学校教务处网站
登陆窗口
表单数据
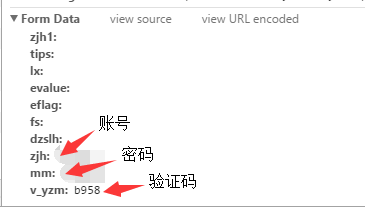
观察登陆窗口和提交的表单数据可知只要将账号、密码、验证码正确赋值提交即可模拟登陆。
账号和密码都有,问题的关键就在验证码上。
右键验证码图片审查观察源码如下图:
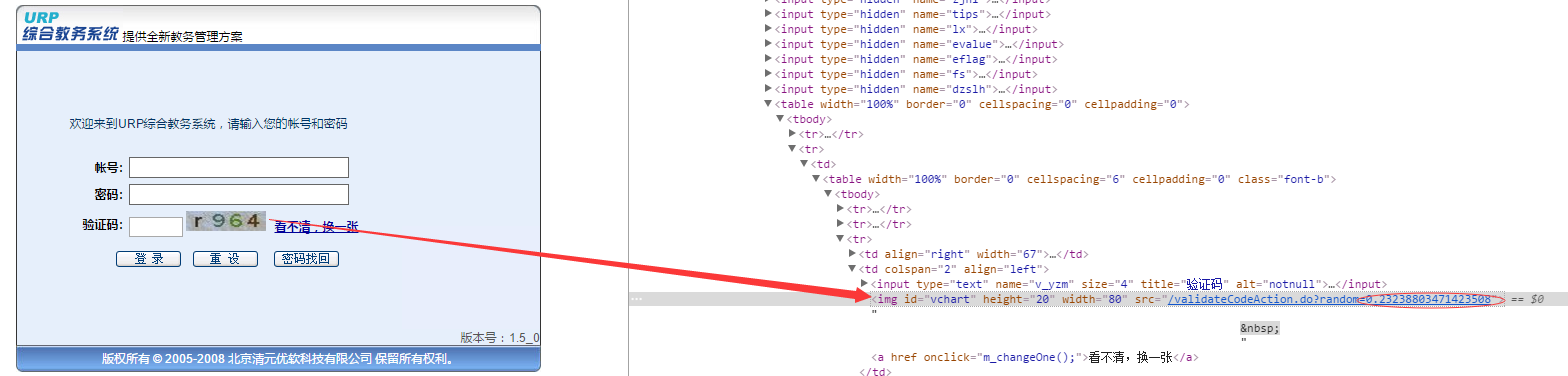
刚开始很纠结random那段随机数,以为是确定的随机数对应确定的验证码,可是一直没有解决获取这个随机数的方法(直接抓取的话src总为空),然后去网上各种查发现这句话
一般验证码只是判断cookie 后面的随机值是为了防止浏览器读取图片缓存,造成验证码输入错误
然后自己就复制了一个带random的验证码网址刷新了两下结果发现验证码真的会变,不是根据random,于是从网上查找得知只输入random参数前的地址即可,于是继续向下开展。
具体的思路是登陆将验证码下载下来,然后手动输入,提交账号、密码、验证码三个数据进行模拟登陆。
模拟登陆
# coding:utf8 import re import urllib import urllib2 import cookielib loginUrl = 'http://115.24.160.162/loginAction.do' #cookie cookie = cookielib.CookieJar() handler = urllib2.HTTPCookieProcessor(cookie) opener = urllib2.build_opener(handler) #postdata values = { 'zjh':'xxxxxx', 'mm':'xxxxxx', 'v_yzm':'' } postdata = urllib.urlencode(values) #headers header = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'Referer':'http://115.24.160.162/loginAction.do' } #第一次请求网页得到cookie request = urllib2.Request(loginUrl,postdata,headers=header) response = opener.open(request) print '第一次请求网页得到cookie:' print response.getcode() #获取验证码----------------!!!