Solr主配置文件
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。

fieldType
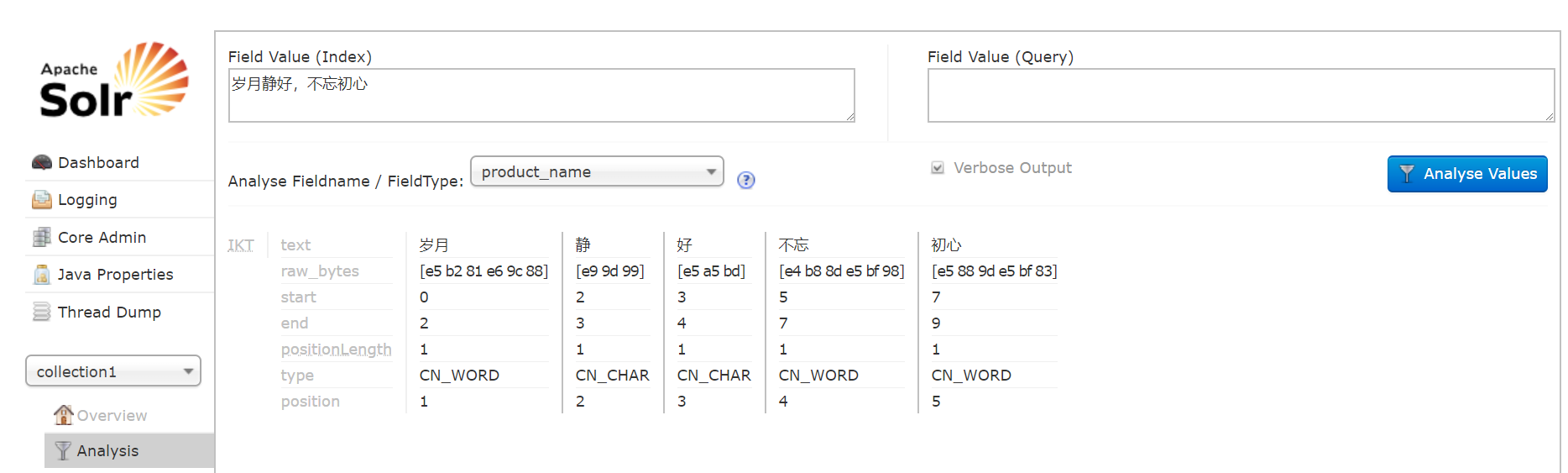
打开这个配置文件,我们可以看到许多fieldType标签,string、int什么的,其中我们拿text_general来举例分析:
1 <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
2 <analyzer type="index">
3 <tokenizer class="solr.StandardTokenizerFactory"/>
4 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
5 <filter class="solr.LowerCaseFilterFactory"/>
6 </analyzer>
7 <analyzer type="query">
8 <tokenizer class="solr.StandardTokenizerFactory"/>
9 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
10 <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
11 <filter class="solr.LowerCaseFilterFactory"/>
12 </analyzer>
13 </fieldType>
FieldType子结点包括:name,class,positionIncrementGap等一些参数:
1、name:是这个FieldType的名称
2、class:是Solr提供的包solr.TextField,solr.TextField允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
3、positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括
1、分词和过滤索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
2、搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
field
在schema.xml中除了fieldType占有大量篇幅外,还有field,以下是一部分
1 <field name="name" type="text_general" indexed="true" stored="true"/>
2 <field name="features" type="text_general" indexed="true" stored="true"multiValued="true"/>
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组:

UniqueKey
Solr中默认定义唯一主键key为id域,Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
1 <uniqueKey>id</uniqueKey>
copyField
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
1 <copyField source="title" dest="text"/>
2 <copyField source="author" dest="text"/>
3 <copyField source="description" dest="text"/>
4 <copyField source="keywords" dest="text"/>
5 <copyField source="content" dest="text"/>
比如,输入关键字搜索title标题内容content,定义title、content、text的域,根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中。
dynamicField
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
配置中文分词器
网上下载好相应版本的IKAnalyzer,拷贝IKAnalyzer的文件到Web容器下,以tomcat为例,Solr目录中将IKAnalyzer2012FF_u1.jar拷贝到 Tomcat的webapps/solr/WEB-INF/lib 下。在Tomcat的webapps/solr/WEB-INF/下创建classes目录,将IKAnalyzer.cfg.xml、stopword.dic ext.dic 复制到 Tomcat的webapps/solr/WEB-INF/classes,stopword.dic 和ext.dic必须保存成无BOM的utf-8类型(一般默认就这样)。
IKAnalyzer.cfg.xml修改字典引用
1 <?xml version="1.0" encoding="UTF-8"?>
2 <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
3 <properties>
4 <comment>IK Analyzer 扩展配置</comment>
5 <!--用户可以在这里配置自己的扩展字典 -->
6 <entry key="ext_dict">ext.dic;</entry>
7 <!--用户可以在这里配置自己的扩展停止词字典-->
8 <entry key="ext_stopwords">stopword.dic;</entry>
9 </properties>
修改Solr的schema.xml文件,添加FieldType:
1 <!-- IKAnalyzer-->
2 <fieldType name="text_ik" class="solr.TextField">
3 <analyzer type="index" isMaxWordLength="false"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
4 <analyzer type="query" isMaxWordLength="true"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
5 </fieldType>
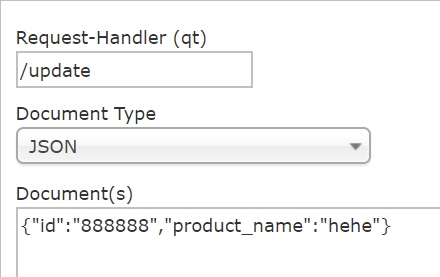
solr配置文件中有的域我们才能进行update提交数据,不然插不进数据也便无法为这类数据建立索引。根据需求配置自定义域,这样我们才能够插入字段product_name。
1 <!--IKAnalyzer Field-->
2 <field name="product_name" type="text_ik" indexed="true" stored="true" />
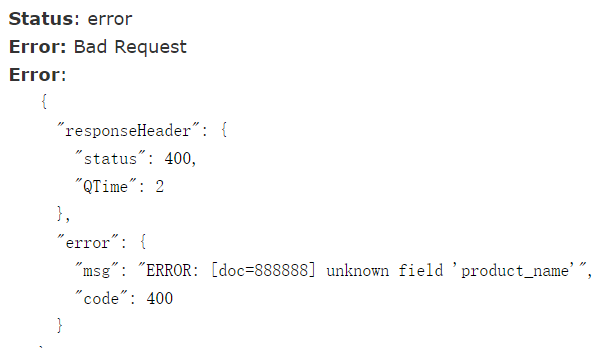
未配置product_name前插入数据:
配置域后,就能插product_name了:

接下来测试中文分词(),可流畅分词,如果有需要,可以在ext.dic设置自定义词汇。