此作业要求参见: https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
代码及版本控制:
coding未公开链接已更新
GitHub项目地址: https://github.com/Gravity9874/cp.git
Coding 克隆地址: https://e.coding.net/zhx9874/cipintongji/cptj.git
功能1 小文件输入。
重难点分析:首先import sys导入模块,使用sys.argv函数读取命令行参数,返回一个列表,用sys.argv[0]表示第一个参数,即文件名。
在获取命令行参数之后,判断argv[1]是否为-s,是的话随即使用open函数打开目标文件,使用.read以字符串形式返回文章内容。
然后调用re模块的finddall函数通过正则表达式对单词进行分割匹配,返回列表,其中正则表达式加r表示原生字符串,防止python对表达式中的转义字符进行操作。
接着使用count()函数,对返回列表进行统计,统计字符串里字符出现的次数,返回键值对,其中key为单词,value为该单词出现的次数,最后使用Counter类中的most_common()函数,参数为n列出前n个元素,返回一个列表,其中的每一个元素为一个元组,其中元组第0位是被计数的单词,元组的第1位是该单词出现的次数。
主要代码如下:
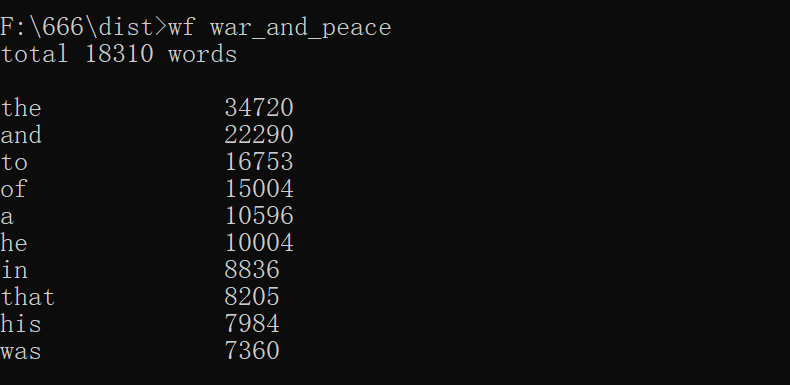
1 def g1(book): # 功能1:对文本进行处理,进行词频统计 2 num = (0) 3 if (q == 1): 4 lists = findall(r'[a-z0-9^-]+', book.lower()) # 重定向方式输入时直接对字符串数据进行处理 5 else: 6 if os.path.splitext(book)[-1] != '.txt': # 为输入的文章名称加上txt后缀 7 book = book + '.txt' 8 a = open(book, 'r', encoding='utf-8') 9 lists = findall(r'[a-z0-9^-]+', a.read().lower()) # 将文本所有英文字母转变为小写,通过正则表达式对单词进行分割匹配,返回列表 10 words = Counter(lists) # count()用于统计字符串里字符出现的次数,返回键值对字典 11 for key, value in words.items(): # key为单词,value为该单词出现的次数 12 num += 1 13 if (w == 1): 14 print('total' + ' ' + str(num)) 15 else: 16 print('total' + ' ' + str(num) + ' ' + 'words') 17 print('') 18 frequentwords = words.most_common(10) # most_common函数,指定参数N,列出前n个元素,返回元组,0位为元素,1位为出现次数 19 for i in frequentwords: 20 print("{0:<9} {1:<9} ".format(i[0], i[1]))
