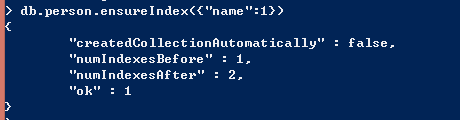
创建索引使用ensureIndex方法,对于同一个集合,同样的索引只需要创建一次,反复创建是徒劳的。
对某个键的索引会加速对该键的查询,然而,对于其它查询可能没有帮助,即便是查询中包含了被索引的键。实践证明,一定要创建查询中用到的所有键的索引

一般来说,如果索引包含N个键,则对于前几个键的查询都会有帮助,如有个索引{"a":1,"b":1,"c":1},实际上是有了{"a":1}、{"a":1,"b":1}、{"a":1,"b":1,"c":1}等的索引,但是使用{"b":1}、{"a":1,"c":1}等索引的查询则不会被优化,只有使用索引前部的查询才能使用该索引。
MongoDB的查询优化器会重排查询项的顺序,以便利用索引
有时,最有效的方法不是使用索引,一般来说, 要是查询要返回集合中一半以上的结果,用表扫描会比几乎每条文档都查索引要高效一下。
建立索引时要考虑如下问题:
1.会做什么样的查询?其中哪些键需要索引?
2.每个键的索引方向是怎样的?
3.如何应对扩展?有没有种不同的键的排列可以使常用数据更多的保留在内存中?
为内嵌文档的键建立索引和普通的键创建索引没有什么区别。
随着集合的增长,需要针对查询中大量的排序做索引,如果对没有索引的键调用sort,MongoDB需要将所有数据提取到内存来排序,因此,可以做无索引排序是有个上限的,一旦集合大到不能在内存中排序,MongoDB就会报错。按照排序来索引以便让MongoDB按照顺序提取数据,这样就能排序大规模数据。
集合中的每个索引都有一个字符串类型的名字,来唯一标识索引,服务器通过这个名字来删除索引或者操作索引,默认情况下,索引名字类似keyname1_dir1_keyname2_dir2_..._keynameN_dirN这种形式,其中keynameX代表索引的键,dirX代表索引的方向(1或者-1),索引名有个字符个数限制,所以特别复杂的索引在创建时一定要使用自定义的名字。
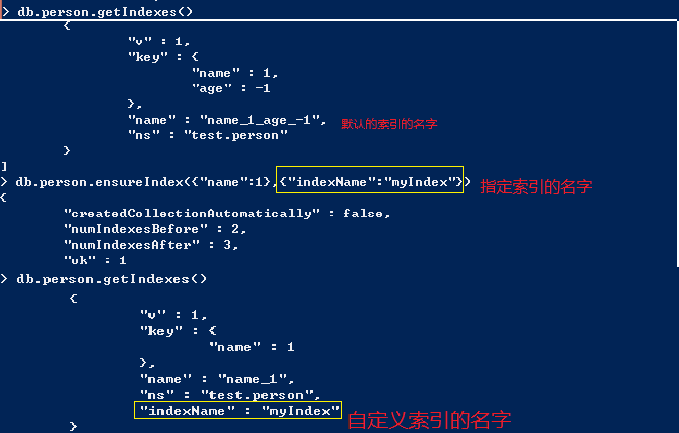
创建唯一索引,如果没有对应的键,索引会将其作为null存储,所以,如果对某个键建立了唯一索引,但插入了多个该索引键的文档,则由于文档包含null值而导致插入失败。
explain会返回查询使用的索引情况(如果有),耗时及扫描文档数的统计信息【3.0中没看出来啊】
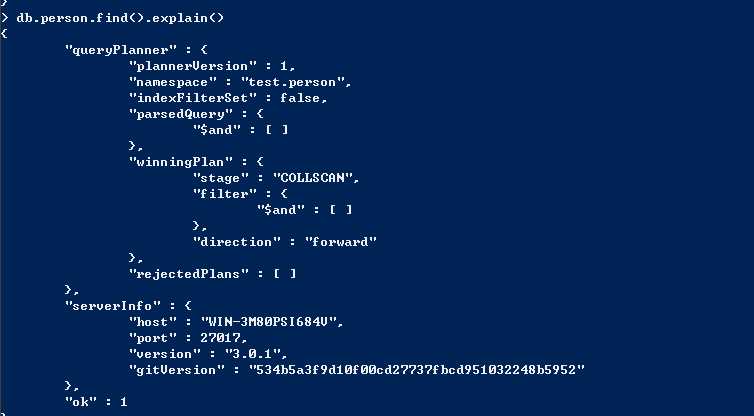
MongoDB的查询优化器会选择使用哪个索引,初次做某个查询会同时尝试各种查询方案,最先完成的被确定使用,其它的则终止掉。
查询方案被记录下来,以备日后应对相同键的查询,查询优化器定期重试其它方案,以防因为添加新的数据后,之前的方案不再是最优的,。
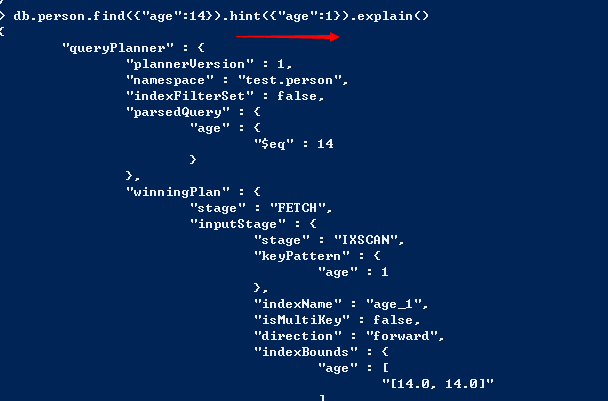
如果发现MongoDB使用了非预期的索引,可以用hit强制使用某个索引。
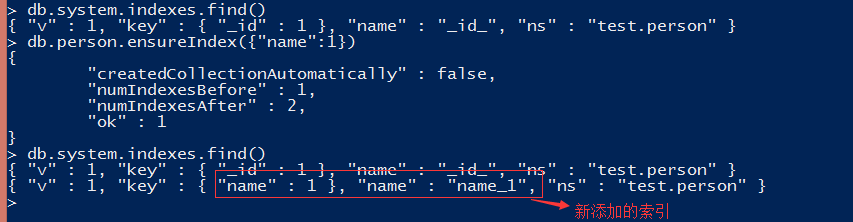
system.indexes集合包含每个索引的详细信息,查看集合发现每个集合至少有两个文档与之对应,一个集合本身,一个对应集合包含的索引,对于只有标准的"_id"索引的集合,如图:【集合名的长度不能超过121字节,集合名和索引名加起来不能超过127字节】
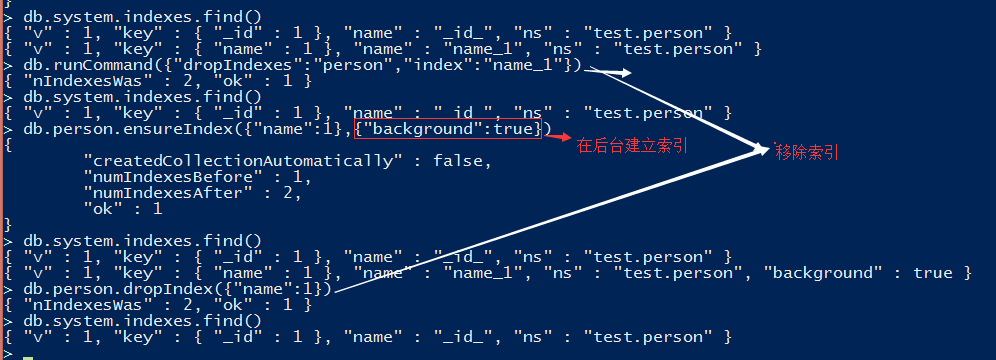
建立索引既耗时也费力,还需要消耗很多资源,使用{"background":true}选项可以使这个过程在后台完成,同时正常处理请求,要是不包括background这个选项,数据库会阻塞建立索引期间的所有请求。阻塞的做法会让索引建立的更快,后台创建索引也会增加些负载,好在不会让服务器停机。为已有文档创建索引比先创建索引在插入所有文档要稍快一点。
找到离当前位置最近的N个场所,MongoDB为坐标平面查询提供了专门的索引,称为地理空间索引。该索引同样使用ensureIndex来创建,只不过参数不是1或-1,而是“2d”
“gps”键的值必须是某种形式的一对值:一个包含两个元素的数组或是包含两个键的内嵌文档

