编程到底难在哪里呢?编程语言的语法复杂?业务逻辑复杂?可能都存在吧!不过就我自身的感受是编写多线程高并发相关的代码,以及编写网络通信的代码是比较复杂的,学习过c/c++不过我主要使用java编程,猜测管理系统内存直接和OS打交道的部分也应该是比较复杂的。如果没有多线程高并发编程,也不需要编写多进程之间通信的编程,我想编程可能就会轻松许多了。那问题来了,为啥会有进程、线程的存在呢?我认为计算机编程技术的复杂性的根源就在于这三个字——速度差。
同样话不读多少,先上一个图看一下!
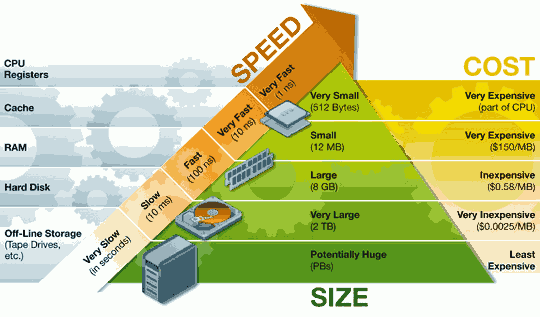
从上图中我们能感受到CPU和数据存储设备的速度差是多么的悬殊,人类在各个方面对于性能的追求总是孜孜不倦的,因为更快代表着更强或者能更早的获取到机会争取到利益。
计算机核心的功能在于计算,最早是人肉输入信息让计算机来计算,不过人和计算机在速度上比,人绝对是智障。当然,人脑也是极易输入错误的,所以,就将相应的输入程序及数据先写好放到硬盘,到时候计算器直接从硬盘上读取就行了,不过硬盘太慢了CPU难以忍受,所以,为了更快的读取速度,就加上了内存,可是内存相对CPU还是慢的不行,后来又加上了L1/L2/L3三级缓存,这样总算是基本赶上CPU的速度了。解决了速度匹配的问题,但是引入了其他的问题,比如:内存及缓存空间比较小,所需数据比较多,命中不到还是需要从磁盘一级一级的把数据倒腾过来,计算的数据也同样需要一层层的在写回磁盘。磁盘——内存——L3——L2——L1——CPU之间还是存在速度差的,存在速度差就又快又慢就存在等待,存在等待就存在干的快的有空闲。为了不让CPU空闲,于是产生了多进程,不过多进程的上下文切换太重了,于是又有了线程,线程间是共享进程的公共内存空间的,多个线程对同一块内存地址都可以有写操作,于是就产生了多线程并非编程导致数据不一致性的问题。为了解决这个问题有引入了锁机制以及内存操作的管理模型,这样下来原本简单的编程就变得复杂了起来。
我认为单机编程的复杂性就在这里了,引起这个复杂性的根源就是——数据存储设备运输数据到计算设备的速度差导致的。如果仔细来好好分析,几乎所有的技术,都在是想方设法绞尽脑汁的在通过各种方法来解决这个问题的。比如:数据库的索引,内存数据库,零拷贝,线程池,单例模式,异步编程,事件驱动模型,日志追加写,数据先放入内存在一级一级的放入对应的缓存等等。