-
过程
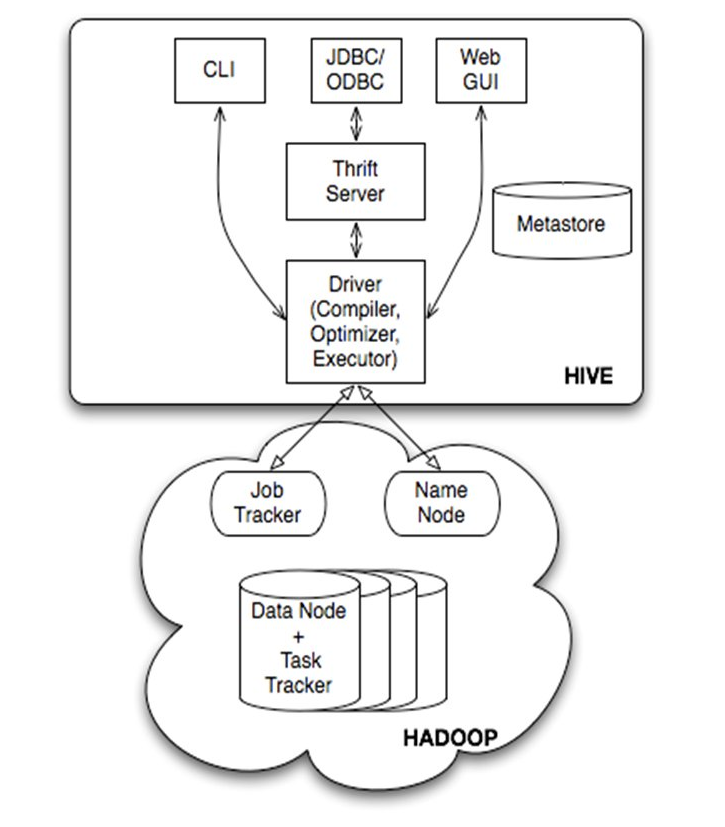
- 启动 hive 之后出现的 CLI 是查询任务的入口,CLI 提交任务给 Driver
- Driver 接收到任务后调用 Compiler,Executor,Optimizer 将 SQL 语句转化为可以在 Hadoop 集群上执行的 MapReduce 任务
- Compiler,Executor 从 metastore 获取所需要的元数据信息
- hivesever2 作为 hivesever 的改进版本,最主要的变化在于提供了全新的命令行窗口 BeeLine。
-
gateway
CDH中的gateway
实际为在client测的一个代理,用于协助将Hive执行时所需要的配置文件部署到Hive的客户端。
-
metadata
元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
-
HiveServer1
-
-
HiveServer1
-
HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果。HiveServer是建立在Apache ThriftTM(http://thrift.apache.org/) 之上的,因此有时会被称为Thrift Server,这可能会导致混乱,因为新服务HiveServer2也是建立在Thrift之上的.自从引入HiveServer2后,HiveServer也被称为HiveServer1。
HiveServer无法处理来自多个客户端的并发请求.这实际上是HiveServer导出的Thrift接口所施加的限制,也不能通过修改HiveServer源代码来解决。
HiveServer2对HiveServer进行了重写,来解决这些问题,从Hive 0.11.0版本开始。建议使用HiveServer2。
从Hive1.0.0版本(以前称为0.14.1版本)开始,HiveServer开始被删除。请切换到HiveServer2。
-
-
HiveServer2
-
HiveServer2(HS2)是一种能使客户端执行Hive查询的服务。 HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃。HiveServer2可以支持多客户端并发和身份认证。旨在为开放API客户端(如JDBC和ODBC)提供更好的支持。
HiveServer2单进程运行,提供组合服务,包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI的Jetty Web服务器。