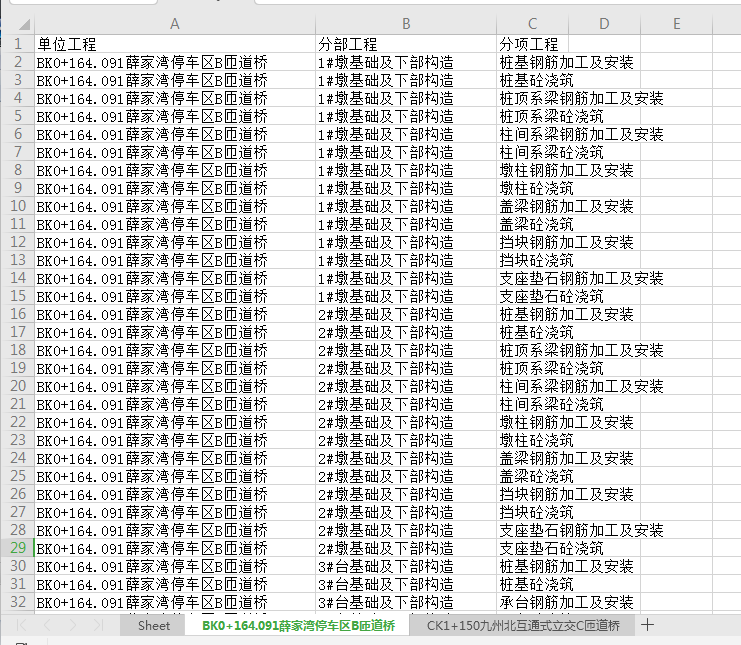
1、处理前

2、处理后
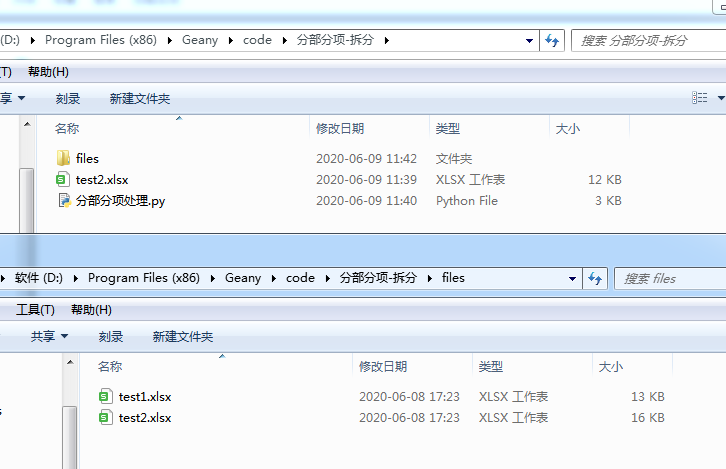
3、目录结构
4、代码
import os
import openpyxl
from openpyxl import Workbook
from copy import deepcopy
# 原文:https://www.cnblogs.com/liuda9495/p/9039732.html
workbook2 = Workbook()
def create_worksheet(path):
#path='test1.xlsx'
workbook = openpyxl.load_workbook(path)# 加载excel
name_list = workbook.sheetnames# 所有sheet的名字
worksheet = workbook[name_list[0]]# 读取第一个工作表
# 获取所有 合并单元格的 位置信息
# 是个可迭代对象,单个对象类型:openpyxl.worksheet.cell_range.CellRange
# print后就是excel坐标信息
m_list = worksheet.merged_cells
l = deepcopy(m_list)# 深拷贝
# 拆分合并的单元格 并填充内容
for m_area in l:
# 这里的行和列的起始值(索引),和Excel的一样,从1开始,并不是从0开始(注意)
r1, r2, c1, c2 = m_area.min_row, m_area.max_row, m_area.min_col, m_area.max_col
worksheet.unmerge_cells(start_row=r1, end_row=r2, start_column=c1, end_column=c2)
print('区域:', m_area, ' 坐标:', r1, r2, c1, c2)
# 获取一个单元格的内容
first_value = worksheet.cell(r1, c1).value
# 数据填充
for r in range(r1, r2+1):# 遍历行
if c2 - c1 > 0:# 多个列,遍历列
for c in range(c1, c2+1):
worksheet.cell(r, c).value = first_value
else:# 一个列
worksheet.cell(r, c1).value = first_value
# 特定的业务逻辑
unit_name = worksheet.cell(2, 2).value# 获取单位工程的名字
nPos = unit_name.find(':')
unit_name = unit_name[nPos+1:]
worksheet.title = unit_name# 改sheet的名字
worksheet.insert_cols(1)# 插入列
for index in range(worksheet.max_row):# 首列批量填充数据
r = index+1
worksheet.cell(r, 1).value = unit_name
worksheet.cell(3, 1).value = '单位工程'# 单元格赋值
# 删除行
worksheet.delete_rows(4)
worksheet.delete_rows(2)
worksheet.delete_rows(1)
# 删除列
worksheet.delete_cols(5)
worksheet.delete_cols(3)
worksheet2 = workbook2.create_sheet(unit_name)
for x in range(worksheet.max_row):# 首列批量填充数据
r = x+1
for y in range(worksheet.max_column):
c = y+1
worksheet2.cell(r, c).value = worksheet.cell(r, c).value
def each_files():
pathDir = os.listdir('./files/')
for index, value in enumerate(pathDir):
filepath2 = './files/' + value
print(filepath2)
create_worksheet(filepath2)
each_files()
workbook2.save('test2.xlsx')