运行截图如下:

功能2 支持命令行输入英文作品的文件名
重难点分析:处理文件名时,对输入无后缀的文件名需要进行处理,添加txt后缀,且要判断命令行参数,区分功能一。
主要代码如下:下为功能选择判断代码,词频统计函数代码同功能一
1 if __name__ == '__main__': 2 if sys.argv[1] == '-s': 3 if (len(sys.argv) == 3): 4 w = 1 5 q = 0 6 g1(sys.argv[2]) 7 else: 8 reword = sys.stdin.read() # 重定向读入文本内容 9 q = 1 10 w = 0 11 g1(reword) 12 elif os.path.isdir(sys.argv[1]): # 当输入参数是目录名时执行文件夹处理函数 13 g3(sys.argv[1]) 14 else: 15 q = 0 16 w = 0 17 g1(sys.argv[1])
运行截图如下:
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重难点分析:首先要判断命令行参数是否为文件夹名称,使用os模块的path.isdir()来判断参数是否为一个文件夹,然后使用listdir() 函数,获取目标文件夹中的所有文件。返回一个列表
然后把文件名与后缀分离,并依次将文件夹中的文章路径传入统计函数进行统计。
重要代码如下:
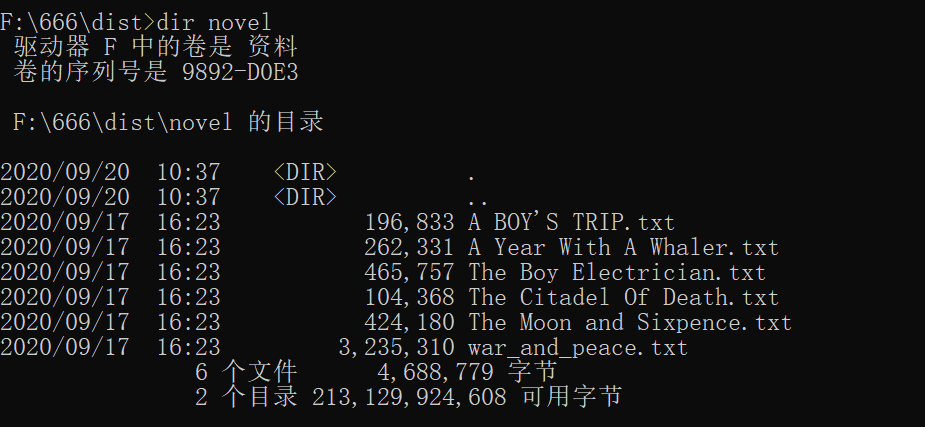
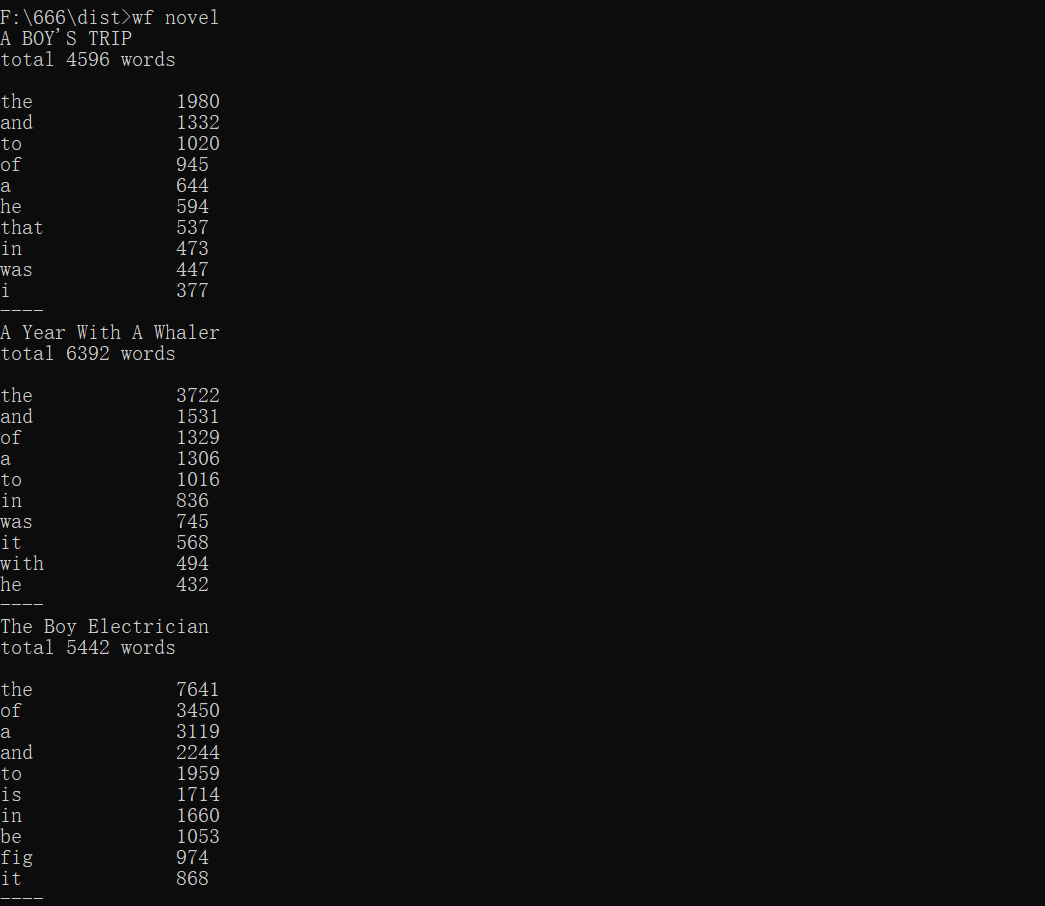
1 def g3(folder): 2 novels = os.listdir(folder) # 返回指定的文件夹包含的文件或文件夹的名字的列表 3 for novel in novels: 4 filename = os.path.splitext(novel)[0] # 将文本名字与文件后缀分离 5 print(filename) 6 global q 7 global w 8 q = 0 9 w = 0 10 g1(folder + '/' + novel) # 将目标文章路径传入统计函数 11 print('----')
运行截图如下:

功能四
重难点分析:首先判断命令行是否为重定向功能,通过参数长度判断,与功能一区分,使用stdin.read()直接获取目标文章内容,以字符串形式返回。设置标志位,在统计函数中直接对字符串进行处理。
功能四主要代码如下:
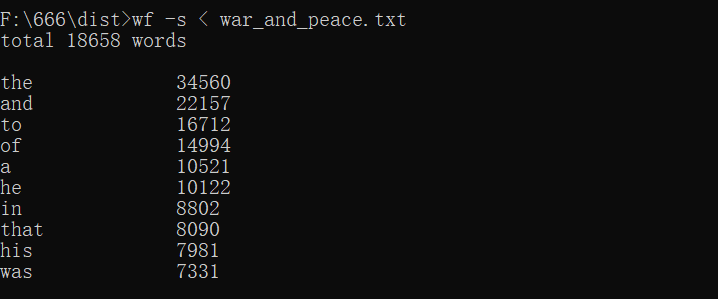
