1,三元表达式
格式:
为真时的结果 if 判定条件 else 为假时的结果
例子:
print(1 if 5>3 else 0) >>> 1
2,递归
递归调用时函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
递归的两个阶段:
回溯:往前搜索,已达到目标 注意:一定要在满足某个条件的情况下结束回溯,否则就是无限递归
递推:往回推
例子:
1 def age(n): 2 if n == 1: 3 return 18 4 else: 5 return age(n-1)+2 6 7 print(age(5))
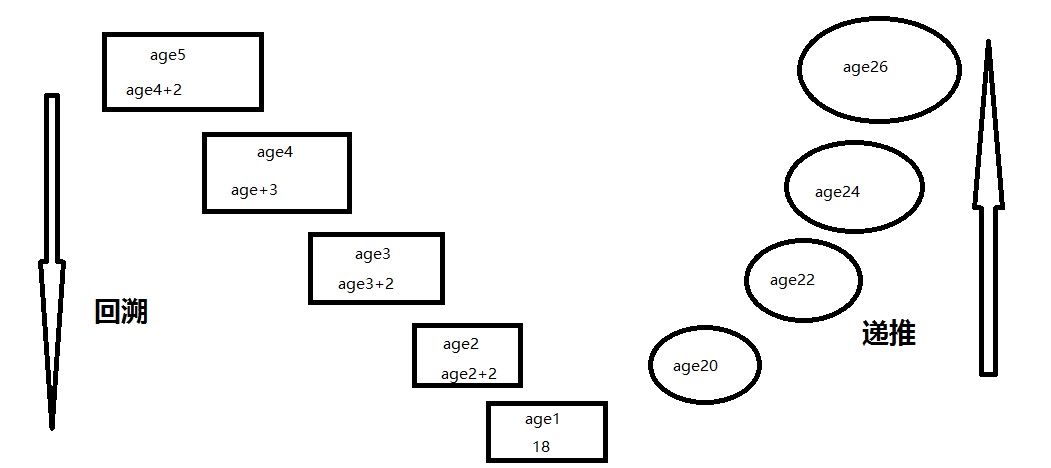
总结:
递归必须有一个明确的结束条件
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
python递归效率低,每次递归都会保留上一次的状态,没有尾递归优化,但是对递归层级做了限制(可以通过 sys.setrecursionlimit 修改)。递归层数过多,会导致内存溢出
3,匿名函数(没有函数名的函数)
常用于:def func(): return 返回值 类似此类的简单函数
lambda 参数 : 返回值
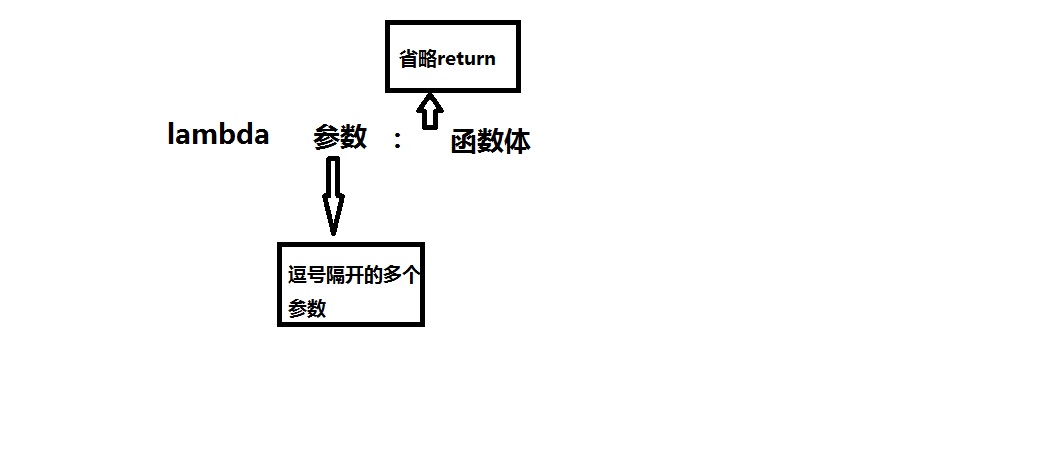
lambda x,y,z=1:x+y+z
#匿名函数与def 定义的函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,除非让其有名字
func = lambda x,y,z=1:x+y+z
func(1,2,3) # 匿名函数让其有名字就失去了匿名函数的意义
匿名函数的函数体通常应该是一个表达式,该表达式必须要有一个返回值
有名函数与匿名函数的对比
有名函数:循环使用,保存了函数名,通过名字就可以重复引用函数功能
匿名函数:一次性使用,随时定义
内置函数(python解释器定义好的函数)
reduce(func,iterable) 从可迭代系列中循环取值,参与第一个函数参数的计算,最后得到一个结果
reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数
bytes()将unicode指定编码后转化为bytes类型
chr()返回值是传入整数对应的ascii字符
divmod()将除数和余数的运算结果结合起来,返回一个包含商和余数的元组(a//b,a%b)
>>>divmod(7, 2) (3, 1) >>> divmod(8, 2) (4, 0) >>> divmod(1+2j,1+0.5j) ((1+0j), 1.5j)
enumerate()将一个可遍历的数据对象组合为一个索引序列,同时列出数据个数据下标,一般用在for循环
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter'] >>> list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
eval()执行一个字符串表达式,并返回表达式的值
>>>x = 7 >>> eval( '3 * x' ) 21 >>> eval('pow(2,2)') 4 >>> eval('2 + 2') 4 >>> n=81 >>> eval("n + 4") 85
filter(func,iterable)函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
import math def is_sqr(x): return math.sqrt(x) % 1 == 0 newlist = filter(is_sqr, range(1, 101)) print(newlist)
id() 返回参数的内存地址序号
input()获取输入
iter(object)生成迭代器
len()返回参数长度
map(func,iterable)第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25] >>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) [3, 7, 11, 15, 19]
max()返回给定参数的最大值,参数可以是系列
egon male 18 3000 alex male 38 30000 wupeiqi female 28 20000 yuanhao female 28 10000 with open('db.txt') as f: items=(line.split() for line in f) info=[{'name':name,'sex':sex,'age':age,'salary':salary} for name,sex,age,salary in items] print(max(info,key=lambda dic:dic['salary'])) max(iterable, key, default) 求迭代器的最大值,其中iterable 为迭代器,max会for i in … 遍历一遍这个迭代器,然后将迭代器的每一个返回值当做参数传给key=func 中的func(一般用lambda表达式定义) ,然后将func的执行结果传给key,然后以key为标准进行大小的判断
min()返回给定参数的最小值,参数可以是系列
ord()返回给定参数的十进制数
>>>ord('a') 97 >>> ord('b') 98 >>> ord('c') 99
sorted()对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
iterable -- 可迭代对象。 cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。 key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
>>>a = [5,7,6,3,4,1,2] >>> b = sorted(a) # 保留原列表 >>> a [5, 7, 6, 3, 4, 1, 2] >>> b [1, 2, 3, 4, 5, 6, 7] >>> L=[('b',2),('a',1),('c',3),('d',4)] >>> sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) # 利用cmp函数 [('a', 1), ('b', 2), ('c', 3), ('d', 4)] >>> sorted(L, key=lambda x:x[1]) # 利用key [('a', 1), ('b', 2), ('c', 3), ('d', 4)] >>> students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)] >>> sorted(students, key=lambda s: s[2]) # 按年龄排序 [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] >>> sorted(students, key=lambda s: s[2], reverse=True) # 按降序 [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)] >>>