看到夏雪冬日的有关rand()和srand()产生随机数的总结,挺好的,学习了,然后又有百度其他人的成果,系统总结一下。本文转自夏雪冬日:http://www.cnblogs.com/heyonggang/archive/2012/12/12/2814271.html,Peng Lv:http://www.cnblogs.com/lvpengms/archive/2010/02/03/1663066.html#commentform。
要计算机产生一个随机数不像扔色子一样,计算机的每一步操作,就是执行一堆代码,这些代码是事先安排好的,所以计算机的产生行为是不具有随机性和预测性的(当然这里说的是现阶段的计算机体系,到未来的计算机的体系,未知),所以计算机产生的随机数都不是真正意义上的随机数,只是伪随机数,他以一个真值(也称为种子)作为初始条件,然后用一定的算法不停迭代产生随机数。
库函数中系统提供了两个函数用于产生随机数:srand()和rand();
rand函数:
头文件<stdlib.h>
定义函数:int rand(void),
函数功能:产生随机数,
函数说明:因为rand的内部是用线性同余法做的,不是真的随机数,只不过因为其周期特别长,所以在一定范围内可以看成是随机的,rand()会返回一随机值,范围在0到RAND_MAX间,在调用此函数产生随机数前,必须利用srand()设好随机数种子,若没有设随机数种子,rand()在调用时会自动设随机数种子为1。
返回值:返回0到RAND_MAX之间的整数值,RAND_MAX的范围最少在32767之间(int),即双字节(16位)。若unsigned int双字节是65535,且0-RAND_MAX每个数字被选中的随机率是相同的。 rand()产生的是假随机数,每次执行时是相同的,若要不同以不同的值来初始化,初始化的函数就是srand()。
srand函数:
头文件 <stdlib.h> ,
定义函数:void srand(unsigned int seed);
函数声明:srand()用来设置rand()产生随机数时的随机数种子,参数seed必须是整数,通常可以用time(0)的返回值作为seed.如果每次seed都设置相同的值,rand()产生的随机数值每次都一样。
srand(unsigned)time(NULL))使用系统定时/计数器的值作为随机种子每个种子对应一组根据算法预先生成的随机数,所以在相同平台的环境下,不同时间产生的随机数是不同的,相应的若将srand(unsigned)tima(NULL)改为任一常量,则无论何时运行,运行多少次得到的随机数都是一组特定的序列,所以srand生成的随机数是伪随机数。但是,所谓的“伪随机数”指的并不是假的随机数,其实绝对的对技术只是一种假想状态的随机数,计算机只能生成相对的随机数,而这些随机数既是随机的又是有规律的,一部分遵守一定规律,一部分则不遵守任何规律,总结来说就是:计算机产生伪随机数而不是绝对的随机数 (注:该内容来自:百度百科-rand函数)
在每次产生随机序列前,先指定不同的种子,这样计算出来的随机序列就不完全相同了,而使用同种子相同的数调用rand()会导致相同的随机数序列被生成。
例:
产生0到100之间的随机数:
#include <stdlib.h> #include <stdio.h> #include <time.h> main() { int i,k; srand( (unsigned)time( NULL ) ); for( i = 0; i < 10;i++ ) { k=rand()%100+1; //rand()%100表示取100以内的随机数,即取了随机数后再对100取余 x=rand()%(Y-X+1)+X printf( " k=%d ", k ); } }
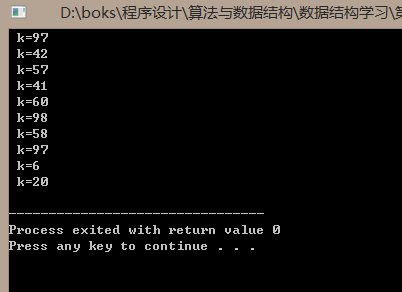
由于rand产生的随机数是0到rand_max,而rand_max是一个很大的数,那么要产生一个从X到Y的随机数,可以这样:s=rand()%(x-Y+1)+Y,这表示从X到Y范围内的随机数
