今天我们来使用面部标志和OpenCV 检测和计算视频流中的眨眼次数。
为了构建我们的眨眼检测器,我们将计算一个称为眼睛纵横比(EAR)的指标,由Soukupová和Čech在其2016年的论文“使用面部标志实时眼睛眨眼检测”中介绍。
今天介绍的这个方法与传统的计算眨眼图像处理方法是不同的,使用眼睛的长宽比是更为简洁的解决方案,它涉及到基于眼睛的面部标志之间的距离比例是一个非常简单的计算。
用OpenCV,Python和dlib进行眼睛眨眼检测
我们的眨眼检测实验分为四个部分:
第一步,我们将讨论眼睛的纵横比以及如何用它来确定一个人是否在给定的视频帧中闪烁。
第二步,我们将编写Python,OpenCV和dlib代码来执行面部标志检测和检测视频流中的眨眼。
第三步,基于代码,我们将应用我们的方法来检测示例摄像头流中的眨眼以及视频文件。
最后,我将通过讨论改进我们的眨眼检测器的方法来结束。
1.了解“眼睛纵横比”(EAR)
我们可以应用面部标志检测来定位脸部的重要区域,包括眼睛,眉毛,鼻子,耳朵和嘴巴:
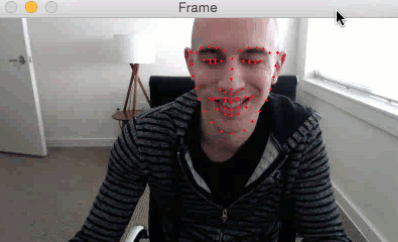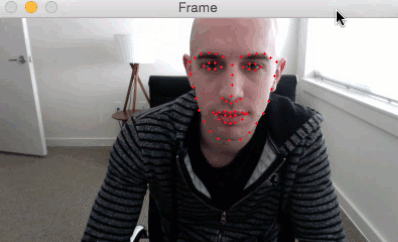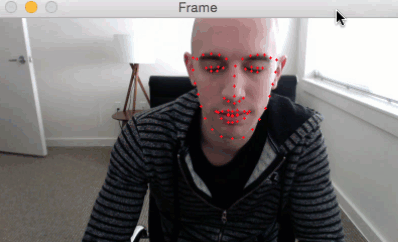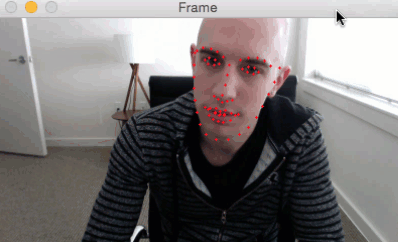
这也意味着我们可以通过了解特定脸部的索引来提取特定的脸部结构:

在眨眼检测方面,我们眼睛结构感兴趣。
每只眼睛由6个(x,y)坐标表示,从眼睛的左角开始,然后围绕该区域的其余部分顺时针显示:

基于这个描述,我们应该抓住重点:这些坐标的宽度和高度之间有一个关系。
Soukupová和Čech在其2016年的论文“使用面部标志实时眼睛眨眼检测”的工作,我们可以推导出反映这种关系的方程,称为眼睛纵横比(EAR):
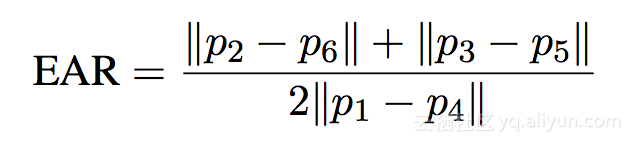
其中p1,...,p6是2D面部地标位置。
这个方程的分子是计算垂直眼睛标志之间的距离,而分母是计算水平眼睛标志之间的距离,因为只有一组水平点,但是有两组垂直点,所以进行加权分母。
为什么这个方程如此有趣?
