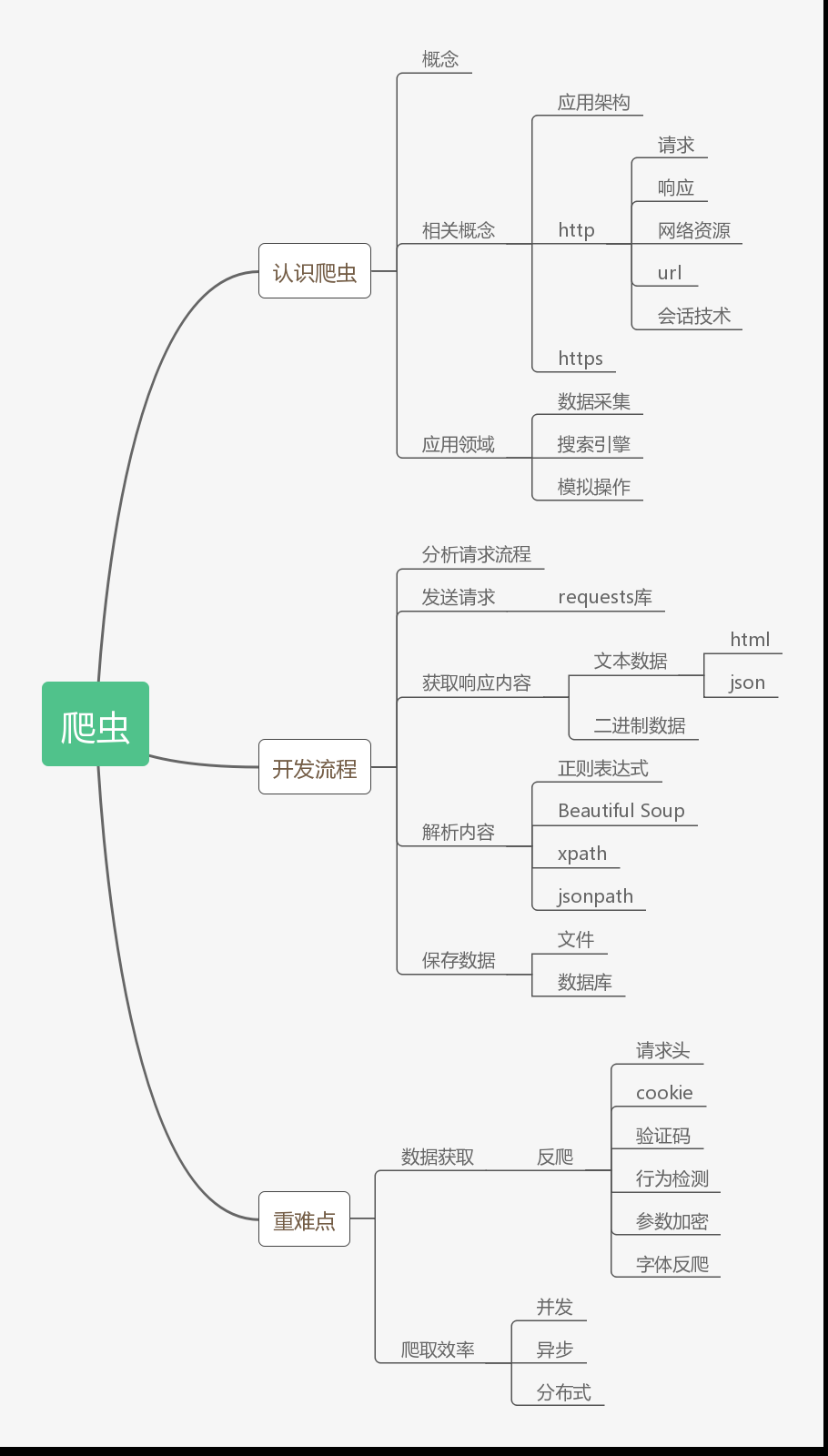
一、认识爬虫
1、爬虫概念
口语化概念:网络爬虫,程序,自动,批量的下载网络资源。
专业化概念:伪装成客户端与服务端进行数据交互的程序。
2、相关概念
2、1 应用架构
-c/s client server 客户端,服务端(如英雄联盟客户端,qq客户端)
-b/s browser server 浏览器,服务端(各种网站)
-m/s mobile server 移动端,服务端 (各种手机等移动端的APP)
2、2 http协议
定义:超文本传输协议
1,出入网址,dns
2,TCP连接,三次握手
3,客户端发送HTTP请求报文
4,服务端收到,处理请求,返回一个包含结果的响应
5,浏览器进行渲染和展示
特点:
--http无连接,每次只处理一个请求
--http媒体独立
--http无状态
2、2、1 请求(request)
请求包含请求行,请求头,空行,请求数据/请求体四个部分

