Scrapy爬虫(三):scrapy架构及原理
scrapy爬虫尝鲜
scrapy现在已经完美支持python3+,所以后面的实例我都会使用python3+的环境。首先我们来尝下鲜,下面的代码是scrapy官方文档中的一段演示代码,就这么几行代码就完成了对http://quotes.toscrape.com/tag/humor/ 的爬取解析存储,可以一窥scrapy的强大。
#quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.xpath('span/small/text()').extract_first(),
}
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)运行scrapy runspider quotes_spider.py -o quotes.json
运行后的数据存储在quotes.json文件中
[
{"text": "u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.u201d", "author": "Jane Austen"},
{"text": "u201cA day without sunshine is like, you know, night.u201d", "author": "Steve Martin"},
{"text": "u201cAnyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car.u201d", "author": "Garrison Keillor"},
{"text": "u201cBeauty is in the eye of the beholder and it may be necessary from time to time to give a stupid or misinformed beholder a black eye.u201d", "author": "Jim Henson"},
{"text": "u201cAll you need is love. But a little chocolate now and then doesn't hurt.u201d", "author": "Charles M. Schulz"},
{"text": "u201cRemember, we're madly in love, so it's all right to kiss me anytime you feel like it.u201d", "author": "Suzanne Collins"},
{"text": "u201cSome people never go crazy. What truly horrible lives they must lead.u201d", "author": "Charles Bukowski"},
{"text": "u201cThe trouble with having an open mind, of course, is that people will insist on coming along and trying to put things in it.u201d", "author": "Terry Pratchett"},
