自学python的爬虫scrapy,可能会遇到如下问题:
通过上文解释对豆瓣网进行抓取过程中出现报错如下:
2020-08-20 14:27:46 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-08-20 14:27:47 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://movie.douban.com/top250> (referer: None)
2020-08-20 14:27:47 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://movie.douban.com/top250>: HTTP status code is not handled or not allowed
2020-08-20 14:27:47 [scrapy.core.engine] INFO: Closing spider (finished)
这是因为豆瓣服务器自带伪装防爬虫,解决办法如下:
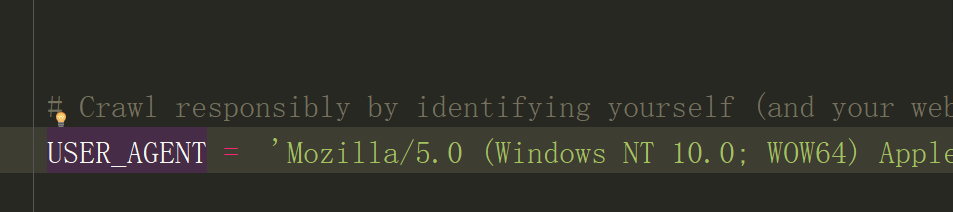
1.打开pycharm,找到douban-->spiders-->setting.py-->USER_AGENT

2.这并不是一个标准的USER_AGENT,把里面内容删除,需要修改为豆瓣网的USER_AGENT
3.打开豆瓣网https://movie.douban.com/top250,按下F12查看网页代码
4.按下F5进行刷新,找到network-->top250(左键单击)-->User_Agent(在底部)复制后面长串

5.粘贴到刚才的setting.py-->USER_AGENT的引号里面,保存
6.最关键的一步,#USER_AGENT前面有一个#,表示注释,此时我们需要运行它,所以将#删去(字体变亮),保存
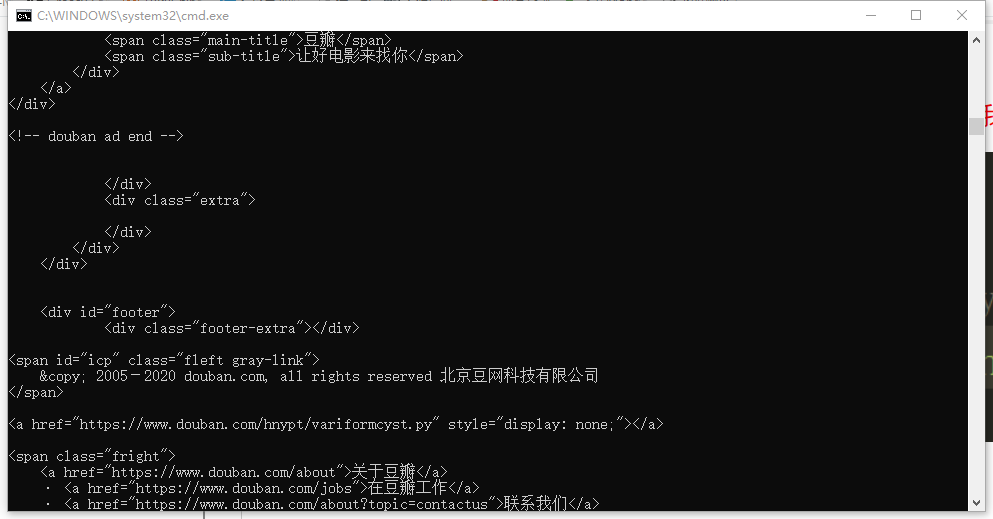
7.在cmd执行程序下cd douban 然后scrapy crawl douban_spider回车,出现下面界面即为成功
希望能帮到大家,问你们要一个赞,你们会给吗,谢谢大家
版权声明:本文版权归作者(@攻城狮小关)和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
大家写文都不容易,请尊重劳动成果~
交流加Q:1909561302
CSDN地址https://blog.csdn.net/Mumaren6/