腾讯2014校园招聘笔试试题
欢迎以正常的心态来,浏览这里的共享的知识!,也欢迎吐槽!指点一二!
1 已知一颗二叉树,如果先序遍历的节点顺序是:ADCEFGHB ,中序遍历是:CDFEGHAB ,则后续遍历的结果为:
A. CFHGEBDA B. CDFEGHBA C. FGHCDEBA D. CFHGEDBA
分析:
考点, 树的遍历 , 先序 ,中序 ,后序 。各种遍历..
(1) . 前序遍历,也叫先根遍历,遍历的顺序是,根,左子树,右子树。
(2) . 中序遍历 , 也叫中根遍历,顺序是 左子树,根,右子树。
(3) . 后序遍历,也叫后根遍历,遍历顺序,左子树,右子树,根。

于是乎,不难得出....后序遍历:CFHGEDBA ,因而答案选择: D
2. 下列哪两个数据结构,同时具有较高的查找和删除性能: ___________
A. 有序数组 , B . 有序链表 , C AVL树 , D. Hash表
分析: 下面是几种数据结构查找与删除的性能对照表:
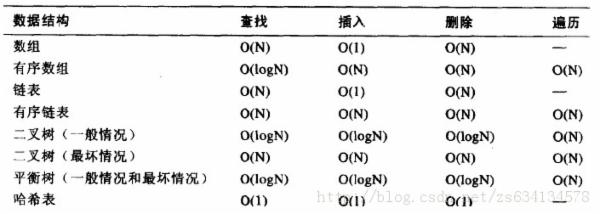
其实不用上诉资料,自己也应该清楚:
有序数组 ,有序链表 ,遍历来查找和删除。 时间复杂度为O(n);
平衡树: 采用二分的技术查找,以及Hash表,有特定的算法构成,位置都比较明显的定位
因而答案很定为: CD
3 下列排序算法中,哪些时间复杂度不会超过nlogn?()
A.快速排序 B.堆排序 C.归并排序 D.冒泡排序
分析:
冒泡的 复杂度为 O(n^2)
快速排序: 平均是O(nlogn) 最坏为 O(n^2)
归并排序: O(nlogn)
堆排序: O(nlogn)
因而答案为: BC
4 初始序列为1 8 6 2 5 4 7 3一组数采用堆排序,当建堆(小根堆)完毕时,堆所对应的二叉树中序遍历序列为:(A)
A.8 3 2 5 1 6 4 7 B.3 2 8 5 1 4 6 7
C.3 8 2 5 1 6 7 4 D.8 2 3 5 1 4 7 6
分析: 涉及到最大堆和最小堆 ,以及二叉树的遍历
对于最小堆,其实就是----------头小,根大
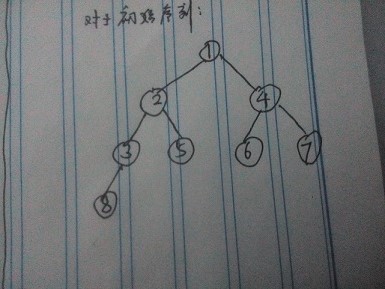
由这样一颗树: 不难得到后序序列: 83526741 因而答案为: A
5 当n=5时,下列函数的返回值是:( )
- int foo(int n)
- {
- if(n<2)return n;
- return foo(n-1)+foo(n-2);
- }
A.5 B.7 C.8 D.10
分析: 简单的递归:
很容易写出表达是:

答案选: A
6 S市A,B共有两个区,人口比例为3:5,据历史统计A的犯罪率为0.01%,B区为0.015%,现有一起新案件发生在S市,那么案件发生在A区的可能性有多大?( )
A.37.5% B.32.5% C.28.6% D.26.1%
分析:
S{ A , B } ,一个案件的发生,要么在A,要么在B, 一句概率论:
(1) P(A)+P(B)=1;
于是乎,答案为: ( (3/8)*0.01% )/( (3/8)*0.01% +(5/8)*0.015%) *100% = 28.6% 答案为 C
7 Unix系统中,哪些可以用于进程间的通信?(ABCD)
A.Socket B.共享内存 C.消息队列 D.信号量
socket 为线程部分是进程的一个单位,可以。
然后看了下资料:
3种System V进程通信方式:信号量,消息队列和共享内存
8 静态变量通常存储在进程哪个区?(C)
A.栈区 B.堆区 C.全局区 D.代码区
静态变量的修饰关键字:static,又称静态全局变量。
静态变量属于静态存储方式,但是属于静态存储方式的变量不一定就是静态变量。
全局区在内存中所占的位置:

