一、HBase有哪些基本的特征
HBase是类似于google的bigtable的开源实现,拥有以下特征:
(1)、在HDFS之上
(2)、 基于列存储的分布式数据库
(3)、用于实时地读、写大规模数据集
其他HBase的特性:
(1)、没有真正的索引,行顺序存储,也没有所谓的索引膨胀问题。
(2)、自动分区,表增长时,自动分区到新的节点上。
(3)、线性扩展和区域会自动重新平衡,运行RegionServer,达到负载均衡的目的。
(4)、容错和普通商用的硬件支持。这点同hadoop类似。
二、HBase相对于关系数据库能解决的问题是什么
其实就是关系数据库与HBase各自的优缺点。
关系数据库的缺憾:
(1)、扩展困难
(2)、 维护复杂
HBase就是解决可伸缩行的问题。通过简单增加节点来获取线性扩展性。不支持SQL。
HBase与RDBMS的区别:
(1)、表的设计:HBase的表可以很高,很宽,可伸缩性很强。而且表的模式是物理存储的直接反映。
(2)、 拓扑: HBase能水平分区并在上千个节点上自动复制。
(3)、 应用形式: 开发者必须承担更多的责任来正确地利用HBase的检索和存储方式。
(4)、 RDBMS 遵循固定的模式,如“科德十二定律和范式规则”,强调事务的“强一致性”、参照完整性、SQL支持、数据的逻辑与物理形式相对独立。等等。适用于中小规模的数据,但对于数据的规模和并发读写方面进行大规模扩展时,RDBMS会性能大大降低,分布式更为困难,因为其需要放弃很多RDBMS的易用的特性。
(5)、HBase适用于上亿、上千亿级的数据,如果是只有上千、上百万级别是数据,传统的RDBMS是更好的选择。HBase需要更多硬件,如果硬件较少,如5个,干不成什么好事。如果从RDBMS移植到HBase,需要消除RDBMS的很多额外特性,如列数据类型、第二索引、事务、高级查询等
三、自动分区
1、Hbase中扩展和负载均衡的基本单元叫做Region。Region本质上是以行键排序的连续存储的区间。如果region太大,系统会自动拆分它,反之,就会把多个region合并,以减少存储文件的数量。
2、Hbase中的region相当于rdbms中的分区范围划分,可被分配到若干个服务器上以达到负载均衡,提供了较强的扩展性。
3、一张表初始的时候只有一台region服务器。当在插入数据时,超过了限定的region大小,系统就会按region中间的那个行键将其拆分为对等大小的子region。
4、Region和region server是多对一的关系,意思就是每一个region只能由一台region服务器加载,每一台region服务器可以同时加载多个region。
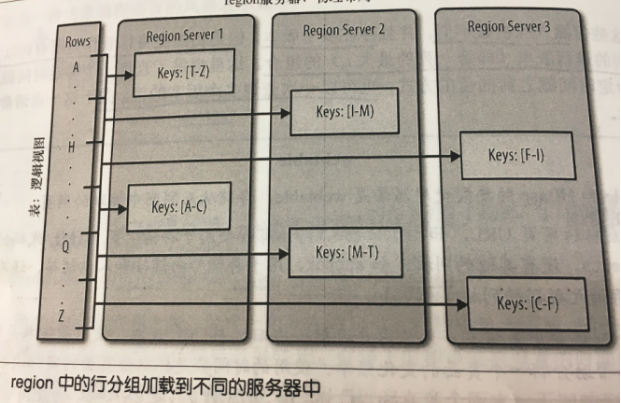
5、每台服务器中的region的最佳加载数量是10~1000,每个region的最佳大小是1~2G。每台服务器能加载的region数量和每个region的最佳存储大小取决于单台服务器的有效处理能力。
6、region拆分和服务相当于其他系统提供的自动分区。当一台服务器出现故障后,该服务器上的region可以快速恢复;当服务于某个region的服务器负载过大、发生错误或者被停止导致该服务器不可使用的时候,系统会将改服务器上的region移到其他服务器上。
7、region的拆分操作几乎是瞬间完成,因为拆分之后的region读取的仍然是原存储文件,直接合并把存储文件异步地写成独立的文件。