一、匹配分组
| 字符 | 功能 |
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中的字符作为一个分组 |
| um | 引用分组num匹配到的字符串 |
| (?<name>) | 分组起别名 |
| (k<name>) | 引用别名为name分组匹配到的字符串 |
1、|
需求:匹配出0-100之间的数字
分析:首先我们明确这之间的数字包含0,两位数,100,也就是一位,两位,三位的可能都有,鉴于一位0,三位100都是单独数字,我们可以使用 | 来连接(相当于or),着重考虑一位数[1-9],两位数[10-99],分析其特征,这里第一位数必须为[1-9],第二位[0-9]都可以(d可以表示),对于一位数[1-9]的第二位可以不出现(?可以表示),再加个结尾$,防止234匹配到23的情况。因此正则表达式为:
/^[1-9]d?$|0$|100$/
2、(ab) 将括号中的字符作为一个分组
需求 :在网页开发或者爬虫时,处理对象是HTML,比如某网页HTML中有这样的内容:<h1>我的CSDN</h1>。那么我该如何把<h1>content</h1>中的content提取出来呢?
分析:提取的内容用 () 括起来就可以了。<h1> </h1>是固定标签,这是不变的,变的是content,因此我的正则表达式可表示为:
/<h1>(.*)</h1>/
let res = /<h1>(.*)</h1>/
'<h1>我的博客</h1>'.match(res)
// (2) ["<h1>我的博客</h1>", "我的博客", index: 0, input: "<h1>我的博客</h1>", groups: undefined]
// 0: "<h1>我的博客</h1>"
// 1: "我的博客"
// groups: undefined
// index: 0
// input: "<h1>我的博客</h1>"
// length: 2
我们看看两个括号的情况:
let res = /<span>(d+)</span><h1>(.*)</h1>/
'<span>1234</span><h1>我的CSDN</h1>'.match(res)
// (3) ["<span>1234</span><h1>我的CSDN</h1>", "1234", "我的CSDN",
index: 0, input: "<span>1234</span><h1>我的CSDN</h1>", groups: undefined]
获取元素为3个的数组,就不多展开了,根据数组内容就可以很方便的获取到需要的content的内容。
所以说,() 在网页开发或爬虫里还是挺重要的。
3、 um 引用分组num匹配到的字符串
需求 :还是以网页为例,比如判断某网页HTML格式是否正确,其中有内容:<html><h1>我的CSDN</h1></html>。这时,我们不关心里面的内容,我们关心的是格式是否正确,就是说这样的格式:<html>标签必须有</html>结束,<h1>标签必须有</h1>结束。
分析:这个时候像html和h1才是关键内容,如果我们把这些用()保存起来,并且在后面一定对应这些内容,就能保证标签的配对,而 um就是解决这样的问题的。
首先我们看个错误的样例:
let res = /<.+><.+>.+</.+></.+>/
'<html><h1>my csdn</h1></html>'.match(res)
// ["<html><h1>my csdn</h1></html>", index: 0, input: "<html><h1>my csdn</h1></html>", groups: undefined]
let res = /<.+><.+>.+</.+></.+>/
'<html><h1>my csdn</h1></ht>'.match(res)
// ["<html><h1>my csdn</h1></ht>", index: 0, input: "<html><h1>my csdn</h1></ht>", groups: undefined]
我们把/html改成了/ht 明显格式不对,但还是匹配了。我们应该让第一个<tag>的内容出现在最后</tag>中,因此需要保存起来,用()括起来
正确的方法:我们应该把<tag>用()括起来,变成<(tag)>,因此正则表达式为:
/<(.+)><(.+)>.+</2></1>/
let res = /<(.+)><(.+)>.+</2></1>/
'<html><h1>my csdn</h1></ht>'.match(res)
// null
let res = /<(.+)><(.+)>.+</2></1>/
'<html><h1>my csdn</h1></html>'.match(res)
// (3) ["<html><h1>my csdn</h1></html>", "html", "h1",
index: 0, input: "<html><h1>my csdn</h1></html>", groups: undefined]
解释下,这个2 和 1。这个就是对应(tag)的分组,可以通过下面的index内容获取。上面正确的标签,那么 1指的就是html,2 指的就是h1
4、(?<name>) 分组起别名 和 (k<name>) 引用别名
需求 :上面我们已经可以通过 um取得对应的内容用以限定前面的内容,但是如果我有100个括号,那我们就只能数括号的索引index,然后把用index取得么?答案:当然不是。
分析:这时候取别名(?<name>)就派上用场了,它通过对括号里的内容取别名,然后通过(k<name>)就可以取得对应的内容,你只要记住别名name,这样就不用去数括号,记索引了。是不是很人性化......
这个语法是:在括号里面同时写上取的别名,以 ?<name> 命名;引用时以 k<name> 取得别名,所以该正则表达式为:
/<(?<key1>.+)><(?<key2>.+)>.+</(k<key2>)></(k<key1>)>/
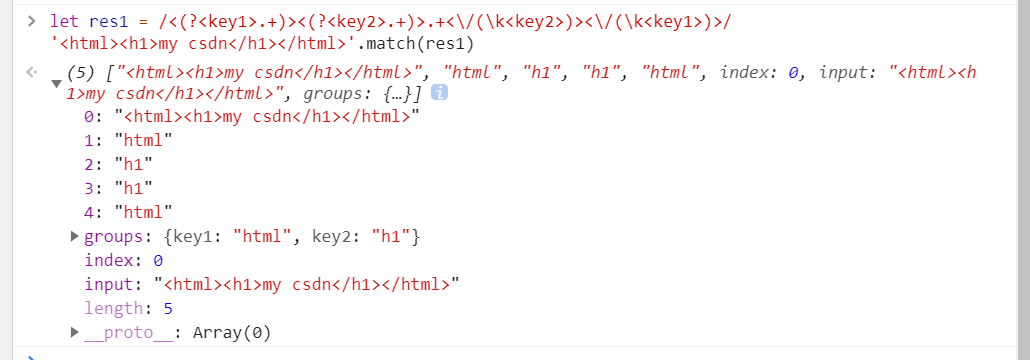
let res1 = /<(?<key1>.+)><(?<key2>.+)>.+</(k<key2>)></(k<key1>)>/
'<html><h1>my csdn</h1></html>'.match(res1)
// (5) ["<html><h1>my csdn</h1></html>", "html", "h1", "h1", "html",
index: 0, input: "<html><h1>my csdn</h1></html>", groups: {…}]
0: "<html><h1>my csdn</h1></html>"
1: "html"
2: "h1"
3: "h1"
4: "html"
groups:
key1: "html"
key2: "h1"
index: 0
input: "<html><h1>my csdn</h1></html>"
length: 5
__proto__: Array(0)
关于正则分组别名,详细的可以看之前总结的这篇博客:JavaScript 正则命名分组