不同磁力链网站网页内容都不同,需要定制
1,并发爬取
并发爬取后,好像一会就被封了
import requests
from lxml import etree
import re
from concurrent.futures import ThreadPoolExecutor
def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None
def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]')
def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass
with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows)
return res
def get_urls(baseurl, headers, suffix=None):
"""输入搜索网页,递归获取所有页的搜索结果"""
if suffix:
url = baseurl + suffix
else:
url = baseurl
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
page_suffixes = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="numbar"]/@href')
# 有时该站会返回/search/.../search/...search/.../page,需要处理下
p = r'/search/[^/]+/page/d+(?=D|$)'
page_suffixes = [re.search(p, i).group() for i in page_suffixes]
# 如果还有下一页,需要进一步递归查询获取
r = requests.get(url + page_suffixes[-1], headers=headers)
select = etree.HTML(r.text)
next_page = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="nextpage"]/@href')
if next_page:
page_suffixes = page_suffixes + get_urls(baseurl, headers, next_page[0])
return page_suffixes
if __name__ == '__main__':
keyword = "金刚狼3"
baseurl = 'https://btsow.club/search/{}'.format(keyword) # 该站是采用get方式提交搜索关键词
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"}
urls = get_urls(baseurl, headers)
new_urls = list(set(urls))
new_urls.sort(key=urls.index)
new_urls = [baseurl + i for i in new_urls]
with ThreadPoolExecutor() as executor:
res = executor.map(get_page_mlinks, new_urls, [headers for i in range(7)])
for r in res:
for i in r:
print(i)
2,逐页爬取
手工输入关键词和页数
超过网站已有页数时,返回None
爬取单个搜索页中所有磁力链时,仍然用的是并发
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None
def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]')
def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass
with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows)
return res
if __name__ == '__main__':
keyword = input('请输入查找关键词>> ')
page = input('请输入查找页>> ')
url = 'https://btsow.club/search/{}/page/{}'.format(keyword, page)
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"}
r = get_page_mlinks(url, headers)
for i in r:
print(i)
3,先输入影片,在选择下载哪个磁力链
import requests
from lxml import etree
def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None
def get_row(row):
size = row.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = row.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = row.xpath('.//a/@href')
title = row.xpath('.//a/@title')
try:
return href[0], size[0], date[0], title[0]
except IndexError:
pass
if __name__ == '__main__':
