumns=list(df.columns)
#将pandas.DataFrame转为spark.dataFrame,需要转数据和列名
df = spark.createDataFrame(data_values,data_coulumns)
# 字段重命名
# df = df.withColumnRenamed('name', '影片名称')
for key in columns_dict.keys() :
df = df.withColumnRenamed(key , columns_dict[key]);
print(df.collect())
print(df.printSchema())
# 将重命名之后的数据写入到文件
filepath = 'new_movies.csv'
df.write.format("csv").options(header='true', inferschema='true').save('hdfs://192.168.3.9:8020/input/' + filepath)