1 from collections import Counter 2 import sys 3 import os 4 from re import findall 5 global q # 标记,q=1时为重定向方式输入 6 global w # 标记,w=1时在功能1当中不输出words 7 8 def g1(book): # 功能1:对文本进行处理,进行词频统计 9 num = (0) 10 if (q == 1): 11 lists = findall(r'[a-z0-9^-]+', book.lower()) # 重定向方式输入时直接对字符串数据进行处理 12 else: 13 if os.path.splitext(book)[-1] != '.txt': # 为输入的文章名称加上txt后缀 14 book = book + '.txt' 15 a = open(book, 'r', encoding='utf-8') 16 lists = findall(r'[a-z0-9^-]+', a.read().lower()) # 将文本所有英文字母转变为小写,通过正则表达式对单词进行分割匹配,返回列表 17 words = Counter(lists) # count()用于统计字符串里字符出现的次数,返回键值对字典 18 for key, value in words.items(): # key为单词,value为该单词出现的次数 19 num += 1 20 if (w == 1): 21 print('total' + ' ' + str(num)) 22 else: 23 print('total' + ' ' + str(num) + ' ' + 'words') 24 print('') 25 frequentwords = words.most_common(10) # most_common函数,指定参数N,列出前n个元素,返回元组,0位为元素,1位为出现次数 26 for i in frequentwords: 27 print("{0:<9} {1:<9} ".format(i[0], i[1])) 28 29 if __name__ == '__main__': 30 if sys.argv[1] == '-s': 31 if (len(sys.argv) == 3): 32 w = 1 33 q = 0 34 g1(sys.argv[2]) 35 else: 36 reword = sys.stdin.read() # 重定向读入文本内容 37 q = 1 38 w = 0 39 g1(reword) 40 elif os.path.isdir(sys.argv[1]): 41 g3(sys.argv[1]) 42 else: 43 q = 0 44 w = 0 45 g1(sys.argv[1])
运行截图如下:
功能5 此功能为选做题,如果完成正确得30经验值,如果不做得0经验值,不会倒扣分数。
邹欣老师说,“这样,我想知道5个字母的单词中最频繁出现的是哪10个单词,top10,你怎么办呢?”
