关于 MHA:
1.Master HA,对主节点进行监控,可实现自动故障转 移至其它从节点;通过提升某一从
节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多
从的架构,要搭建MHA,要求一个复制集群中必须最少有 三台数据库服务器,一主二从,
即一台充当master,一台充当备用master,另外一台充当从库,如果财大气粗,也
可以用一台专门的服务器来当MHA监控管理服务器
2.MHA工作原理
1 从宕机崩溃的master保存二进制日志事件(binlog events)
2 识别含有最新更新的slave
3 应用差异的中继日志(relay log)到其他的slave
4 应用从master保存的二进制日志事件(binlog events)
5 提升一个slave为新的master
6 使其他的slave连接新的master进行复制
注意:MHA需要基于ssh,key验证登入方法 
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
1.Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
2.Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
环境设定
base2 172.25.78.12 主master,MHA manager
base3 172.25.78.13 备用master
base4 172.25.78.14 slave
1.先搭建一主二从环境
# 在base2上
[root@base2 ~]# vim /etc/my.cnf
server-id=1
gtid_mode=ON
enforce-gtid-consistency=true
log_bin = binlog
log_slave_updates=ON
[root@base2 ~]# systemctl start mysqld
[root@base2 ~]# mysql -p
Enter password:
mysql> grant replication slave on *.* to repl@'172.25.78.%' identified by 'Ting@666';
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_master_enabled=1;
mysql> SET GLOBAL rpl_semi_sync_master_timeout=1000000000000;
mysql> show variables like '%rpl%';
mysql> show status like '%rpl%';
mysql> QUIT
Bye
# 在base3上
[root@base3 ~]# vim /etc/my.cnf
server_id=2
gtid_mode =ON
enforce-gtid-consistency=true
log_bin = binlog
log_slave_updates=ON
[root@base3 ~]# systemctl start mysqld
[root@base3 ~]# mysql -p
Enter password:
mysql> stop slave;
mysql> change master to master_host='172.25.78.12',master_user='repl',master_password='Ting@666',MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_master_enabled=1;
mysql> stop slave io_thread;
mysql> start slave io_thread;
mysql> show slave statusG;
mysql> stop slave io_thread;
mysql> start slave io_thread;
mysql> show slave statusG;
如果出现了以下情况

#解决方案:
base2:
mysql> reset master;
base3:
mysql> stop slave;
mysql> start slave;
mysql> quit
Bye
# 在base4上
[root@base4 ~]# vim /etc/my.cnf
server_id=3
gtid_mode=ON
enforce-gtid-consistency=true
log_slave_updates=ON
log_bin=binlog 
[root@base4 ~]# systemctl start mysqld
mysql> stop slave;
mysql> change master to master_host='172.25.78.12',master_user='repl',master_password='Ting@666',MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> show slave statusG;
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_master_enabled=1;
mysql> stop slave io_thread;
mysql> start slave io_thread;
mysql> QUIT
Bye
测试主从复制
# 在master上:
mysql> use test;
Database changed
mysql> create table userlist (
-> username varchar(20) not null,
-> password varchar(15) not null);
mysql> insert into userlist values('user1',111);
mysql> insert into userlist values('user2',222);
mysql> select * from userlist;
# 在base3上
mysql> select * from test.userlist;
# 在base4上
mysql> select * from test.userlist;
2.搭建mha架构
1.数据同步(数据一致性逻辑检测)
2.数据架构逻辑
1
2
[root@base2 ~]# ls
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm perl-Mail-Sender-0.8.23-1.el7.noarch.rpm
mha4mysql-manager-0.58.tar.gz perl-Mail-Sendmail-0.79-21.el7.noarch.rpm
mha4mysql-node-0.58-0.el7.centos.noarch.rpm perl-MIME-Lite-3.030-1.el7.noarch.rpm
perl-Config-Tiny-2.14-7.el7.noarch.rpm perl-MIME-Types-1.38-2.el7.noarch.rpm
perl-Email-Date-Format-1.002-15.el7.noarch.rpm perl-Parallel-ForkManager-1.18-2.el7.noarch.rpm
perl-Log-Dispatch-2.41-1.el7.1.noarch.rpm
[root@base2 ~]# yum install -y *.rpm
[root@base2 ~]# ssh-keygen # 做免密
[root@base2 ~]# ssh-copy-id base2
[root@base2 ~]# ssh-copy-id base3
[root@base2 ~]# ssh-copy-id base4
[root@base2 ~]# mkdir /etc/masterha/
[root@base2 ~]# vim /etc/masterha/app1.cnf
[server default]
manager_workdir=/etc/masterha # 设置manager的工作目录
manager_log=/var/log/masterha.log # 设置manager的日志
master_binlog_dir=/var/lib/mysql # 设置master保存binlog的位置
#master_ip_failover_script= /usr/local/bin/master_ip_failover # 设置自动failover时候的切换脚本
#master_ip_online_change_script= /usr/local/bin/master_ip_online_change # 设置手动切换的脚本
password=Ting@666 # 监控用户密码
user=root # 监控用户root
ping_interval=1 # 设置监控主库,发送ping包的间隔,默认3秒,尝试三次没有回应的时候自动进行failover
remote_workdir=/tmp # 设置远端mysql在发生切换时binlog的保存位置
repl_password=Ting@666 # 复制用户密码
repl_user=repl # 复制用户
#report_script=/usr/local/send_report # 设置发生切换后发送的报警的脚本
#secondary_check_script=/usr/local/bin/masterha_secondary_check -s server03 -s server02
#shutdown_script=""
ssh_user=root
[server2]
hostname=172.25.78.12
port=3306
[server3]
hostname=172.25.78.13
port=3306
candidate_master=1
check_repl_delay=0 # 忽略,不检测
# 默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,
因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master
的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程
中一定是新的master
[server4]
hostname=172.25.78.14
port=3306
no_master=1 # 表示base4一直是slave
[root@base3 ~]# yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
[root@base4 ~]# yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
# 免密检测,会报错,彼此之间都要进行检测
[root@base2 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf 
[root@base2 ~]# scp -r .ssh/ base3:
[root@base2 ~]# scp -r .ssh/ base4:
[root@base2 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
# 再次检测,全部ok

