一、ES 产生背景
对于一般的公司,初期是没有那么多数据的,所以很多公司更倾向于使用传统的数据库:mysql;比如我们要查找关键字“呀呀呀”,那么查询的方式大概就是:select * from table where field like ‘%呀呀呀%’; 但是随着业务发展,数据会不断的膨胀,那么问题就来了;mysql单表查询能力即便经过了优化,它的极限也就是400W左右的数据量。而且还会经常出现查询超时的现象;
然后很多公司开始对数据库进行横向和纵向的扩容,开始进行数据库表的“拆分”:横向拆分和纵向拆分;但是即便这样操作,仍然会出现很多问题,比如:
1、数据库会出现单点故障问题,于是先天主从复制关系,于是增加了运维成本.
2、因为对表的拆分,增加了后期维护的难度,同样也是增加了运维成本.
3、即便做了大量的维护,但对于大数据的检索操作,依然很慢,完全达不到期望值.
所以为了满足需求: 海量数据组合条件查询 、毫秒级或者秒级返回数据,ElasticSearch应运而生。
二、Lucene 定义
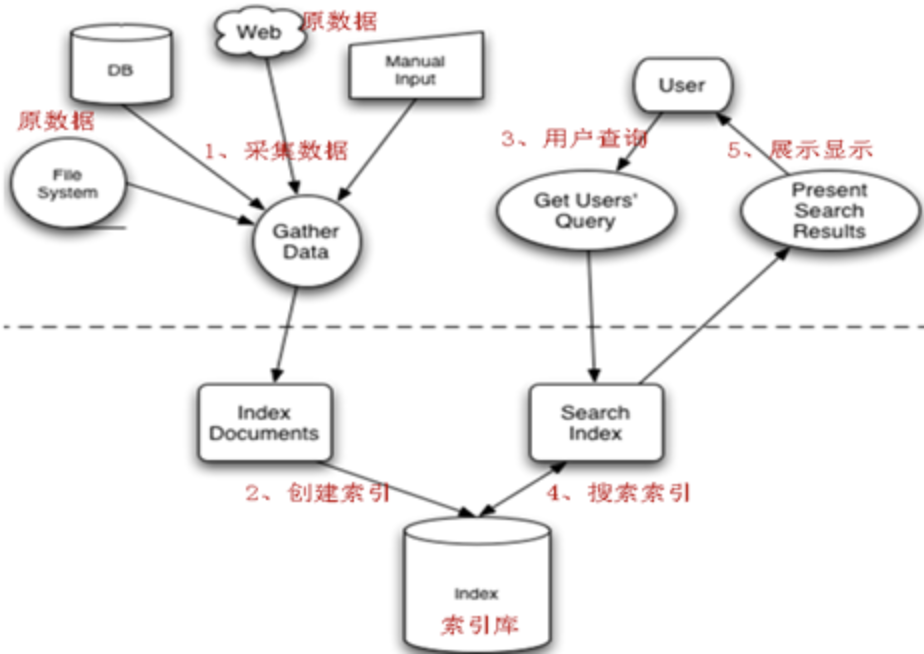
lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。官网地址: http://lucene.apache.org/
搜索流程:创建查询--->执行搜索--->渲染搜索结果。
三、ES 定义
四、ES vs Lucene

五、Solr 定义
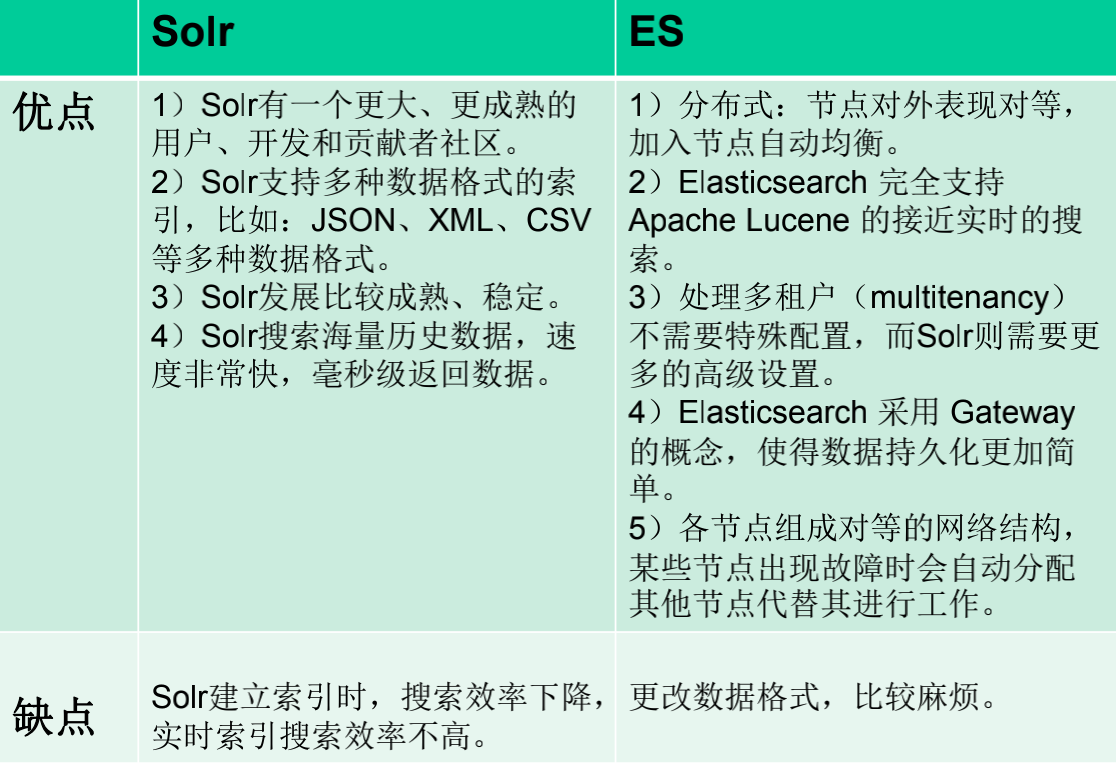
