一 Event对象
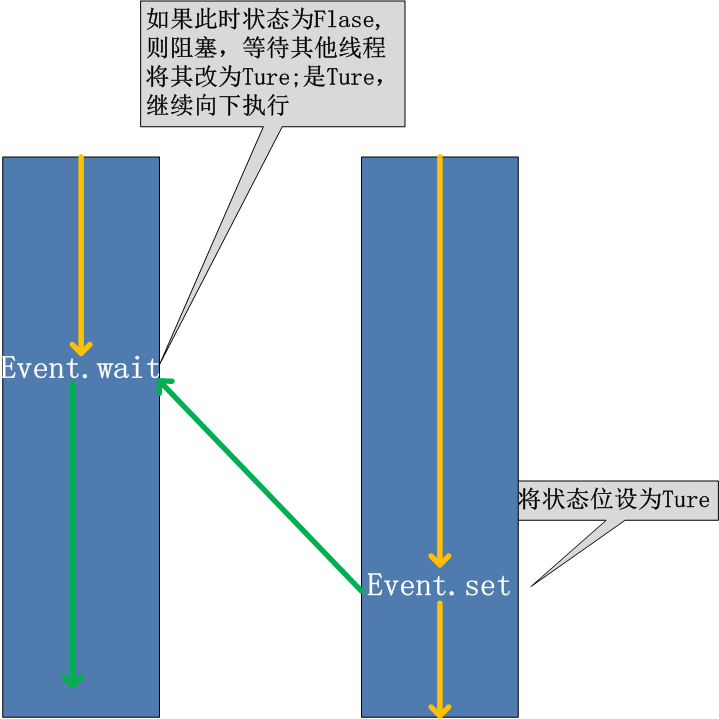
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就 会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行

event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
可以考虑一种应用场景(仅仅作为说明),例如,我们有多个线程从Redis队列中读取数据来处理,这些线程都要尝试去连接Redis的服务,一般情况下,如果Redis连接不成功,在各个线程的代码中,都会去尝试重新连接。如果我们想要在启动时确保Redis服务正常,才让那些工作线程去连接Redis服务器,那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作:主线程中会去尝试连接Redis服务,如果正常的话,触发事件,各工作线程会尝试连接Redis服务。
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',)
def worker(event):
logging.debug('Waiting for redis ready...')
event.wait()
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
def main():
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1')
t1.start()
t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2')
t2.start()
logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event')
time.sleep(3) # simulate the check progress
readis_ready.set()
if __name__=="__main__":
main()
threading.Event的wait方法还接受一个超时参数,默认情况下如果事件一致没有发生,wait方法会一直阻塞下去,而加入这个超时参数之后,如果阻塞时间超过这个参数设定的值之后,wait方法会返回。对应于上面的应用场景,如果Redis服务器一致没有启动,我们希望子线程能够打印一些日志来不断地提醒我们当前没有一个可以连接的Redis服务,我们就可以通过设置这个超时参数来达成这样的目的:
def worker(event):
while not event.is_set():
logging.debug('Waiting for redis ready...')
event.wait(2)
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
这样,我们就可以在等待Redis服务启动的同时,看到工作线程里正在等待的情况。
二 队列(queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1.1 get与put方法
''' 创建一个“队列”对象 import Queue q = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数 maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。 将一个值放入队列中 q.put(10) 调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值; 第二个block为可选参数,默认为 1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0, put方法将引发Full异常。 将一个值从队列中取出 q.get() 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且 block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。 '''
1.2 join与task_done方法
'''
join() 阻塞进程,直到所有任务完成,需要配合另一个方法task_done。
def join(self):
with self.all_tasks_done:
while self.unfinished_tasks:
self.all_tasks_done.wait()
task_done() 表示某个任务完成。每一条get语句后需要一条task_done。
import queue
q = queue.Queue(5)
q.put(10)
q.put(20)
print(q.get())
q.task_done()
print(q.get())
q.task_done()
q.join()
print("ending!")
'''
1.3 其他常用方法
''' 此包中的常用方法(q = Queue.Queue()):
q.qsize() 返回队列的大小 q.empty() 如果队列为空,返回True,反之False q.full() 如果队列满了,返回True,反之False q.full 与 maxsize 大小对应 q.get([block[, timeout]]) 获取队列,timeout等待时间 q.get_nowait() 相当q.get(False)非阻塞
q.put(item) 写入队列,timeout等待时间 q.put_nowait(item) 相当q.put(item, False) q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号 q.join() 实际上意味着等到队列为空,再执行别的操作 '''
1.4 其他模式
'''
Python Queue模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)
import queue
#先进后出
q=queue.LifoQueue()
q.put(34)
q.put(56)
q.put(12)
#优先级
q=queue.PriorityQueue()
q.put([5,100])
q.put([7,200])
q.put([3,"hello"])
q.put([4,{"name":"alex"}])
while 1:
data=q.get()
print(data)
'''
1.5 生产者消费者模型
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不需要不找厨师,直接去前台领取即可,这也是一个结耦的过程。
import time,random
import queue,threading
q = queue.Queue()
def Producer(name):
count = 0
while count <10:
print("making........")
time.sleep(random.randrange(3))
q.put(count)
print('Producer %s has produced %s baozi..' %(name, count))
count +=1
#q.task_done()
#q.join()
print("ok......")
def Consumer(name):
count = 0
while count <10:
time.sleep(random.randrange(4))
if not q.empty():
data = q.get()
#q.task_done()
#q.join()
print(data)
print('�33[32;1mConsumer %s has eat %s baozi...�33[0m' %(name, data))
else:
print("-----no baozi anymore----")
count +=1
p1 = threading.Thread(target=Producer, args=('A',))
c1 = threading.Thread(target=Consumer, args=('B',))
# c2 = threading.Thread(target=Consumer, args=('C',))
# c3 = threading.Thread(target=Consumer, args=('D',))
p1.start()
c1.start()
# c2.start()
# c3.start()
三 multiprocessing模块
Multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency,effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine. It runs on both Unix and Windows.
由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。
multiprocessing包是Python中的多进程管理包。与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程。该进程可以运行在Python程序内部编写的函数。该Process对象与Thread对象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类 (这些对象可以像多线程那样,通过参数传递给各个进程),用以同步进程,其用法与threading包中的同名类一致。所以,multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的情境。
3.1 python的进程调用
# Process类调用
from multiprocessing import Process
import time
def f(name):
print('hello', name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = Process(target=f, args=('alvin:%s'%i,))
p_list.append(p)
p.start()
for i in p_list:
p.join()
print('end')
# 继承Process类调用
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self):
super(MyProcess, self).__init__()
# self.name = name
def run(self):
print ('hello', self.name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = MyProcess()
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('end')
3.2 process类
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group: 线程组,目前还没有实现,库引用中提示必须是None;
target: 要执行的方法;
name: 进程名;
args/kwargs: 要传入方法的参数。
实例方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样
name:进程名字。
pid:进程号。
from multiprocessing import Process
import os
import time
def info(name):
print("name:",name)
print('parent process:', os.getppid())
print('process id:', os.getpid())
print("------------------")
time.sleep(1)
def foo(name):
info(name)
if __name__ == '__main__':
info('main process line')
p1 = Process(target=info, args=('alvin',))
p2 = Process(target=foo, args=('egon',))
p1.start()
p2.start()
p1.join()
p2.join()
print("ending")
通过tasklist(Win)或者ps -elf |grep(linux)命令检测每一个进程号(PID)对应的进程名