我们将会发现,眼睛的长宽比在眼睛张开的时候大致是恒定的,但是在发生眨眼时会迅速下降到零。
使用这个简单的方程,我们可以避免使用图像处理技术,简单地依靠眼睛地标距离的比例来确定一个人是否眨眼。
为了更清楚地说明,看下面的图:
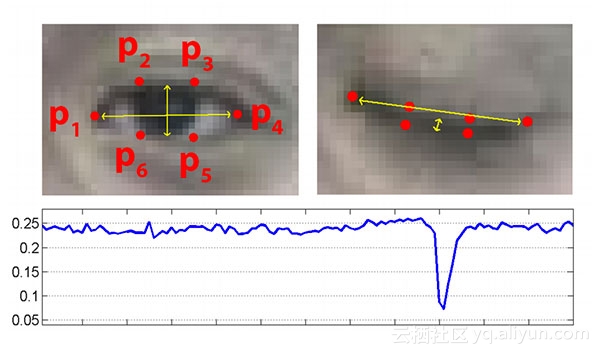
在底部图中绘出了眼纵横比随时间的视频剪辑的曲线图。正如我们所看到的,眼睛纵横比是恒定的,然后迅速下降到接近零,然后再增加,表明一个单一的眨眼已经发生。
2.用面部标志和OpenCV检测眨眼(代码篇)
请打开一个新文件并将其命名为detect_blinks.py。插入以下代码:
# import the necessary packages
from scipy.spatial import distance as dist
from imutils.video import FileVideoStream
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np
import argparse
import imutils
import time
import dlib
import cv2
要访问磁盘上的视频文件(FileVideoStream)或内置的网络摄像头/ USB摄像头/Raspberry Pi摄像头模块(VideoStream),我们需要使用imutils库,它可以使OpenCV更容易工作。
如果您的系统上没有安装 imutils,请确保使用以下命令安装/升级:
pip install --upgrade imutils
注意:如果您正在使用Python虚拟环境(OpenCV安装教程),请确保使用 workon命令首先访问您的虚拟环境,然后安装/升级 imutils。
例外的是dlib库,如果您的系统上没有安装dlib,请按照我的dlib安装教程配置您的机器。
接下来,我们将定义eye_aspect_ratio函数:
def eye_aspect_ratio(eye):
# compute the euclidean distances between the two sets of
# vertical eye landmarks (x, y)-coordinates
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# compute the euclidean distance between the horizontal
# eye landmark (x, y)-coordinates
C = dist.euclidean(eye[0], eye[3])
# compute the eye aspect ratio
ear = (A + B) / (2.0 * C)
# return the eye aspect ratio
return ear
这个函数接受单一的参数,即给定的眼睛面部标志的(x,y)坐标 。
A,B是计算两组垂直眼睛标志之间的距离,而C是计算水平眼睛标志之间的距离。
最后,将分子和分母相结合,得出最终的眼睛纵横比。然后将眼图长宽比返回给调用函数。
让我们继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-v", "--video", type=str, default="",
help="path to input video file")
args = vars(ap.parse_args())
detect_blinks.py脚本需要一个命令行参数,然后第二个是可选的参数:
1.--shape-predictor:这是dlib的预训练面部标志检测器的路径。
2.--video:它控制驻留在磁盘上的输入视频文件的路径。如果您想要使用实时视频流,则需在执行脚本时省略此开关。
我们现在需要设置两个重要的常量,您可能需要调整实现,并初始化其他两个重要的变量。
# define two constants, one for the eye aspect ratio to indicate
# blink and then a second constant for the number of consecutive
# frames the eye must be below the threshold
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
# initialize the frame counters and the total number of blinks
COUNTER = 0
TOTAL = 0
当确定视频流中是否发生眨眼时,我们需要计算眼睛的长宽比。
如果眼睛长宽比低于一定的阈值,然后超过阈值,那么我们将记录一个“眨眼” -EYE_AR_THRESH是这个阈值,我们默认它的值为 0.3,您也可以为自己的应用程序调整它。另外,我们有一个重要的常量,EYE_AR_CONSEC_FRAME,这个值被设置为 3,表明眼睛长宽比小于3时,接着三个连续的帧一定发生眨眼动作。
同样,取决于视频的帧处理吞吐率,您可能需要提高或降低此数字以供您自己实施。
接着初始化两个计数器,COUNTER是眼图长宽比小于EYE_AR_THRESH的连续帧的总数,而 TOTAL则是脚本运行时发生的眨眼的总次数。
现在我们的输入,命令行参数和常量都已经写好了,接着可以初始化dlib的人脸检测器和面部标志检测器:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
dlib库使用一个预先训练的人脸检测器,该检测器基于对用于对象检测的定向梯度直方图+线性SVM方法的修改。然后,我们初始化的实际面部标志预测值predictor。
您可以在本博客文章中了解更多关于dlib的面部标志性探测器(即它是如何工作的,它在哪些数据集上进行了训练等)。
由dlib生成的面部标记遵循可索引列表,正如我所描述的那样:

因此,我们可以确定为下面的左眼和右眼提取(x,y)坐标的起始和结束数组切片索引值:
# grab the indexes of the facial landmarks for the left and
# right eye, respectively
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
使用这些索引,我们将能够毫不费力地提取眼部区域。
接下来,我们需要决定是否使用基于文件的视频流或实时USB/网络摄像头/ Raspberry Pi摄像头视频流:
# start the video stream thread
print("[INFO] starting video stream thread...")