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"}
while True:
keyword = input('请输入查找关键词>> ')
if keyword == 'quit':
break
url = 'https://btsow.club/search/{}'.format(keyword)
r = requests.get(url, headers=headers)
print(r.status_code)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]')
div_rows = [get_row(row) for row in div_rows if get_row(row)]
if not div_rows:
continue
for index, row in enumerate(div_rows):
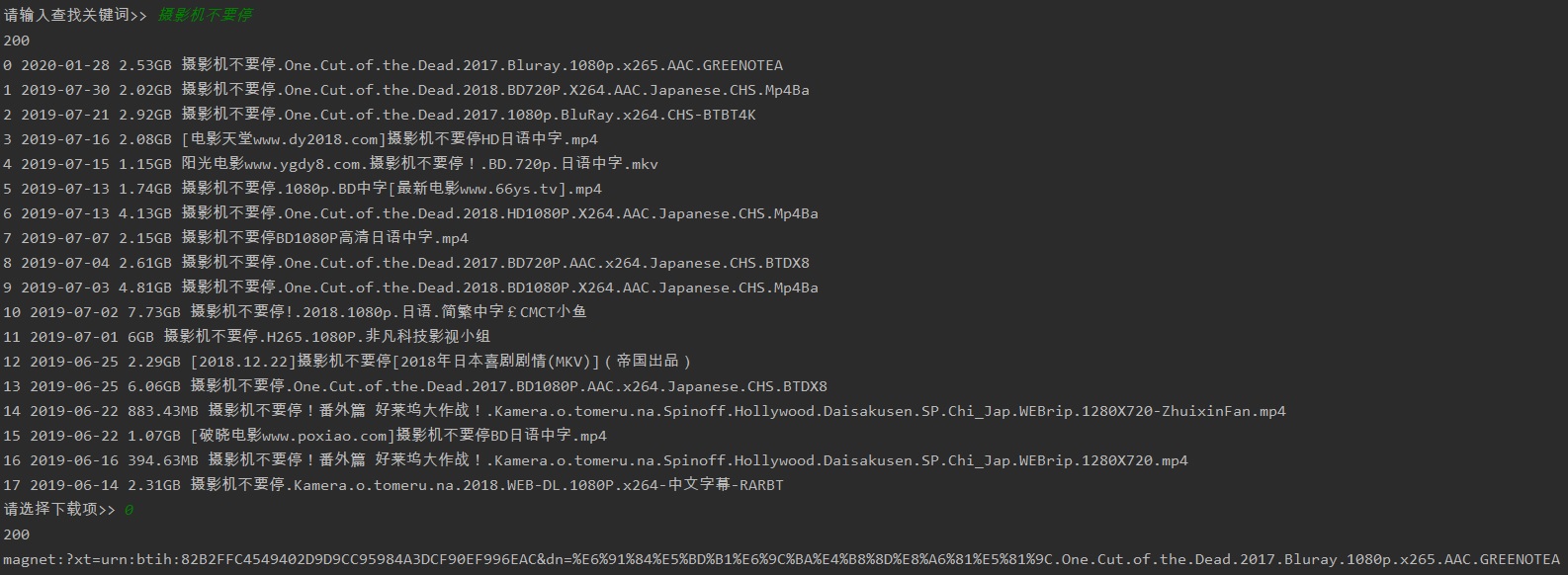
print(index, row[2], row[1], row[3])
# 选择和下载哪部片子
choice = input('请选择下载项>> ')
try: # 如果不是数字,退回到输入关键词
choice = int(choice)
except ValueError:
continue
download_url = div_rows[choice][0]
mlink = get_mlink(download_url, headers)
print(r.status_code)
print(mlink)
print('
')
执行效果:
4,补充下lxml的使用
<div class="item" data-houseid="*****">
*************************************************************
</div>
<div class="item" data-houseid="107102426781">
<a class="img" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">
<img class="lj-lazy" src="https://s1.ljcdn.com/feroot/pc/asset/img/blank.gif?_v=20200428212347" data-original="https://image1.ljcdn.com/110000-inspection/pc1_JZKtMEOU3_1.jpg.296x216.jpg.437x300.jpg">
<div class="btn-follow follow" data-hid="107102426781"><span class="star"></span><span class="follow-text">关注</span></div>
<div class="leftArrow"><span></span></div>
<div class="rightArrow"><span></span></div><div class="price"><span>375</span>万</div>
</a>
<a class="title" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">临河位置,全明户型带边窗,满五年唯一,拎包入住</a>
<div class="info">
御桥
<span>/</span>
2室1厅
<span>/</span>
50.11平米
<span>/</span>
南
<span>/</span>
精装
</div>
<div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div>
</div>
<div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div> </div>
<div class="item" data-houseid="*****">
*************************************************************
</div>
要获取所有房源tilte,价格,朝向,装修情况等,可以:
elements = select.xpath('//div[@class="item"]') # 所有房源组成的items列表,即所有class='item'的div标签
for element in elements:
title = element.xpath('a[@class="title"]/text()')[0] # class='item'的div标签下,所有class='title'的a标签
price = element.xpath('a[@class="img"]/div[@class="price"]/span/text()')[0]
_, scale, size, orient, deco = element.xpath('div[@class="info"]/text()')
print(title, price, scale, size, orient, deco)
输入某小区的结果:
中间楼层+精装保养好+满两年+双轨交汇+诚意出售 385 2室1厅 62.7平米 南 精装 南北通风,户型方正,楼层佳位置佳,11/18号线双轨 368 2室1厅 52.49平米 南 精装 一手动迁 业主置换 急售 双南采光佳 看房方便 370 2室1厅 62.7平米 南 简装 临河位置,全明户型带边窗,满五年唯一,拎包入住 375 2室1厅 50.11平米 南 精装 一手动迁,税费少,楼层采光好,精装修。 388 2室1厅 62.7平米 南 精装 南北通两房 近地铁 拎包入住 业主诚意出售 508 2室2厅 90.88平米 南 其他