# 检测彼此是否复制
[root@base2 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
解决问题
[root@base2 ~]# mysql -p
Enter password:
mysql> grant all on *.* to root@'%' identified by 'Ting@666'; # 创建监控root,给监控用户授权
mysql> quit
有报错,继续解决报错
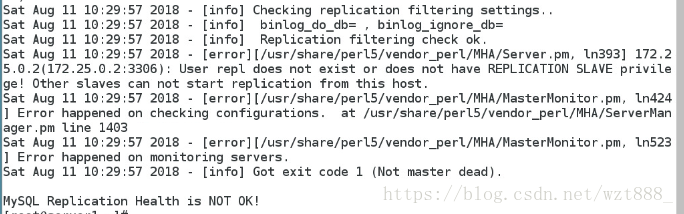
解决方案:在base3和base4上两台slave服务器设置read_only(从库对外提供读服
务,只所以没有写进配置文件,是因为随时slave会提升为master)

# 继续有报错:

解决方案(在base2上):

# 再次检查
[root@base2 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf # 健康检查通过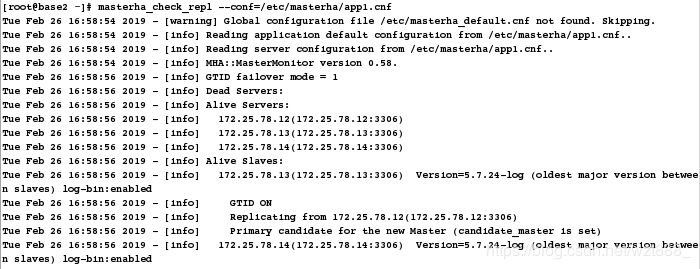

测试高可用
# 1.故障手动切换
[root@base2 masterha]# systemctl stop mysqld # 模拟down掉master
[root@base2 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.78.12 --dead_master_port=3306 --new_master_host=172.25.78.13 --new_master_port=3306 # 在mha服务器上开始手动切换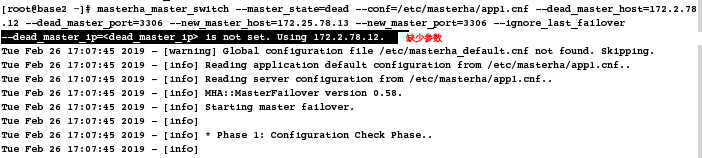
[root@base2 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.2.78.12 --dead_master_port=3306 --new_master_host=172.25.78.13 --new_master_port=3306 --dead_master_ip=172.2.78.12 # 添加上参数之后,继续切换
1
# 2.热切(master是好的,切换master)
热切原理
1. 检查当前的配置信息及主从服务器的信息
包括读取MHA的配置文件/etc/masterha/app1.cnf及检查当前slave的健康状态
2. 阻止对当前master的更新
主要通过如下步骤:
1) 等待1.5s($time_until_kill_threads*100ms),等待当前连接断开。
2> 执行 read_only=1,阻止新的DML操作
3> 等待0.5s,等待当前DML操作完成。
4> kill掉所有连接。
5> FLUSH NO_WRITE_TO_BINLOG TABLES
6> FLUSH TABLES WITH READ LOCK
3. 等待新master执行完所有的relay log
Waiting to execute all relay logs on 192.168.244.20(192.168.244.20:3306)..
4. 将新master的read_only设置为off,并添加VIP
5. slave切换到新master上。
1> 等待slave(192.168.244.30)应用完原主从复制产生的relay log,然后执行change master操作切换到新master上。
2> 释放原master上加的锁。
3> 因masterha_master_switch命令行中带有--orig_master_is_new_slave参数,故原master也切换为新master的从。
6. 清理新master的相关信息。
主要是执行了reset slave all操作,清除之前的复制信息。
[root@base2 ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.78.13 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000


