HashMap工作原理及什么时候用到的红黑树:
在jdk 1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
在jdk 1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
原理:数组中的每一个元素所在的位置相当于一个位桶,添加元素的时候,首先计算元素key的hash值,确定插入数组中的位置(也就是哪个桶中),如果存在相同的hash值,则放在同一个桶中(元素位置)形成链表,当链表长度超过阈值(8)时,将链表转换为红黑树;
HashMap的内部结构:
HashMap 底层是基于数组和链表实现的,如图所示,其中两个重要的参数:容量和负载因子;容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 size > 16*0.75 时就会发生扩容(容量和负载因子都可以自由调整)

内部包含了一个Node类型的数组 table(Entry<K,V>[] table为jdk 1.7中)。
transient Node<K,V>[] table;
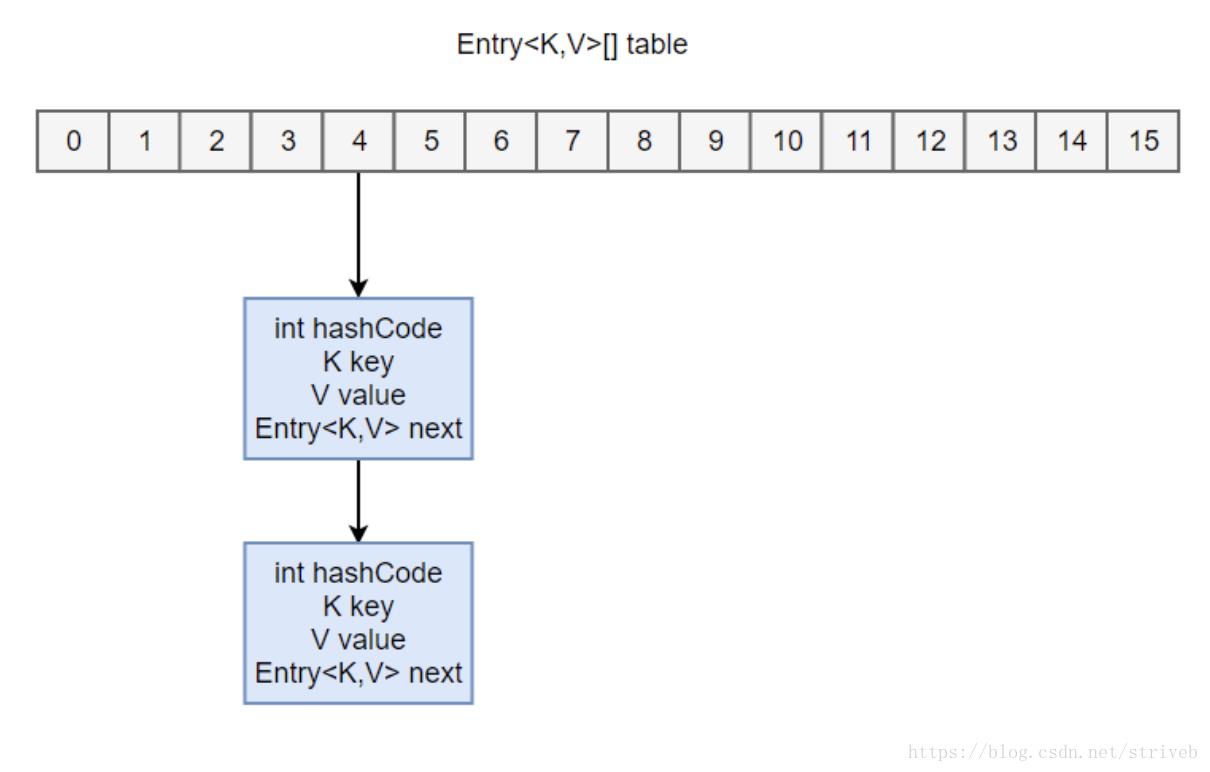
Node存储着键值对。它包含了四个字段,从 next 字段我们可以看出Node是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值相同的Node;
拉链法的工作原理(解决hash冲突):
新建一个 HashMap,默认大小为 16;
- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
- 应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部;

查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比;
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
注意:
-
在并发环境下使用
HashMap容易出现死循环。 -
并发场景发生扩容,调用
resize()方法里的rehash()时,容易出现环形链表。这样当获取一个不存在的key时,计算出的index正好是环形链表的下标时就会出现死循环。