1,请求方法
1.0 GET POST HEAD

2,请求头
名称 + :+ 空格 + 值

3,请求体
二进制,GET没有请求体。
2、2、2 响应
状态行,消息报头,空行,响应正文
1,http响应状态码
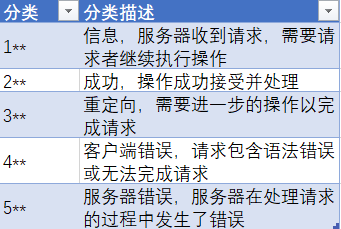
2,响应报头

2、2、3 会话技术
会话技术分为cookie,session,cookies
cookie特点:凭证,保存在客户端
session 会话 基于cookie,保存在服务器
2、2、4 网络资源
爬虫的目标就是网络资源,定位
2、2、5 URL
定义:统一资源定位符,网址,标识
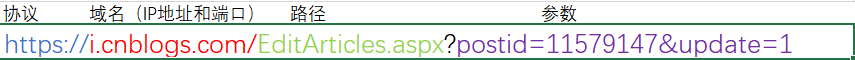
2、3 https
ssl?TLS 协议
-申请ca证书
-加密,安全
-端口不一样:http 80 https 443
3、应用领域
3、1 数据采集
3、2 搜索引擎
3、3 模拟操作
二、开发流程
1、分析请求流程
2、发送请求
3、获取响应内容
4、解析内容
5,数据持久化
1、分析请求流程
目的:找到目标资源的http请求,具体指标:
1,请求方法
2,,URL
3,请求头
4,请求数据(参数)
1、1 工具(抓包)
1、1、1 fiddler
1、1、2 谷歌浏览器(常用)
2、发送请求
2、1 通过socket发送HTTP请求
发送流程:
from socket import socket
#创建一个客户端
client = socket()
#连接服务器
client.connect(('www.baidu.com',80))
#构造HTTP请求报文
data = b'GET / HTTP/1.0
HOST: www.baidu.com
'
#发送报文
client.send(data)
#接收响应
res = b''
temp = client.recv(1024)
print('*'*20)
while temp:
res += temp
temp = client.recv(1024)
print(res)
client.close()
2、2 工具库
1,urllib Python的标准库,网络请求的
2,urllib3 基于Python3
3,requests 牛逼,最常用
3、获取响应内容
3、1 通过socket下载一张图片
流程如下:
from socket import socket
#创建一个客户端
client = socket()
img_url = 'http://t2.hddhhn.com/uploads/tu/201610/198/gkowtcsq5sg.jpg'
#连接服务器
client.connect(('t2.hddhhn.com',80))
#构造HTTP请求报文
data = b'GET /uploads/tu/201610/198/gkowtcsq5sg.jpg/ HTTP/1.0
HOST: t2.hddhhn.com
'
#发送报文
client.send(data)
#接收响应
res = b''
temp = client.recv(1024)
print('*'*20)
while temp:
res += temp
temp = client.recv(1024)
print(res)
client.close()
headers,img_data = res.split(b'
')
print(headers)
#保存图片
with open('test.jpg','wb') as f:
f.write(img_data)
3、2通过requests下载
流程如下:
import requests
img_url = 'http://t2.hddhhn.com/uploads/tu/201610/198/gkowtcsq5sg.jpg'
response = requests.get(img_url)
with open('test.jpg','wb') as f:
f.write(response.content)
4、解析内容
响应体分为两大类:文本,二进制数据
文本:html,json,(js,css)
4、1 html解析
4、1、1 正则表达式
4、1、2 beautiful soup
4、1、1 xpath
4、2 json解析
4、2、1 jsonpath
5、数据持久化
1,写文件
2,写数据库
三、重点、难点
1、数据获取
1.1 请求头反爬
1.2 cookie
1.3 验证码
1.4 行为检测
1.5 参数加密
1.6 字体反爬
2、爬取效率
2.1 并发
2.2 异步
2.3 分布式
四、总结