最近在做分布式模型实现时,使用到了这个函数. 可以说非常体验非常的好. 速度非常快,效果和softmax差不多.
我们知道softmax在求解的时候,它的时间复杂度和我们的词表总量V一样O(V),是性线性的,从它的函数方程式中,我们也可以很容易得出:
softmax:
f(x) = e^x / sum( e^x_i ) ;
它的需要对所有的词 e^x 求和; 所以当V非常大的时候,哪怕时间复杂度是O(V),这个求解的过程耗时也比较“严重”;
设想一下,当我们在训练模型时, 我们知道目标词x,但是我们却需要去求解所有的词,并求和。
当然,有很多去研究如何优化这一过程,提出过各种各样的设想,其中 Hierarchical softmax 就是其中璀璨的一种。
那么说道这,什么是 Hierarchical softmax ?
形如:
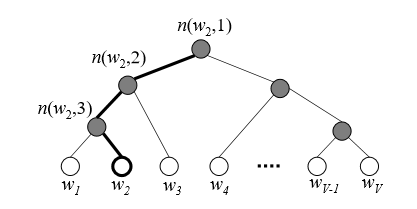
我们去构造一棵这样的树,这不是一般的二叉树,是依据训练样本数据中的单词出现的频率,构建起来的一棵Huffman tree ,频率越高,
节点越短.
当我们构造了这样之后,如下:
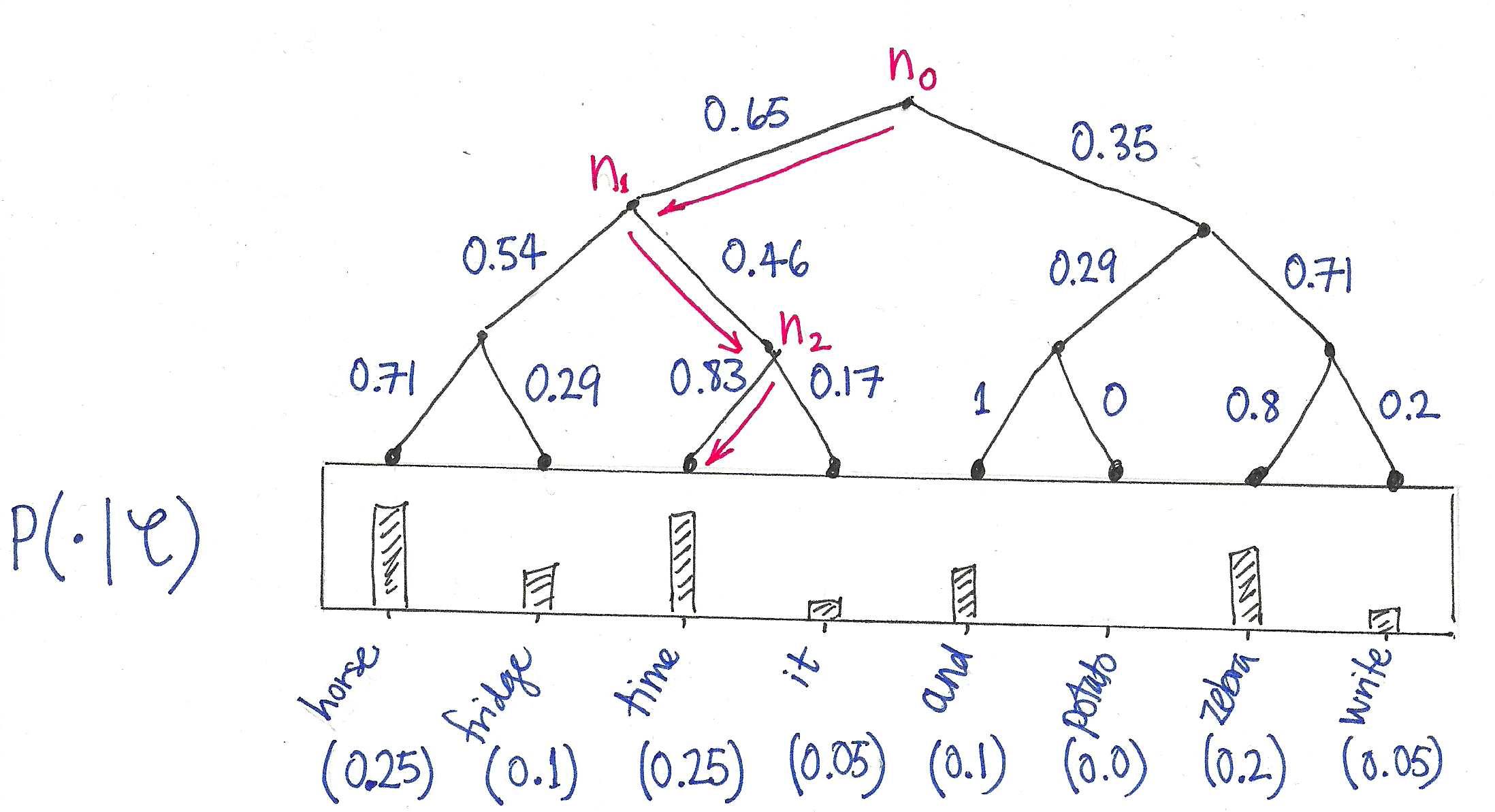
我们发现对于每一个节点,都是一个二分类[0,1],也就是我们可以使用sigmod来处理节点信息;
sigmod函数如下:
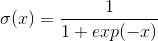 ,
,
此时,当我们知道了目标单词x,之后,我们只需要计算root节点,到该词的路径累乘,即可. 不需要去遍历所有的节点信息,时间复杂度变为O(log2(V))
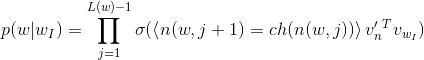
【参考资料】:
1. https://towardsdatascience.com/hierarchical-softmax-and-negative-sampling-short-notes-worth-telling-2672010dbe08
2.http://building-babylon.net/2017/08/01/hierarchical-softmax/