粗略一算,不写code已经好几个月了.
昨日受兄弟所托,为他写了一个小小的程序.
程序功能:
自动获取跳转后的Url地址
如下图所示:
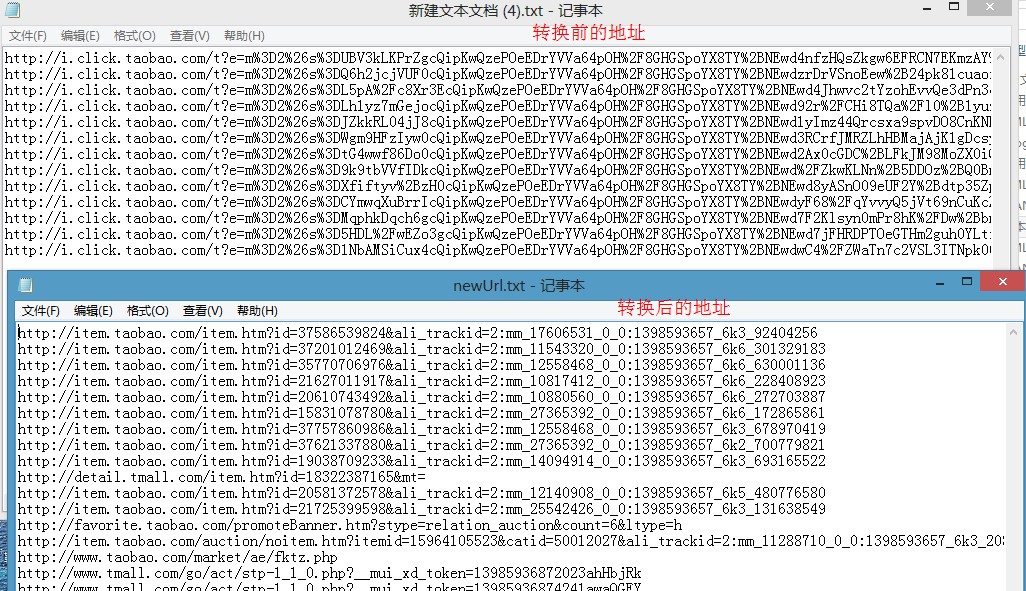
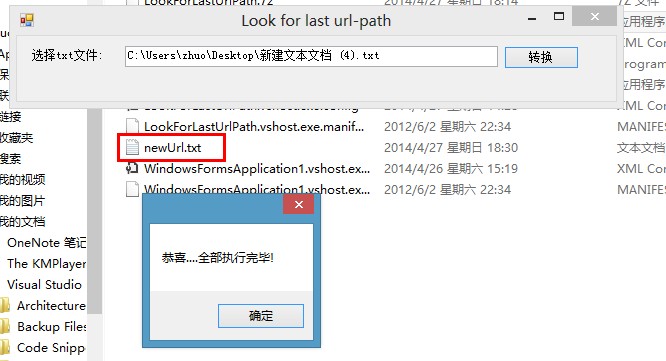
(newUrl.txt为转换后的地址信息...)
实现过程:
每读一行数据,就new了一个webbrowser,然后指定其url,接着,在文档加载完毕之后,获取起url地址(则为最终地址).
优点:没有...用来滥竽充数的..
缺点:
1.webbrowser很吃内存.我只是随便测试200条数据,就吃了我几G内存.
2.用的是winform,本人的系统为win8,装的是vs2012,使用的是4.0,所以,其他的小伙伴要用的话,得先安装
Microsoft .NET Framework 4
下载地址:http://www.microsoft.com/zh-cn/download/details.aspx?id=17718
使用帮助:个人觉得,如果数据量大的话,分成100条次来处理比较好.处理完毕之后,关掉程序再继续..
最后,直接给出百度云盘的分享地址就好了.代码丑陋,不敢拿出来.
http://pan.baidu.com/s/1kTKAR23