vs = FileVideoStream(args["video"]).start()
fileStream = True
# vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
# fileStream = False
time.sleep(1.0)
如果您使用的是文件视频流,请保持原样。
如果您想使用内置摄像头或USB摄像头,取消注释:# vs = VideoStream(src=0).start()。
Raspberry Pi相机模块,取消注释:# vs = VideoStream(usePiCamera=True).start()。
如果您未注释上述两个,你可以取消注释# fileStream = False以及以表明你是不是从磁盘读取视频文件。
最后,我们已经完成了我们脚本的主要循环:
# loop over frames from the video stream
while True:
# if this is a file video stream, then we need to check if
# there any more frames left in the buffer to process
if fileStream and not vs.more():
break
# grab the frame from the threaded video file stream, resize
# it, and convert it to grayscale
# channels)
frame = vs.read()
frame = imutils.resize(frame, width=450)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
在while处我们开始从视频流循环帧。
如果我们正在访问视频文件流,并且视频中没有剩余的帧,我们从循环中断。
从我们的视频流中读取下一帧,然后调整大小并将其转换为灰度。然后,我们通过dlib内置的人脸检测器检测灰度帧中的人脸。
我们现在需要遍历帧中的每个面,然后对其中的每个面应用面部标志检测:
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# extract the left and right eye coordinates, then use the
# coordinates to compute the eye aspect ratio for both eyes
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# average the eye aspect ratio together for both eyes
ear = (leftEAR + rightEAR) / 2.0
shape确定面部区域的面部标志,接着将这些(x,y)坐标转换成NumPy阵列。
使用我们之前在这个脚本中的数组切片技术,我们可以分别为左眼left eye和右眼提取(x,y)坐标,然后我们计算每只眼睛的眼睛长宽比 。
下一个代码块简单地处理可视化眼部区域的面部标志:
# compute the convex hull for the left and right eye, then
# visualize each of the eyes
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
我们已经计算了我们的(平均的)眼睛长宽比,但是我们并没有真正确定是否发生了眨眼,这在下一部分中将得到关注:
# check to see if the eye aspect ratio is below the blink
# threshold, and if so, increment the blink frame counter
if ear < EYE_AR_THRESH:
COUNTER += 1
# otherwise, the eye aspect ratio is not below the blink
# threshold
else:
# if the eyes were closed for a sufficient number of
# then increment the total number of blinks
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# reset the eye frame counter
COUNTER = 0
第一步检查眼睛纵横比是否低于我们的眨眼阈值,如果是,我们递增指示正在发生眨眼的连续帧数。否则,我们将处理眼高宽比不低于眨眼阈值的情况,我们对其进行检查,看看是否有足够数量的连续帧包含低于我们预先定义的阈值的眨眼率。如果检查通过,我们增加总的闪烁次数。然后我们重新设置连续闪烁次数 COUNTER。
我们的最终代码块只是简单地处理在输出帧上绘制闪烁的次数,以及显示当前的眼图高宽比:
# draw the total number of blinks on the frame along with
# the computed eye aspect ratio for the frame
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
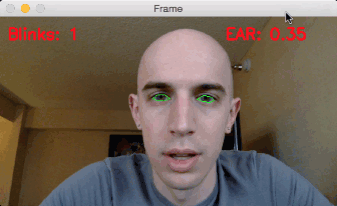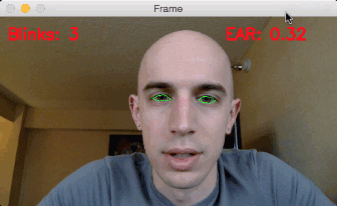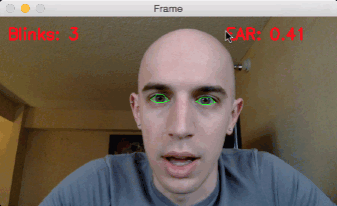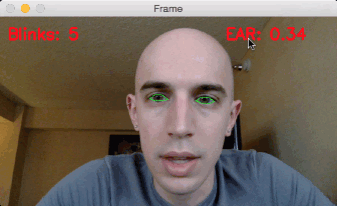
3.眨眼检测结果
在执行之前,请务必使用本指南“下载”源代码+示例视频+预训练的dlib面部标记预测器。
要将我们的眨眼检测器应用于示例视频,只需执行以下命令:
$python detect_blinks.py
--shape-predictor shape_predictor_68_face_landmarks.dat
--video blink_detection_demo.mp4
后来,在旅馆里,我记录下了眨眼检测器的实时流,并将其变成了屏幕录像。
要访问我的内置摄像头,我执行了下面的命令(注意取消注释正确的VideoStream类,如上所述):
$python detect_blinks.py
--shape-predictor shape_predictor_68_face_landmarks.dat
4.改进我们的眨眼检测器
我们只关注眼睛纵横比作为定量指标,以确定一个人是否在视频流中眨了眨眼睛。
为了使我们的眨眼检测器更加强大的显示中可能挑战,Soukupová和Čech建议:为了改善我们的眨眼检测器,Soukupová和Čech建议构建眼长宽比(第N帧,第 N-6 帧和第 N + 6帧)的13维特征向量,然后将该特征向量馈送到线性SVM分类。
如果你有什么问题,可以查看原文,在评论区与作者交流,作者是一个热心肠的人。