原文:https://www.cnblogs.com/denny402/p/7520063.html
原文:https://www.jianshu.com/p/84f72791806f
原文:https://blog.csdn.net/lee813/article/details/89609691
1、下载fashion-mnist数据集
地址:https://github.com/zalandoresearch/fashion-mnist
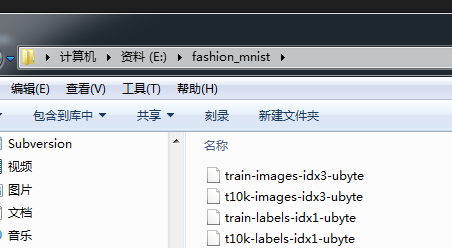
下面这四个都要下载,下载完成后,解压到同一个目录,我是解压到“E:/fashion_mnist/”这个目录里面,好和下面的代码目录一致

2、在Geany中执行下面这段代码。
这段代码里面,需要先用pip安装skimage、torch、torchvision,前两篇文章有安装步骤。
这段代码的作用:将下载下来的 二进制文件 转换为 图片,会在目录中生成两个文件夹和两个文本。
文件夹里面全是图片,图片的内容是数字,N多数字。
文本的内容主要是图片和真实数字的一个关联。


import os from skimage import io import torchvision.datasets.mnist as mnist root="E:/fashion_mnist/" train_set = ( mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte')) ) test_set = ( mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte')) ) print("training set :",train_set[0].size()) print("test set :",test_set[0].size()) def convert_to_img(train=True): if(train): f=open(root+'train.txt','w') data_path=root+'/train/' if(not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(train_set[0],train_set[1])): img_path=data_path+str(i)+'.jpg' io.imsave(img_path,img.numpy()) f.write(img_path+' '+str(label)+' ') f.close() else: f = open(root + 'test.txt', 'w') data_path = root + '/test/' if (not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(test_set[0],test_set[1])): img_path = data_path+ str(i) + '.jpg' io.imsave(img_path, img.numpy()) f.write(img_path + ' ' + str(label) + ' ') f.close() convert_to_img(True) convert_to_img(False)
3、原文的这段代码编译会出错,主要是跟下载的数据有关,数据格式不一样,这里还在处理,原因是找到了的,就一个int的转换,下面贴出改过后的代码
出错的地方:


import torch import re import numpy from torch.autograd import Variable from torchvision import transforms from torch.utils.data import Dataset, DataLoader from PIL import Image root="E:/fashion_mnist/" def default_loader(path): return Image.open(path).convert('RGB') class MyDataset(Dataset): def __init__(self, txt, transform=None, target_transform=None, loader=default_loader): fh = open(txt, 'r') imgs = [] for line in fh: line = line.strip(' ') line = line.rstrip() words = line.split() p1 = re.compile(r'[(](.*?)[)]', re.S) arr = re.findall(p1, words[1]) word = arr[0] imgs.append((words[0],int(word))) self.imgs = imgs self.transform = transform self.target_transform = target_transform self.loader = loader def __getitem__(self, index): fn, label = self.imgs[index] img = self.loader(fn) if self.transform is not None: img = self.transform(img) return img,label def __len__(self): return len(self.imgs) train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor()) test_data=MyDataset(txt=root+'test.txt', transform=transforms.ToTensor()) train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True) test_loader = DataLoader(dataset=test_data, batch_size=64)
3、原文的代码,还有一部分也会报错,ERROR如下。
唉,感叹一下,下次还是看一下语法那些,能读懂了代码再改吧,本想怎个拿来主义的,结果拿来了还是不能运行