六、ES vs Solr 优缺点
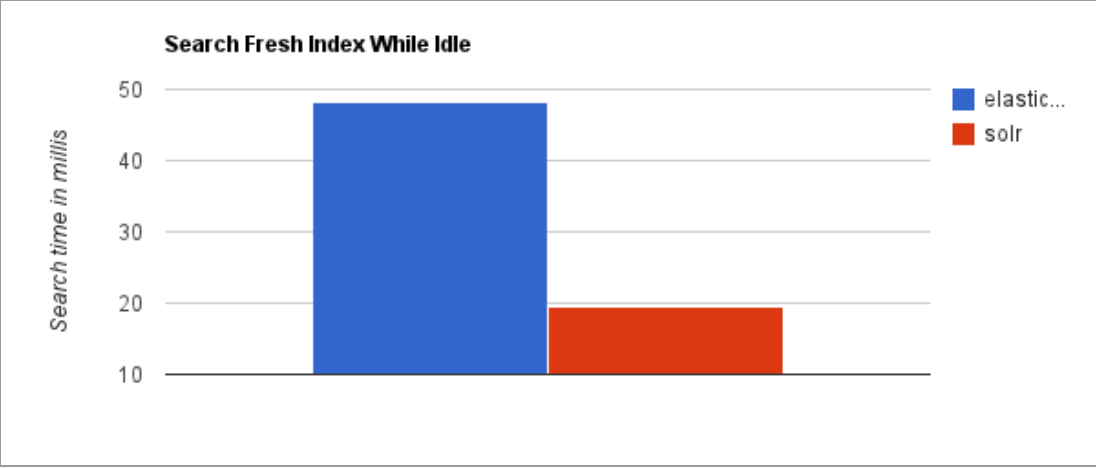
七、ES vs Solr
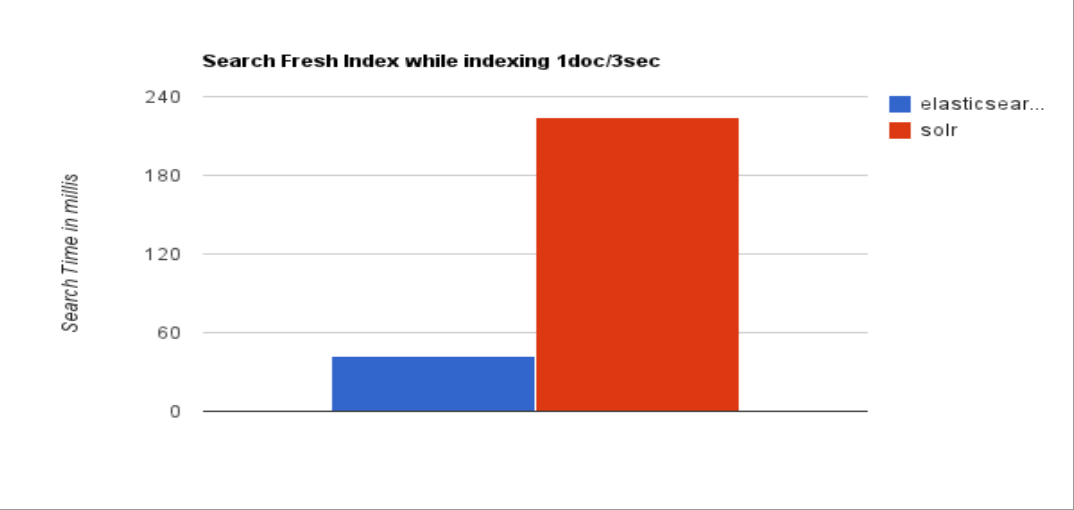
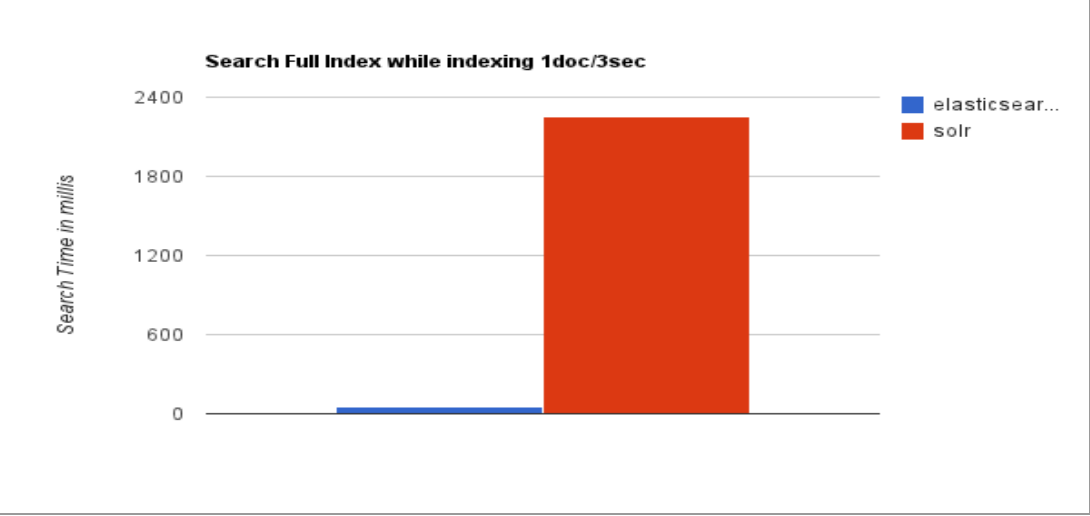
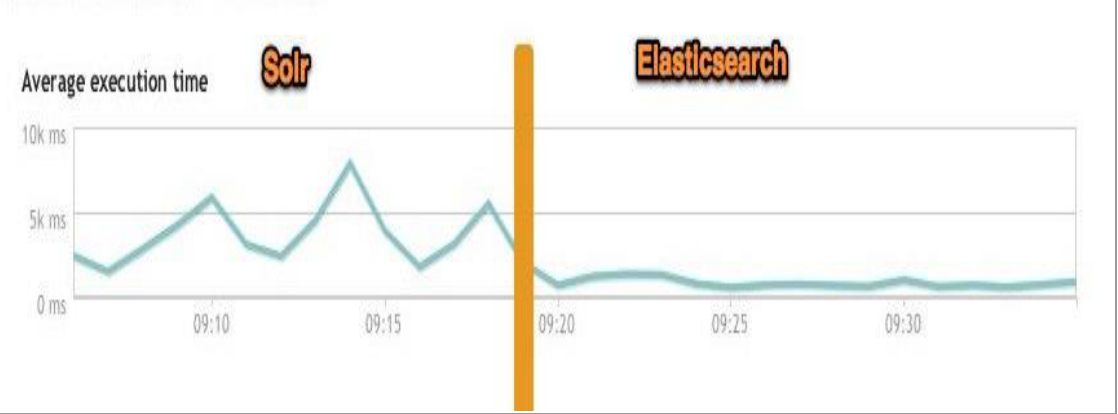
检索速度:当单纯的对已有数据进行搜索时,Solr更快。
八、ES vs 关系型数据库
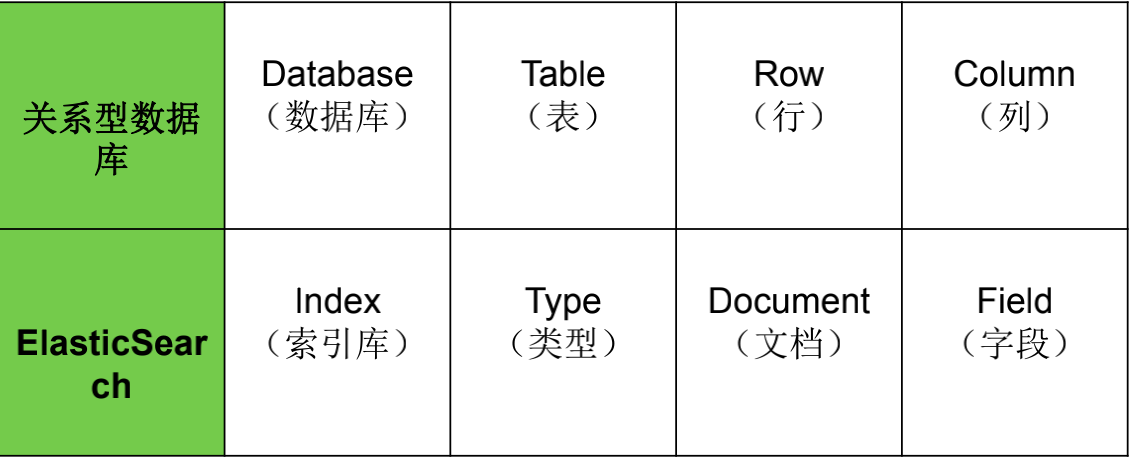
索引(Index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。