问题一直出在这,要用带cookie的方法访问验证码的网页---这样的话进入的验证码的页面对应的验证码就是登陆页面的验证码了哈哈哈哈哈(之前用的是不带cookie的urlopen()方法...) yzm = opener.open('http://115.24.160.162/validateCodeAction.do') yzm_data = yzm.read() yzm_pic = file('yzm.jpg','wb') yzm_pic.write(yzm_data) yzm_pic.close() #用户输入验证码 print '请输入验证码:' values['v_yzm'] = raw_input() #带验证码模拟登陆 postdata = urllib.urlencode(values) request = urllib2.Request(loginUrl,postdata,header) response = opener.open(request) print 'Response of loginAction.do' print response.read().decode('gbk')
爬取成绩
根据最后打印出的网址源代码可知成功登陆。现在我们来爬取成绩。
成绩页面:
刚开始以为相应的按钮会有对应的超链接,比如有一个专门的成绩网址,然后就去源代码里苦苦寻找,半天无获,而且点击不同按钮浏览器显示的连接根本不变。后来F12看了看网络那一栏发现了玄机
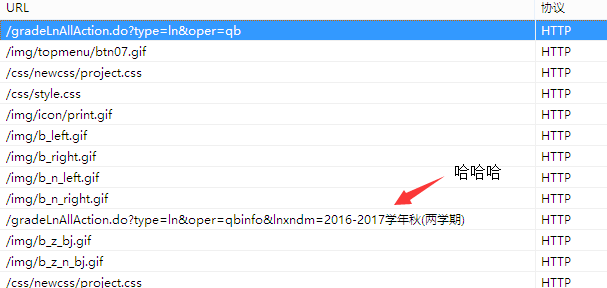
再看这个链接的响应正文,完美获得成绩页面。
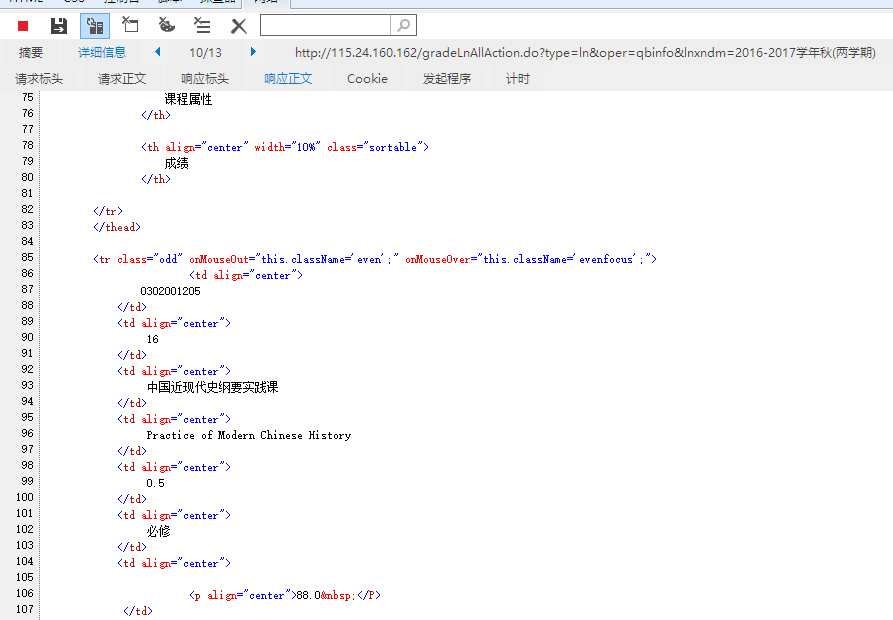
接下来就是正则表达式匹配得到课程名称和成绩了
#bingo top_url = 'http://115.24.160.162/gradeLnAllAction.do?type=ln&oper=qbinfo&lnxndm=2016-2017学年秋(两学期)' response = opener.open(top_url) print 'Response of top.jsp' content = response.read().decode('gbk') pattern = re.compile('<tr.*?class="odd".*?</td>.*?</td>.*?<td align="center">(.*?)</td>.*?<p align="center">(.*?) </P>', re.S) grades = re.findall(pattern, content) for grade in grades: print grade[0], grade[1]
正则表达式的说明(引用自http://cuiqingcai.com/990.html)
1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了两个分组,在后面的遍历grades中,grade[0]就代表第一个(.*?)所指代的内容,grade[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
抓取结果

结语
感谢攀哥(他的csdn:http://m.blog.csdn.net/blog/index?username=E80FA)