解决-原文地址:https://blog.csdn.net/weixin_43848267/article/details/88874584
解决:将 loss_return.data[0] 改为 loss_return.data
还有几个地方 也要将 .data[0] 改为 .data
4、可完整运行的代码
代码1:
import os from skimage import io import torchvision.datasets.mnist as mnist root="E:/fashion_mnist/" train_set = ( mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte')) ) test_set = ( mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte')) ) print("training set :",train_set[0].size()) print("test set :",test_set[0].size()) def convert_to_img(train=True): if(train): f=open(root+'train.txt','w') data_path=root+'/train/' if(not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(train_set[0],train_set[1])): img_path=data_path+str(i)+'.jpg' io.imsave(img_path,img.numpy()) f.write(img_path+' '+str(label)+' ') f.close() else: f = open(root + 'test.txt', 'w') data_path = root + '/test/' if (not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(test_set[0],test_set[1])): img_path = data_path+ str(i) + '.jpg' io.imsave(img_path, img.numpy()) f.write(img_path + ' ' + str(label) + ' ') f.close() convert_to_img(True) convert_to_img(False)
代码2:
import re import numpy import torch from torch.autograd import Variable from torchvision import transforms from torch.utils.data import Dataset, DataLoader from PIL import Image root="E:/fashion_mnist/" # -----------------ready the dataset-------------------------- def default_loader(path): return Image.open(path).convert('RGB') class MyDataset(Dataset): def __init__(self, txt, transform=None, target_transform=None, loader=default_loader): fh = open(txt, 'r') imgs = [] for line in fh: line = line.strip(' ') line = line.rstrip() words = line.split() p1 = re.compile(r'[(](.*?)[)]', re.S) arr = re.findall(p1, words[1]) word = arr[0] imgs.append((words[0],int(word))) self.imgs = imgs self.transform = transform self.target_transform = target_transform self.loader = loader def __getitem__(self, index): fn, label = self.imgs[index] img = self.loader(fn) if self.transform is not None: img = self.transform(img) return img,label def __len__(self): return len(self.imgs) train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor()) test_data=MyDataset(txt=root+'test.txt', transform=transforms.ToTensor()) train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True) test_loader = DataLoader(dataset=test_data, batch_size=64) #-----------------create the Net and training------------------------ class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(3, 32, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2)) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(32, 64, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2) ) self.conv3 = torch.nn.Sequential( torch.nn.Conv2d(64, 64, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2) ) self.dense = torch.nn.Sequential( torch.nn.Linear(64 * 3 * 3, 128), torch.nn.ReLU(), torch.nn.Linear(128, 10) ) def forward(self, x): conv1_out = self.conv1(x) conv2_out = self.conv2(conv1_out) conv3_out = self.conv3(conv2_out) res = conv3_out.view(conv3_out.size(0), -1) out = self.dense(res) return out model = Net() print(model) optimizer = torch.optim.Adam(model.parameters()) loss_func = torch.nn.CrossEntropyLoss() for epoch in range(10): print('epoch {}'.format(epoch + 1)) # training----------------------------- train_loss = 0. train_acc = 0. for batch_x, batch_y in train_loader: batch_x, batch_y = Variable(batch_x), Variable(batch_y) out = model(batch_x) loss = loss_func(out, batch_y) train_loss += loss.item() pred = torch.max(out, 1)[1] train_correct = (pred == batch_y).sum() train_acc += train_correct.item() optimizer.zero_grad() loss.backward() optimizer.step() print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len( train_data)), train_acc / (len(train_data)))) # evaluation-------------------------------- model.eval() eval_loss = 0. eval_acc = 0. for batch_x, batch_y in test_loader: batch_x, batch_y = Variable(batch_x), Variable(batch_y) out = model(batch_x) loss = loss_func(out, batch_y) eval_loss += loss.item() pred = torch.max(out, 1)[1] num_correct = (pred == batch_y).sum() eval_acc += num_correct.item() print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len( test_data)), eval_acc / (len(test_data))))
5、总结
提示:训练模型有点耗时,这里注意一下
图片如果过小,标签页里面单独打开图片会大些,排版搞得屁理解一下,一来没时间写文章,二来排版还没学,以后空了就会学。还是先把文章的质量提高了来
出现的问题主要是因为 torch的版本不同造成的,所以一会我把 我这里的环境贴出来,避免发生同样的错误。
6、环境
系统:win7 64位
Python 3.7.3
各个包的版本号,其它的好像就没啥了

