生成器的一些补充
接着下鸡蛋和吃包子!
补充一:生成器只能遍历一次
(总是把生成器比喻成母鸡下鸡蛋,需要一个下一个,首先是下出来的鸡蛋不能塞回
母鸡肚子里,其次是一个母鸡一生只能下一定数量的鸡蛋,下完了就死掉了)
#通过程序来理解什么意思 #程序一: def test(): for i in range(2): yield i t = test() for i in t: print(i) t1 =(i for i in t) print(list(t1)) #执行结果 0 1 []
#程序分析 #1.程序开始执行以后,因为test函数中有yield关键字,所以test函数并不会真的执行,而是先得到一个生成器t. #2.for循环遍历生成器t,并打印遍历结果0和1 #3.继续利用for循环遍历生成器t,因为该生成器已经遍历过一次,所有值已经取完,所以这次遍历不会取到任何值,则打印遍历结果为空列表
#程序二:
#实现功能:人口普查,
#功能一:统计 “人口统计” 文件中所有省份的总人数
#功能二:并计算出每一省份人数占总人数的百分比
#人口普查.text文件内容 {'name': '北京', 'population': 100} {'name': '天津', 'population': 999} {'name': '南京', 'population': 750} {'name': '上海', 'population': 870} #程序: def get_population(): with open('人口普查', 'r', encoding = 'utf-8') as f: for i in f: yield i g = get_population() all_population=sum(eval(i)['population'] for i in g) print(all_population) for i in g: single_population = eval(i)['population'] print( single_population / all_population)
#程序分析: #1.程序开始执行以后,因为get_population函数中有yield关键字,所以get_population函数并不会真的执行,而是先得到一个生成器g. #2.all_population=sum(eval(i)['population'] for i in g) 总人数的获取 #对这段代码进行翻译一下 #第一步:通过for循环进行遍历生成器 g,其实就是执行 get_population 函数,打开txet文件,读取每一行内容 #第二步:每一行的内容读出来为字符串类型,通过eval()将字符串转换成字典类型,通过索引进行对每个省人口进行取值 #第三步:通过sum函数,对所取的值进行求和,计算总人口数 #3.通过对生成器g进行遍历,取出每一个省份的人数,并打印百分比
#通过分析,上述程序可实现要求。可运行结果如下: 2719
#只计算出总人数。为什么没有执行第二次遍历?原因就在于计算总人口时已经对生成器g遍历了一次,将值全部取出第二次遍历时,生成器中并没有值,因此也不会取出每一个省份的人数,并打印百分比
#程序改进(遍历时保存取值即可) def get_population(): with open('人口普查', 'r', encoding = 'utf-8') as f: for i in f: yield i g = get_population() s1 = eval(g.__next__())['population'] s2 = eval(g.__next__())['population'] s3 = eval(g.__next__())['population'] s4 = eval(g.__next__())['population'] s = [s1, s2 , s3, s4] all_population = s1 + s2 + s3 + s4 for i in range(4): print(s[i] / all_population) #执行结果 2719 0.036778227289444645 0.367414490621552 0.2758367046708349 0.3199705774181684
虽然功能实现了,可是我认为自己的程序写的实在太蹩脚了
因为没有什么基础,所以只能按照功能区一步一步写
希望之后有是有改进吧
大家对这个程序的实现有什么好的想法可以和我交流一下
补充二:生产消费者模型(本质是对 yield 一个应用)
#以吃包子的列子
#我们去包子铺买包子,肯定是去了店家边做边卖包子
#店家肯定不会让所有人等着,把需要的所有包子都做好,再卖给大家
#最高效率的就是我做一个人的,卖一个人的量
#现做现卖
#我们用程序来模拟这个过程
#吃包子进化理论(我自己胡乱起的名字)
#程序一:(只能实现一个人吃了一个包子) def producer_bun(): c1 = consumer('xhg') c1.__next__() c1.send('猪肉馅儿') def consumer(name): print('我是%s,我准备开始吃包子了'%name) while True: bun = yield print('%s很开心的把%s吃掉了'%(name, bun)) producer_bun() #执行结果 我是xhg,我准备开始吃包子了 xhg很开心的把猪肉馅儿吃掉了
#程序二:(只能实现一个人吃了多个包子) def producer_bun(): c1 = consumer('xhg') c1.__next__() for i in range(3): c1.send('包子%s'%i) def consumer(name): print('我是%s,我准备开始吃包子了'%name) while True: bun = yield print('%s很开心的把%s吃掉了'%(name, bun)) producer_bun() #执行结果 我是xhg,我准备开始吃包子了 xhg很开心的把包子0吃掉了 xhg很开心的把包子1吃掉了 xhg很开心的把包子2吃掉了
#最终版完美吃包子程序 def producer_bun(): c1 = consumer('xhg1') c2 = consumer('xhg2') c1.__next__() c2.__next__() for i in range(3): c1.send('包子%s'%i) c2.send('包子%s' % i) def consumer(name): print('我是%s,我准备开始吃包子了'%name) while True: bun = yield print('%s很开心的把%s吃掉了'%(name, bun)) producer_bun()
设置断点,可以清楚的帮我们分析程序的执行过程。以此来充分理解yield的作用。
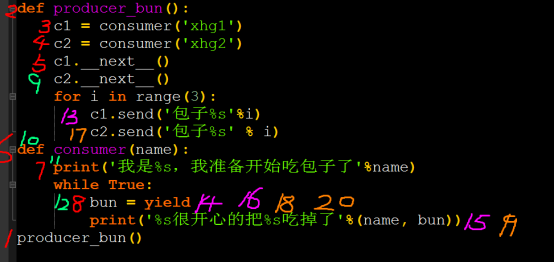
数字代表程序执行步骤
通过yield实现两个函数之间的切换
其中send函数作用同next函数
send()的两个功能:1.传值;2.next()。