9 查询性能(B)
A . 在Name字段上添加主键
B . 在Name字段上添加索引
C. 在Age字段上添加主键
D. 在Age字段上添加索引
分析: 考查数据库,优化部分:
索引:对数据库表中一列或多列的值进行排序(或构成特定的数据结构,如树或哈希表)的一种结构,使用索引可快速访问数据库表中的特定信息。
优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度
- 可以加快表与表之间的连接
- 使用分组和排序子句进行检索时,同样可以显著减少查询中分组和排序的事件
- 在查询的过程中优化隐藏器,提高系统的性能
缺点:
- 创建和维护所以你需要耗费时间
- 索引需要占物理空间,如果建立聚簇索引,需要的空间更大
- 表的数据更新时,索引也要动态的维护
建立索引的规则:
- 表的主键、外键必须有索引;
- 数据量超过300的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上;
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
- 复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
- 正确选择复合索引中的主列字段,一般是选择性较好的字段;
- 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
- 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
- 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
- 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
- 频繁进行数据操作的表,不要建立太多的索引;
- 删除无用的索引,避免对执行计划造成负面影响;
答案:B
10 IP地址131.153.12.71是一个()类IP地址。
A.A B.B C.C D.D
解析:
IP地址分类
A类网络的IP地址范围为 1.0.0.1-127.255.255.254;
B类网络的IP地址范围为:128.1.0.1-191.255.255.254;
C类网络的IP地址范围为:192.0.1.1-223.255.255.254。
答案: B
附上一张图:

12 下列程序的输出是:()
#define add(a+b) a+b
int main()
{
printf(“%d ”,5*add(3+4));
return 0;
}
A.23 B.35 C.16 D.19
分析:
简单题: 对于这样一条语句这样做就好了 5*add(3+4) = 5*3+4=19; 选:D
13 浏览器访问某页面,HTTP协议返回状态码为403时表示:(B)
A 找不到该页面 ---404
B 禁止访问 ---403
C 内部服务器访问 --500
D 服务器繁忙 ----503
转来的一张HTTP状态吗:

14 如果某系统15*4=112成立,则系统采用的是()进制。
A.6 B.7 C.8 D.9
由于这是一个选择题,那么题目就较为简单了,首先我们不难得到15*4 =60(十进制数)
如果是6进制: 15*4= 112 ={(6+5)*4= 1*6^2+1*6+2 =44 } 对
答案为:A
15 某段文本中各个字母出现的频率分别是{a:4,b:3,o:12,h:7,i:10},使用哈夫曼编码,则哪种是可能的编码:(A)
A a(000) b(001) h(01) i(10) o(11)
B a(0000) b(0001) h(001) o(01) i(1)
C a(000) b(001) h(01) i(10) o(00)
D a(0000) b(0001) h(001) o(000) i(1)
分析:
首先,考查huffman树---> 最优二叉树 ,写出了huffman树,我们不难得到huffman编码
因此 , 
16 TCP和IP分别对应了OSI中的哪几层?()
A Application layer ----- 应用层
B Presentation layer ------表示层
C Transport layer ------传输层
D Network layer -------网络层
介于于 传输层和网络层
答案: CD

17 一个栈的入栈序列是A,B,C,D,E,则栈的不可能的输出序列是?()
A.EDCBA B.DECBA C.DCEAB D.ABCDE
分析: 简单的先进后出(栈) ,这里就省去吧! C
18 同一进程下的线程可以共享以下?(BD)
A. stack B.data section C.register set D.file fd
解析: 这道题,不知道怎么下手.....嗷嗷的哭去....
线程共享的内容包括:
- 进程代码段
- 进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、
- 进程打开的文件描述符、
- 信号的处理器、
- 进程的当前目录和
- 进程用户ID与进程组ID
线程独有的内容包括:
- 线程ID
- 寄存器组的值
- 线程的堆栈
- 错误返回码
- 线程的信号屏蔽码
19 对于派生类的构造函数,在定义对象时构造函数的执行顺序为?()
1:成员对象的构造函数
2:基类的构造函数
3:派生类本身的构造函数
A.123 B.231 C.321 D.213
分析:
(C++)西加加的内容:
----》2 1 3 答案: D
别人家的解析:
当派生类中不含对象成员时
- 在创建派生类对象时,构造函数的执行顺序是:基类的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函数的执行顺序是:派生类的构造函数→基类的构造函数。
当派生类中含有对象成员时
- 在定义派生类对象时,构造函数的执行顺序:基类的构造函数→对象成员的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函数的执行顺序:派生类的构造函数→对象成员的构造函数→基类的构造函数。
21 递归函数最终会结束,那么这个函数一定?()
A 使用了局部变量
B 有一个分支不调用自身
C 使用了全局变量或者使用了一个或多个参数
D 没有循环调用
依据多年的调试代码经验 ,答案: B
22 编译过程中,语法分析器的任务是()
A 分析单词是怎样构成的
B 分析单词串是如何构成语言和说明的
C 分析语句和说明是如何构成程序的
D 分析程序的结构
答案: B
/--------------------------------------------------------------------------------------------------------------------------/
23 同步机制应该遵循哪些基本准则?(ABCD)
A.空闲让进 B.忙则等待 C.有限等待 D.让权等待
解析: 不知道怎么做,就看看别人家的解释吧!
同步机制应该遵循的基本准则
- 空闲让进:当无进程处于临界区时,表明临界资源处于空闲状态,允许一个请求进入临界区的进程立即进入临界区,以有效利用临界资源
- 忙则等待:当已有进程处于临界区时,表明临界资源正在被访问,因而其他试图进入临界区的进程必须等待,以保证对临界资源的互斥访问
- 有限等待:对要求访问临界资源的进程,应保证在有限时间内能进入自己的临界区,以免陷入“死等”状态
- 让权等待:当进程不能进入自己的临界区时,应立即释放处理机,以免进程陷入“忙等”状态