可测试代码-版本2
代码1:
#coding=utf-8 import os from skimage import io import torchvision.datasets.mnist as mnist root="E:/fashion_mnist/" train_set = ( mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte')) ) test_set = ( mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')), mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte')) ) print("training set :",train_set[0].size()) print("test set :",test_set[0].size()) def convert_to_img(train=True): if(train): f=open(root+'train.txt','w') data_path=root+'/train/' if(not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(train_set[0],train_set[1])): img_path=data_path+str(i)+'.jpg' io.imsave(img_path,img.numpy()) f.write(img_path+' '+str(label.numpy())+' ') # label改为label.numpy() f.close() else: f = open(root + 'test.txt', 'w') data_path = root + '/test/' if (not os.path.exists(data_path)): os.makedirs(data_path) for i, (img,label) in enumerate(zip(test_set[0],test_set[1])): img_path = data_path+ str(i) + '.jpg' io.imsave(img_path, img.numpy()) f.write(img_path + ' ' + str(label.numpy()) + ' ') f.close() convert_to_img(True) convert_to_img(False)
代码2:
import torch from torch.autograd import Variable from torchvision import transforms from torch.utils.data import Dataset, DataLoader from PIL import Image root="E:/fashion_mnist/" def default_loader(path): return Image.open(path).convert('RGB') class MyDataset(Dataset): def __init__(self, txt, transform=None, target_transform=None, loader=default_loader): fh = open(txt, 'r') imgs = [] for line in fh: line = line.strip(' ') line = line.rstrip() words = line.split() imgs.append((words[0],int(words[1]))) self.imgs = imgs self.transform = transform self.target_transform = target_transform self.loader = loader def __getitem__(self, index): fn, label = self.imgs[index] img = self.loader(fn) if self.transform is not None: img = self.transform(img) return img,label def __len__(self): return len(self.imgs) train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor()) test_data=MyDataset(txt=root+'test.txt', transform=transforms.ToTensor()) train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True) test_loader = DataLoader(dataset=test_data, batch_size=64) #-----------------create the Net and training------------------------ class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(3, 32, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2)) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(32, 64, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2) ) self.conv3 = torch.nn.Sequential( torch.nn.Conv2d(64, 64, 3, 1, 1), torch.nn.ReLU(), torch.nn.MaxPool2d(2) ) self.dense = torch.nn.Sequential( torch.nn.Linear(64 * 3 * 3, 128), torch.nn.ReLU(), torch.nn.Linear(128, 10) ) def forward(self, x): conv1_out = self.conv1(x) conv2_out = self.conv2(conv1_out) conv3_out = self.conv3(conv2_out) res = conv3_out.view(conv3_out.size(0), -1) out = self.dense(res) return out model = Net() print(model) optimizer = torch.optim.Adam(model.parameters()) loss_func = torch.nn.CrossEntropyLoss() for epoch in range(10): print('epoch {}'.format(epoch + 1)) # training----------------------------- train_loss = 0. train_acc = 0. for batch_x, batch_y in train_loader: batch_x, batch_y = Variable(batch_x), Variable(batch_y) out = model(batch_x) loss = loss_func(out, batch_y) train_loss += loss.data pred = torch.max(out, 1)[1] train_correct = (pred == batch_y).sum() train_acc += train_correct.data optimizer.zero_grad() loss.backward() optimizer.step() print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len( train_data)), train_acc / (len(train_data)))) # evaluation-------------------------------- model.eval() eval_loss = 0. eval_acc = 0. for batch_x, batch_y in test_loader: batch_x, batch_y = Variable(batch_x, volatile=True), Variable(batch_y, volatile=True) out = model(batch_x) loss = loss_func(out, batch_y) eval_loss += loss.data pred = torch.max(out, 1)[1] num_correct = (pred == batch_y).sum() eval_acc += num_correct.data print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len( test_data)), eval_acc / (len(test_data))))
版本2修改的地方
原文:https://blog.csdn.net/shang_jia/article/details/82936074
原文:https://www.liangzl.com/get-article-detail-8524.html
注意:下面的代码不管,下面是第一次测试的时候,下载错了数据集
问题:这里的数据集是数字,不是这个数据集,代码里面是用的fashion-mnist这个数据集
1、下载mnist数据集
地址:http://yann.lecun.com/exdb/mnist/
下面这四个都要下载,下载完成后,解压到同一个目录,我是解压到“E:/fashion_mnist/”这个目录里面,好和下面的代码目录一致
解压完成后,需要修改一下文件名,如(修改原因:保持和下面代码一样,避免出现其它问题):
修改前:t10k-images.idx3-ubyte
修改后:t10k-images-idx3-ubyte
我是第一次弄这玩意,所以尽量弄得白痴些,走弯路很烦,有时候一点点小问题就弄半天,其实就是别人有那么一点没讲清楚,然后就会搞很久