从SQL Server 2019(15.x)开始,SQL Server大数据群集允许您部署在Kubernetes上运行的SQL Server,Spark和HDFS容器的可伸缩群集。这些组件并排运行,使您能够从Transact-SQL或Spark读取,写入和处理大数据,从而使您可以轻松地将高价值的关系数据与大容量的大数据结合并进行分析。
有关最新版本的新功能和已知问题的更多信息,请参见发行说明。
情境
SQL Server大数据群集为您与大数据进行交互提供了灵活性。您可以查询外部数据源,将大数据存储在SQL Server管理的HDFS中,或通过群集查询来自多个外部数据源的数据。然后,您可以将数据用于AI,机器学习和其他分析任务。以下各节提供有关这些方案的更多信息。
数据虚拟化
通过利用SQL Server PolyBase,SQL Server大数据群集可以查询外部数据源,而无需移动或复制数据。SQL Server 2019(15.x)向数据源引入了新的连接器。
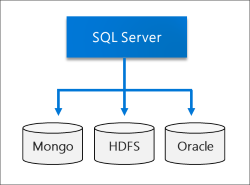
数据湖
SQL Server大数据群集包括一个可伸缩的HDFS 存储池。这可用于存储可能从多个外部源提取的大数据。一旦将大数据存储在大数据集群的HDFS中,您就可以分析和查询数据并将其与关系数据结合起来。
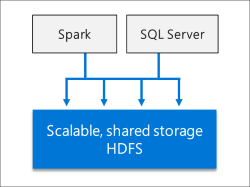
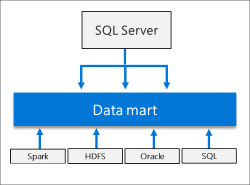
横向扩展数据集市
SQL Server大数据群集提供横向扩展计算和存储,以提高分析任何数据的性能。可以摄取来自各种来源的数据,并将其分布在整个数据池节点中作为缓存进行进一步分析。
集成的AI和机器学习
SQL Server大数据群集可对HDFS存储池和数据池中存储的数据启用AI和机器学习任务。您可以使用R,Python,Scala或Java在SQL Server中使用Spark以及内置的AI工具。

管理与监控
通过命令行工具,API,门户和动态管理视图的组合来提供管理和监视。
您可以使用Azure Data Studio在大数据群集上执行各种任务。新的SQL Server 2019 Extension启用了此功能。该扩展提供:
- 内置的片段,用于常见的管理任务。
- 能够浏览HDFS,上传文件,预览文件和创建目录。
- 能够创建,打开和运行Jupyter兼容的笔记本。
- 数据虚拟化向导可简化外部数据源的创建。
建筑
SQL Server大数据集群是由Kubernetes精心策划的Linux容器集群。
Kubernetes概念
Kubernetes是一个开源的容器编排器,可以根据需要扩展容器的部署。下表定义了一些重要的Kubernetes术语:
| 簇 | Kubernetes集群是一组机器,称为节点。一个节点控制群集,并被指定为主节点。其余节点是工作程序节点。Kubernetes主机负责在工作人员之间分配工作,并监视集群的运行状况。 |
| 节点 | 节点运行容器化的应用程序。它可以是物理机或虚拟机。Kubernetes集群可以包含物理机节点和虚拟机节点的混合体。 |
| 荚 | 吊舱是Kubernetes的原子部署单元。容器是运行一个应用程序所需的一个或多个容器以及相关资源的逻辑组。每个吊舱都在一个节点上运行;一个节点可以运行一个或多个Pod。Kubernetes主节点自动将Pod分配给集群中的节点。 |
在SQL Server大数据群集中,Kubernetes负责SQL Server大数据群集的状态。Kubernetes构建和配置集群节点,将Pod分配给节点,并监视集群的运行状况。
大数据集群架构
下图显示了SQL Server大数据群集的组件。
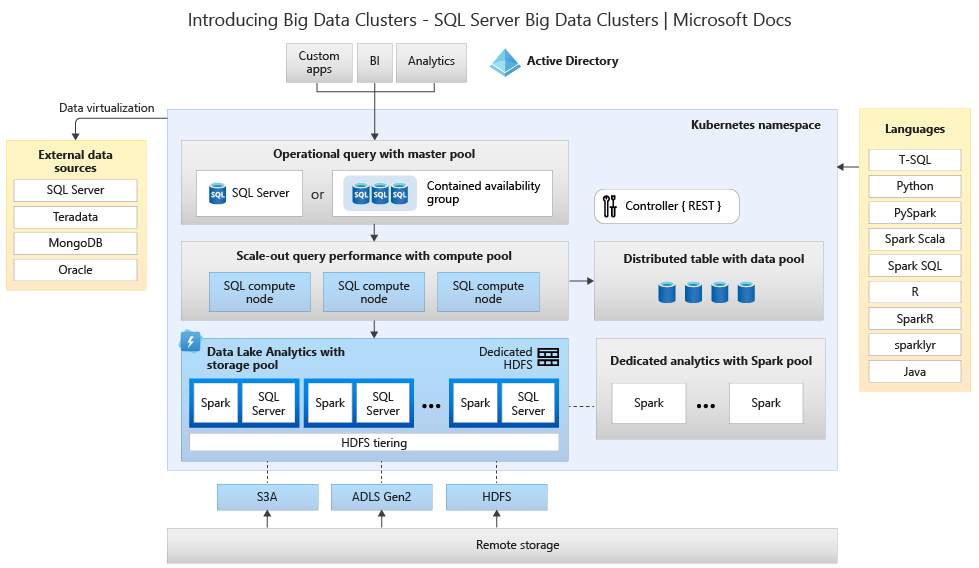
控制者
控制器为群集提供管理和安全性。它包含控制服务,配置存储和其他群集级别的服务,例如Kibana,Grafana和Elastic Search。
计算池
计算池为集群提供计算资源。它包含在Linux Pod上运行SQL Server的节点。计算池中的Pod分为用于特定处理任务的SQL Compute实例。
资料池
数据池用于数据持久性和缓存。数据池由一个或多个在Linux上运行SQL Server的Pod组成。它用于从SQL查询或Spark作业中提取数据。SQL Server大数据群集数据集市保留在数据池中。
储存池
存储池由存储池Pod组成,这些Pod由Linux,Spark和HDFS上的SQL Server组成。SQL Server大数据群集中的所有存储节点都是HDFS群集的成员。