地理空间查询以两种方式进行,即普通查询(find)或者使用数据库命令

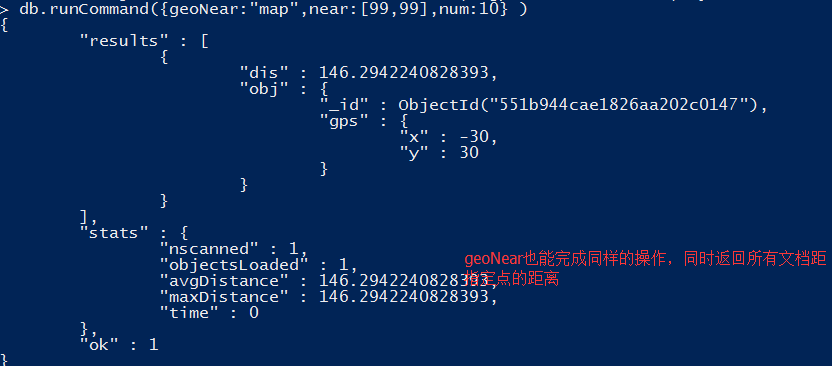
MongoDB不但能找到靠近一个点的文档,还能找到指定形状内的文档,具体做法将原来的"$near"换成"$within"

创建复合的地理空间索引
db.map.ensureIndex({"location":"2d","desc":1})