一、算法思想
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。凡是涉及到元素的分组管理问题,都可以考虑使用并查集进行维护。
二、算法流程
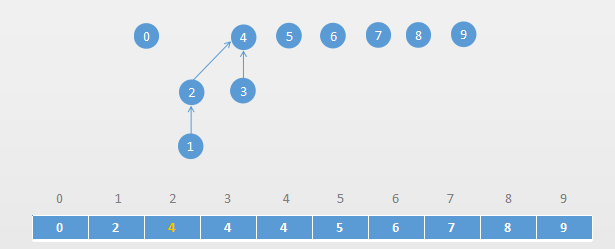
初始化
把每个点所在集合初始化为其自身。
通常来说,这个步骤在每次使用该数据结构时只需要执行一次,无论何种实现方式,时间复杂度均为O(N)。
查找
查找元素所在的集合,即根节点。
合并
将两个元素所在的集合合并为一个集合。
通常来说,合并之前,应先判断两个元素是否属于同一集合,这可用上面的“查找”操作实现。
三、算法实现
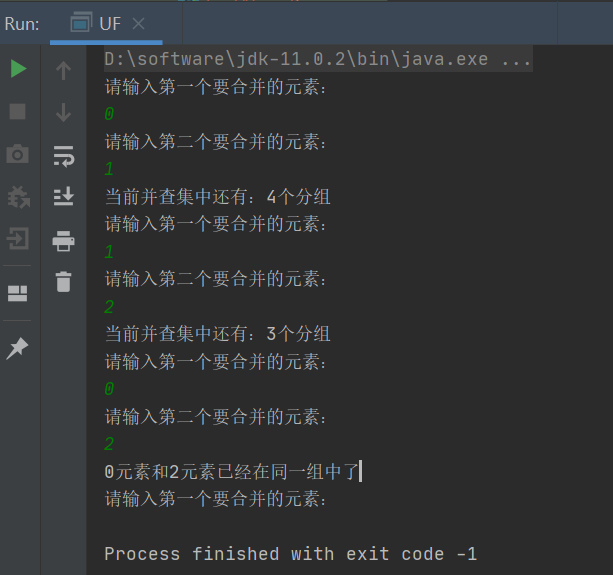
1 package io.guangsoft; 2 3 import java.util.Scanner; 4 5 public class UF { 6 //记录节点元素和该元素所在分组的标志 7 private int[] eleAndGroup; 8 //记录并查集中数据的分组个数 9 private int count; 10 //用来存储每个根节点对应的树中保存的节点的个数 11 private int[] sz; 12 //初始化并查集,以整数标志(0,N-1)个节点 13 public UF(int n) { 14 //初始化分组数量,默认情况下,有n个分组 15 this.count = n; 16 //初始化eleAndGroup数组 17 this.eleAndGroup = new int[n]; 18 //初始化eleAndGroup中元素及其所在组的标识符,让eleAndGroup数组中的索引作为并查集的每个节点的元素,并且让每个索引处的值(该元素所在组的标识符)就是该索引 19 for(int i = 0; i < eleAndGroup.length; i++) { 20 eleAndGroup[i] = i; 21 } 22 //默认情况下,sz中每个索引处的值都是1 23 for(int i = 0; i < sz.length; i++) { 24 sz[i] = 1; 25 } 26 } 27 //获取当前并查集中有多少分组 28 public int count() { 29 return this.count; 30 } 31 //元素p所在分组的标识符 32 public int find(int p) { 33 while(true) { 34 if(p == eleAndGroup[p]) { 35 return p; 36 } 37 p = eleAndGroup[p]; 38 } 39 } 40 //判断并查集中元素p和元素q是否在同一分组 41 public boolean connected(int p, int q) { 42 return find(p) == find(q); 43 } 44 //把p元素所在分组和q元素所在分组合并 45 public void union(int p, int q) { 46 //找到p元素和q元素所在分组对应的树的根节点 47 int pRoot = find(p); 48 int qRoot = find(q); 49 //如果p和q已经在同一分组,则不需要合并了 50 if(pRoot == qRoot) return; 51 //判断pRoot对应的树大还是qRoot对应的树大,最终需要把较小的树合并到较大的树中 52 if(sz[pRoot] < sz[qRoot]) { 53 eleAndGroup[pRoot] = qRoot; 54 sz[qRoot] += sz[pRoot]; 55 } else { 56 eleAndGroup[qRoot] = pRoot; 57 sz[pRoot] += sz[qRoot]; 58 } 59 //组的数量-1 60 this.count--; 61 } 62 //主类 63 public static void main(String args[]) { 64 //创建并查集对象 65 UF uf = new UF(5); 66 //从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中分组是否减少 67 Scanner sc = new Scanner(System.in); 68 while(true) { 69 System.out.println("请输入第一个要合并的元素:"); 70 int p = sc.nextInt(); 71 System.out.println("请输入第二个要合并的元素:"); 72 int q = sc.nextInt(); 73 //判断两个元素是否在同一组中了 74 if(uf.connected(p, q)) { 75 System.out.println(p + "元素和" + q + "元素已经在同一组中了"); 76 continue; 77 } 78 uf.union(p, q); 79 System.out.println("当前并查集中还有:" + uf.count() + "个分组"); 80 } 81 } 82 }
四、算法分析
在我们使用 Quick Union 版本的并查集使用树形结构来组织节点的关系。那么性能跟树的深度有关系,简称 O(h),以前介绍二分搜索树的时候,时间复杂度也是为 O(h)。但是并查集并不是一个二叉树,而是一个多叉树,所以并查集的查询和合并时间复杂度并不是O(log n),在加上rank和路径压缩优化后 ,并查集的时间复杂度为 O(log* n)