# 在原来的master(base2)上
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST='172.25.78.13',MASTER_PORT=3306, MASTER_AUTO_POSITION=1,MASTER_USER='repl', MASTER_PASSWORD='Ting@666';
mysql> START SLAVE;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
# 在slave(base4)端查看
mysql> show slave statusG;
1
# 在base3上查看
mysql> show slave status;
mysql> show master status;
# 3.自动切
# 在mha上
[root@base2 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &> /dev/null & # 开启监控,并打入后台
# 在master上
[root@base3 ~]# systemctl stop mysqld # 模拟master服务器down掉
# 再在slave上查看master已经切换
mysql> show slave status G;
# 回到mha监控
[root@base2 masterha]# # 已经从后台自动退出
[1]+ Done nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/dev/null 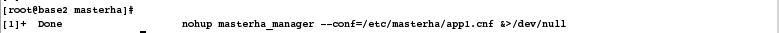
[root@base2 masterha]# pwd
/etc/masterha
[root@base2 masterha]# ls # 并且会生成一个文件
app1.cnf app1.failover.complete
注:默认情况下,MHA发生切换后会在日志目录,也就是上面设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,如果下次想继续进行切换,添加这个参是–ignore_last_failover
# 在原来的master(base3)上
[root@base3 ~]# systemctl start mysqld
[root@base3 ~]# mysql -p
Enter password:
mysql> stop slave;
mysql> CHANGE MASTER TO MASTER_HOST='172.25.78.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='Ting@666'; # 改变自己身份为slave
mysql> start slave;
3.mha实现vip漂移
在mha服务端
[root@base2 ~]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@base2 ~]# cd mha4mysql-manager-0.58
[root@base2 mha4mysql-manager-0.58]# cd samples/
[root@base2 samples]# ls
conf scripts
[root@base2 samples]# cd scripts/
[root@base2 scripts]# ls
master_ip_failover master_ip_online_change power_manager send_report
[root@base2 scripts]# cp master_ip_failover master_ip_online_change /usr/local/bin/
[root@base2 scripts]# cd /usr/local/bin/
[root@base2 bin]# ls
master_ip_failover master_ip_online_change
[root@base2 bin]# vim master_ip_failover
my $vip = '172.25.78.100/24';
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0"; # 注意自己使用的网卡设备名
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0
[root@base2 bin]# vim master_ip_online_change
my $vip = '172.25.78.100/24';
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
my $exit_code = 0;

[root@base2 bin]# chmod 755 *
[root@base2 bin]# vim /etc/masterha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
# 开始测试
[root@base2 ~]# ip addr add 172.25.78.100/24 dev eth0 # 因为base2是,master,所以先手动给master添加Vip
[root@base2 ~]# ip a
# 开始热切换
[root@base2 bin]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.78.13 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000

查看是否切换成功
[root@base3 ~]# ip a # 新master上出现了vip,即vip漂移成功
[root@base2 ~]# ip a # 原master上的vip已经切换
# 实现vip自动漂移
在mha上进行后台监控
[root@base2 bin]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/dev/null &
在master上
[root@base3 ~]# systemctl stop mysqld
[root@base3 ~]# ip a # vip已经飘走
[root@base2 ~]# ip a

# 远程测试
[kiosk@foundation78 Desktop]$ mysql -h 172.25.78.100 -u root -p # 客户端远程登录,vip在哪台服务器上,客户端就登录的是哪台服务器
MySQL [(none)]> select * from test.userlist;
当服务器故障切换时,客户端也会卡顿,无法进行操作
