当代码能正常提交到spark集群运行的时候,出现下面的错误:
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space at java.lang.ClassLoader.defineClass1(Native Method) at java.lang.ClassLoader.defineClass(ClassLoader.java:800) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.URLClassLoader.defineClass(URLClassLoader.java:449) at java.net.URLClassLoader.access$100(URLClassLoader.java:71) at java.net.URLClassLoader$1.run(URLClassLoader.java:361) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) at scala.collection.SeqViewLike$AbstractTransformed.<init>(SeqViewLike.scala:43) at scala.collection.SeqViewLike$$anon$4.<init>(SeqViewLike.scala:79) at scala.collection.SeqViewLike$class.newFlatMapped(SeqViewLike.scala:79) at scala.collection.SeqLike$$anon$2.newFlatMapped(SeqLike.scala:635) at scala.collection.SeqLike$$anon$2.newFlatMapped(SeqLike.scala:635) at scala.collection.TraversableViewLike$class.flatMap(TraversableViewLike.scala:160) at scala.collection.SeqLike$$anon$2.flatMap(SeqLike.scala:635) at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:58) at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:48) at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:46) at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:53) at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:53) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:56) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:56) at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:153) at org.apache.spark.sql.DataFrame.<init>(DataFrame.scala:145) at org.apache.spark.sql.DataFrame.<init>(DataFrame.scala:130) at org.apache.spark.sql.DataFrame$.apply(DataFrame.scala:52) at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:829) at p.JavaSparkPi.main(JavaSparkPi.java:30) Exception in thread "Thread-3" java.lang.OutOfMemoryError: PermGen space Exception in thread "Thread-30" java.lang.OutOfMemoryError: PermGen space Exception in thread "Thread-33" java.lang.OutOfMemoryError: PermGen space
除了出现上面的问题之外还会出现下面这个错误。看到这个错误的第一反应内存溢出
Job aborted due to stage failure: Total size of serialized results of 34 tasks (1033.9 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
Exception in thread "main"
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main"
2018-12-19 10:42:51,599 WARN [shuffle-client-0] server.TransportChannelHandler : Exception in connection from /10.8.30.108:50610
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at io.netty.buffer.PooledUnsafeDirectByteBuf.setBytes(PooledUnsafeDirectByteBuf.java:313)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:881)
at io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:242)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:119)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:745)
2018-12-19 10:42:51,610 INFO [dispatcher-event-loop-1] yarn.ApplicationMaster$AMEndpoint : Driver terminated or disconnected! Shutting down. tc-20024:50610
2018-12-19 10:42:51,614 INFO [dispatcher-event-loop-1] yarn.ApplicationMaster : Final app status: SUCCEEDED, exitCode: 0
2018-12-19 10:42:51,623 INFO [Thread-3] yarn.ApplicationMaster : Unregistering ApplicationMaster with SUCCEEDED
2018-12-19 10:42:51,637 INFO [Thread-3] impl.AMRMClientImpl : Waiting for application to be successfully unregistered.
2018-12-19 10:42:51,743 INFO [Thread-3] yarn.ApplicationMaster : Deleting staging directory .sparkStaging/application_1545188975663_0002
2018-12-19 10:42:51,745 INFO [Thread-3] util.ShutdownHookManager : Shutdown hook called
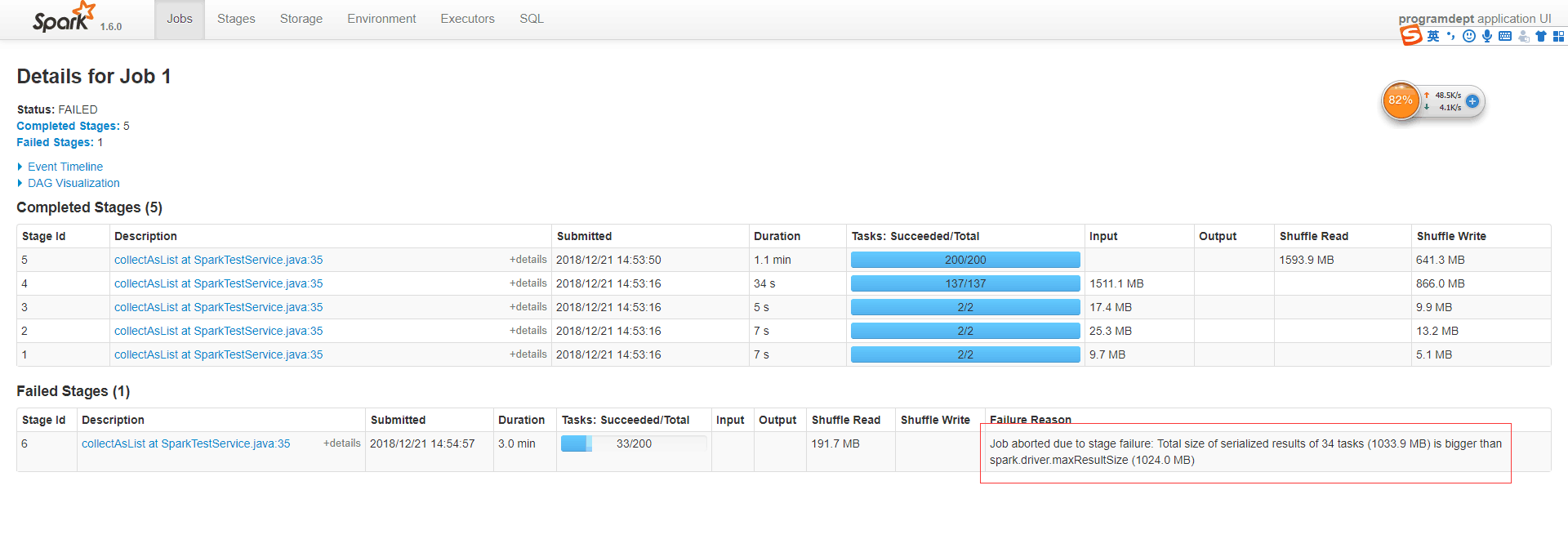
这个种种的迹象都显示是程序的内存溢出造成的,那为什么会内存溢出那,原因是我们队结果集进行collect操作的时候,整的结果作为一个大的集群全部的聚集到了driver 端也就是我们的idea当中。这个时候我们的客户端如果内存不是够大的情况下就会出现内存溢出的情况
你可以调大你的内存。但是这样是治标不治本的操作,在后面的操作过程当中,你也不知道后面的数据量多大,配置多大的driver内存合适那,这个就很难界定了。所以我们在处理数据的时候尽量的减轻对driver端的压力。可以使用foreachpartition的方法将数据全部在excutor端进行
处理。
参考这篇文章执行:https://segmentfault.com/a/1190000005365244?utm_source=tag-newest
这里注意一下,所有的数据都是按照row输出在excutor端的不是我们的控制台。