你一下就想到了,说了思路,应该blablabla。邹欣老师又问,“6个字母的单词中最频繁出现的是哪10个单词呢,top10?”
老杨追问,“6个字母的字母的单词中最频繁出现的是哪100个单词呢,top100?”
你问,“算法我想好了,性能估计也没问题,命令行参数老师怎么规定呢?”
老杨说,"你来规定,写个简单的文档,包括如何运行,给出运行实例的截图。"
在原有统计的基础上增加了字母数量的判断,通过字典的键值对,用len函数获取字母数量,及字符串长度,然后进行判断,控制输出数量通过most_common参数来实现,most_common(n)表示输出排名前n个元素。
实现此功能的主要函数如下
1 def g4(novel,len1,number): #功能5 2 a = open(novel, 'r', encoding='utf-8') 3 len2=int(len1) #强制转换argv参数为int型 4 number2=int(number) 5 listt=findall(r'[a-z0-9^-]+', a.read().lower()) # 将文本所有英文字母转变为小写,通过正则表达式对单词进行分割匹配,返回列表 6 words2=Counter(listt) #统计字符串里字符出现的次数,返回键值对字典 7 newwords={} 8 for key, value in words2.items():10 if(len(key)==len2): #判断字母个数是否符合输入参数要求 11 newwords[key]=value #将符合要求的数据建立键值对存入newwords12 words3 = Counter(newwords) 13 frequentword = words3.most_common(number2) #输出排名前几的单词,由参数控制输出数量 14 for i in frequentword: 15 print("{0:<9} {1:<9} ".format(i[0], i[1]))
功能五判断及命令行参数输入代码如下
1 elif sys.argv[1] == '-q': 2 g4(sys.argv[2],sys.argv[3],sys.argv[4])
运行截图如下

此功能的简要描述文档:
输入参数格式为: wf -q 文章名字.txt n1 n2 其中wf表示程序名称 -q为功能识别,判断是否属于功能5 n1表示需要排序的单词长度,也就是字母数量 n2表示需要排序的数量,输出排序结果的top n2
psp
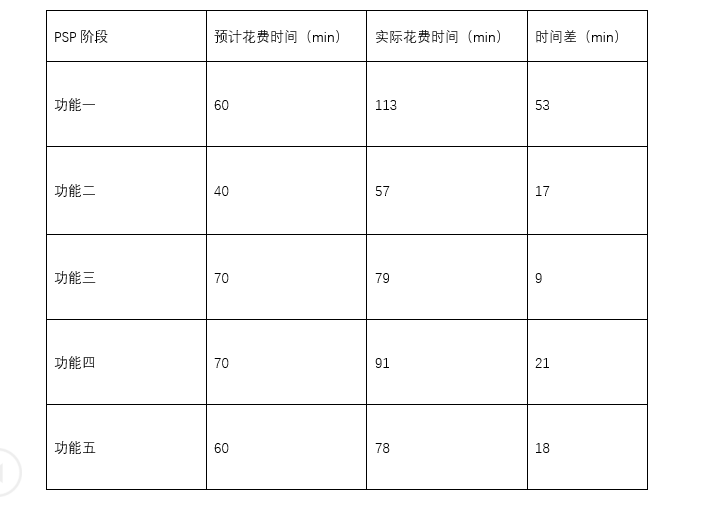
时间差原因总结:在代码编写,git的使用,重定向等问题上都遇到许多困难,通过请教学长同学,查阅资料才得以解决,对初次使用的函数,模块也是问题百出,这其中尤其是git的配置,遇到了很多麻烦,耗费大量时间。
在功能五的实现过程中,因传入参数格式问题一直得不到解决,导致浪费许多时间。