系统在调用rand()之后就自动调用srand(),如果用户在rand()之前调用srand()给参数seed指定一个值,那么rand()就会将seed的值作为产生伪随机数的初始值,如果用户在rand()前没有调用srand(),系统会默认将1作为伪随机数的初始值,如果给了一个定值,每次rand()产生的随机数序列就一样了,所以为了避免发生上述情况,通常用srand((unsigned)time(0))或者srand((unsigned)time(NULL))来产生种子,如果觉得时间间隔太小,可以在(unsigned)time(0)或者(unsigned)time(NULL)后面乘以某个合适值,如srand((unsigned)time(NULL)*10)。
另外,还可以通过 j=(int)(n*rand()/RAND_MAX+1),用来产生0到N之间的整数:
#include<stdio.h> #include<time.h> #include<stdlib.h> int main(void) { int i,j; for(i=0;i<10;i++) { j=1+(int)(10*rand()/(RAND_MAX+1)); printf("%d ",j); } printf(" "); return 0; }
产生随机数:
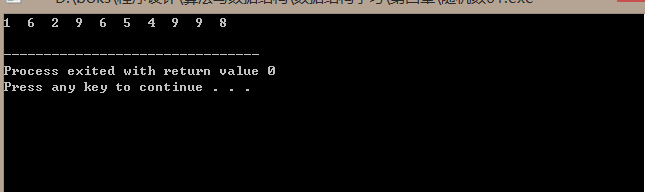
关于int x = rand() % n和 j=(int)(n*rand()/(RAND_MAX+1.0))的问题:
j=(int)(n*rand()/(RAND_MAX+1.0))就是随机一个0到n之间不包括n的浮点数,然后强制转换为就是0到9之间的整数了,这个跟x = rand() % n不同的地方就是,在多次随机出来的结果,前者理论更平均一些,后者只是和n求余得到的结果,没有前面的平均。
取模操作%是为了避免在某些情况下,某些伪随机数生成器产生的数,低位不够随机的问题,这里涉及到二进制问题,因为取模在二进制意义上可能代表取得低位。
不过在针对自己的需要下,随机数可以满足所需的情况下,int x = rand() % n是完全可以代替j=(int)(n*rand()/(RAND_MAX+1.0)),毕竟前者的时间性能要好。
rand函数是真正的随机数生成器,而srand()会设置提供rand()使用的随机数种子。如果第一次调用rand()之前没有调用srand(),那么系统会为你自动调用srand()。如下程序:
#include <stdlib.h> #include <stdio.h> #include <time.h> main() { int i,k; for( i = 0; i < 10;i++ ) { k=rand()%100+1; //rand()%100表示取100以内的随机数,即取了随机数后再对100取余 x=rand()%(Y-X+1)+X printf( " k=%d ", k ); } }
一样可以产生0到100间的随机数。
另外,srand这个函数要放到循环外面,或者循环调用的外面,否则调用得到的是相同的数字。看下面例子:
#include<time.h> #include<stdlib.h> #include<stdio.h> main() { int i,j; for(i=0;i<10;i++) { srand((int)time(0)); j=1+int(rand()*100.0/(RAND_MAX+1.0)); printf("%d ",j); } }
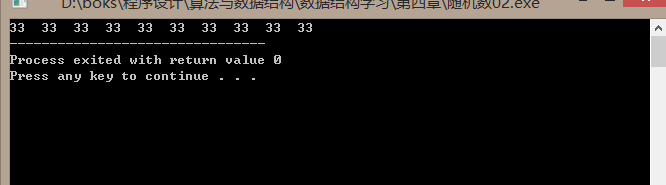
在执行结束后,会发现所有a[i]是一样的,srand放在循环里面,每产生一个随机数之前,都调用srand,由于计算机运行很快,这段代码总共执行不到1s,而srand()返回是以秒为单位,所以每次用time得到时间都是一样的,这相当于使用同一个种子产生产生随机序列,所以每次产生的随机数相同,于是出现所有a[i]是一样的,应该把srand放在循环外面。
如果计算伪随机数序列的初始值(种子)相同,那么计算出来的伪随机序列也完全相同,这个特性被有些软件加密解密,加密时,用某个种子生产一个伪随机数序列对数据进行处理;解密时,再利用种子数生产一个伪随机序列对加密数据进行还原。(详见:http://www.cnblogs.com/heyonggang/archive/2012/12/12/2814271.html)