{"text": "u201cThink left and think right and think low and think high. Oh, the thinks you can think up if only you try!u201d", "author": "Dr. Seuss"},
{"text": "u201cThe reason I talk to myself is because Iu2019m the only one whose answers I accept.u201d", "author": "George Carlin"},
{"text": "u201cI am free of all prejudice. I hate everyone equally. u201d", "author": "W.C. Fields"},
{"text": "u201cA lady's imagination is very rapid; it jumps from admiration to love, from love to matrimony in a moment.u201d", "author": "Jane Austen"}
]scrapy data flow(流程图)
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
下面的图表显示了Scrapy架构组件,以及运行scrapy时的数据流程,图中红色箭头标出。
我大概翻译了下,具体参考官方文档
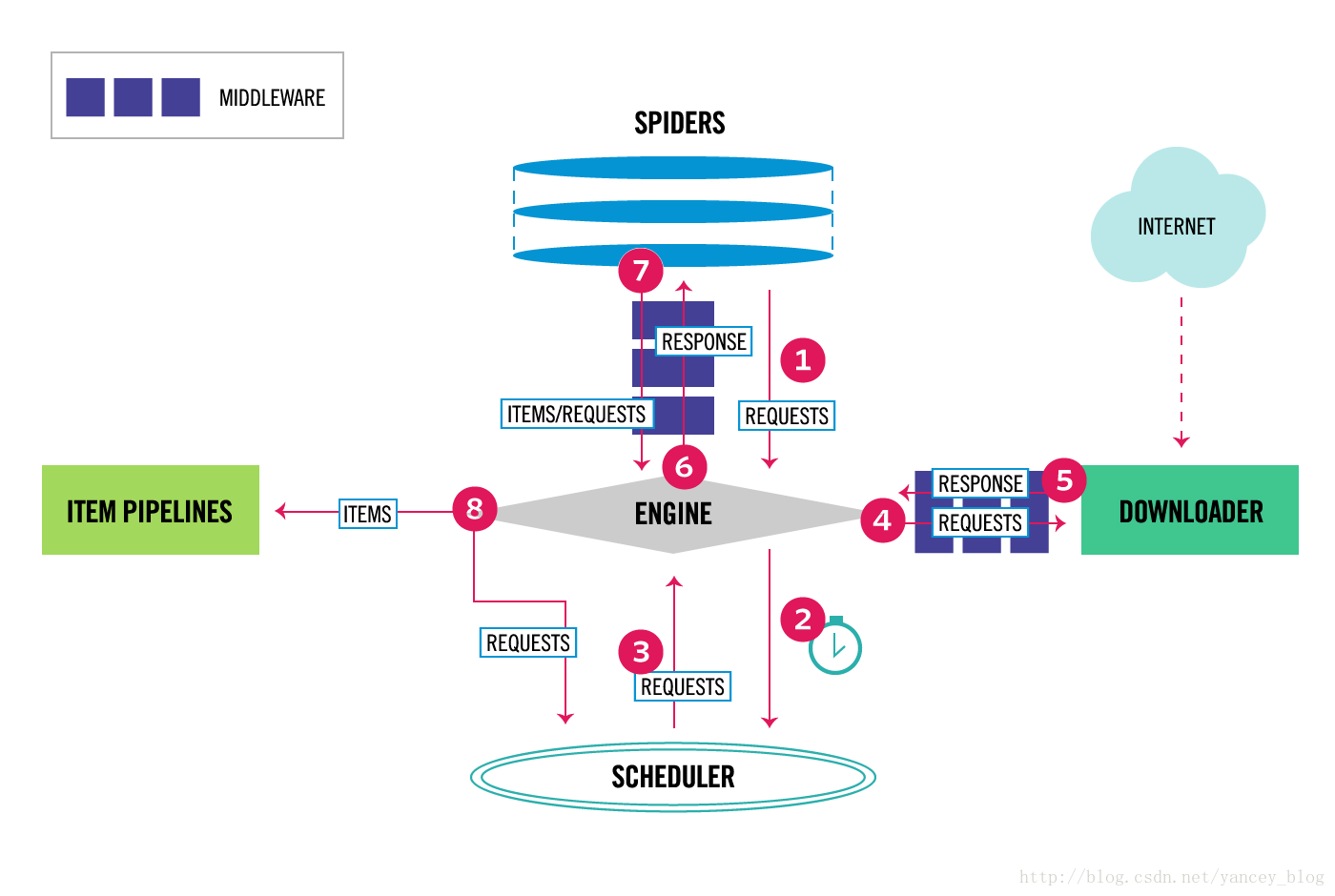
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎获得初始请求开始抓取。
2、爬虫引擎开始请求调度程序,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎。
6、引擎将下载器的响应通过中间件返回给爬虫进行处理。
7、爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
上图展示了scrapy的所有组件工作流程,下面单独介绍各个组件
-
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。 -
调度器
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。 -
下载器
通过engine请求下载网络数据并将结果响应给engine。 -
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。 -
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。 -
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。 -
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
scrapy项目结构
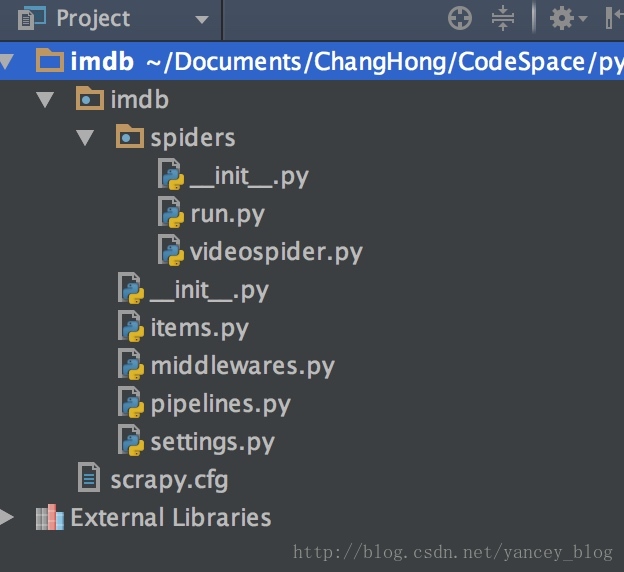
- items.py 负责数据模型的建立,类似于实体类。
- middlewares.py 自己定义的中间件。
- pipelines.py 负责对spider返回数据的处理。
- settings.py 负责对整个爬虫的配置。
- spiders目录 负责存放继承自scrapy的爬虫类。
- scrapy.cfg scrapy基础配置