问题描述:
在匹配串中寻找模式串,如:
匹配串:THIS IS A SIMPLE EXAMPLE
模式串(搜索词):EXAMPLE
算法1:Brute Force算法(蛮力搜索法)
首先将匹配串和模式串左对齐,然后从左向右一个一个进行比较,如果不成功则模式串向右移动一个单位。
算法2:Karp Rabin算法
模式串:pattern="pappar",长度记为pattern_len
文本串:text="pappappapparrassanuaragh"
预备阶段就是计算pattern的hash,长度为6,那么hash_pattern='p'*2^5+'a'*2^4+'p'*2^3+'p'*2^2+'a'*2^1+'r'*2^0(当然,这里使用的是字符的ascii值)
匹配过程中先计算text前六个字符的hash,我们记第一个为hash_text[0];然后就开始向前移动了,在移动时,要重新计算当前与模式串对应的串的hash值,这个工作叫rehash
算法流程:
(1)初始化 i=0
(2)如果 hash_pattern与hash_text[i]相等,比较字符串内容是否真正相等
(3)如果不等 计算新的hash值,就是text[i..i+patten_len]的hash,当然这里不会像第一次那样全部计算,方法是上一次计算的值减去上一次匹配时串的第一个字符乘以 2^pattern_len ,然后乘以2,再加上新加入比较的字符值。根据公式可以很清晰看出来,就是减去计算中的第一项,把剩下的乘以2,然后在末尾加入新增的字符值

注意,hash函数的好坏会直接影响算法的效率,一般应遵循这样的规则:
1 要容易计算,本文中用的就不错,移位的速度大家是知道的。而且在rehash,就是重新计算hash值时,hash的构造要能避免重新计算整个串的hash,而应该像本例中用到的那样,可以动态地很容易地更新
2 字符串hash值要尽量分布均匀,减少冲突,这是hash函数在任何场合的要求。做到这一点,就能减少匹配中字符的一个个比较,提高性能。如果能够保证每个串的hash值不同,就不用再比较字符了,可以省掉代码中的memcmp运算
参考链接:http://blog.csdn.net/onezeros/article/details/5531354
算法3:KMP算法
前缀:除了最后一个字符以外,一个字符串的全部头部组合
后缀:除了第一个字符以外,一个字符串的全部尾部组合
部分匹配值就是前缀和后缀的最长的共有元素的长度。以"ABCDABD"为例,

对应的部分匹配表:

有了部分匹配表以后,匹配过程如下:
(1)

已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:

因为 6 - 2 等于4,所以将搜索词向后移动4位。
(2)

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为2,于是将搜索词向后移2位。
(3)
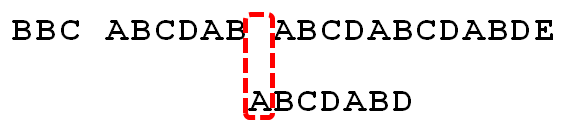
因为空格与A不匹配,继续后移一位。
(4)

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
(5)

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
总结:部分匹配的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
参考链接:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
算法4:Boyer Moore算法
首先,"字符串"与"搜索词"头部对齐,从尾部开始比较。
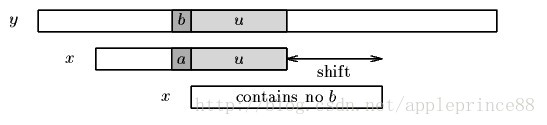
我们看到,"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符。我们还发现,"S"不包含在搜索词"EXAMPLE"之中,这意味着可以把搜索词直接移到"S"的后一位。

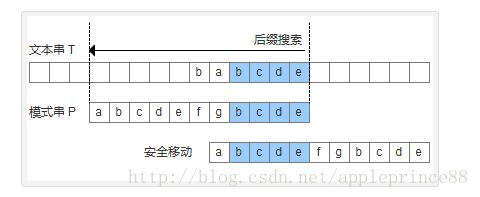
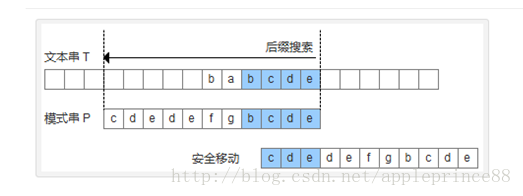
比较前面一位,"MPLE"与"MPLE"匹配。我们把这种情况称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。
坏字符规则:
后移位数 = 坏字符的位置 - 坏字符在搜索词中的上一次出现位置
如果"坏字符"不包含在搜索词之中,则上一次出现位置为 -1。
好后缀规则:
后移位数 = 好后缀的位置 - 好后缀在搜索词中的上一次出现位置
好后缀规则的三个注意点:

Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
坏字符示例:

好后缀示例:
参考链接:
http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
http://blog.csdn.net/appleprince88/article/details/11881323