正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

------------------------正文开始---------------------------
1、大白话、什么是Elasticsearch
Elasticsearch,分布式,高性能,高可用,可伸缩的搜索和分析系统
1、什么是搜索?
2、如果用数据库做搜索会怎么样?
3、什么是全文检索、倒排索引和Lucene?
4、什么是Elasticsearch?
------------------------------------------------------------------------------------------------------------------------
1、什么是搜索?
百度:我们比如说想找寻任何的信息的时候,就会上百度去搜索一下,比如说找一部自己喜欢的电影,或者说找一本喜欢的书,或者找一条感兴趣的新闻(提到搜索的第一印象)
百度 != 搜索,这是不对的
垂直搜索(站内搜索)
互联网的搜索:电商网站,招聘网站,新闻网站,各种app
IT系统的搜索:OA软件,办公自动化软件,会议管理,日程管理,项目管理,员工管理,搜索“张三”,“张三儿”,“张小三”;有个电商网站,卖家,后台管理系统,搜索“牙膏”,订单,“牙膏相关的订单”
搜索,就是在任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字相关的有些信息
------------------------------------------------------------------------------------------------------------------------
2、如果用数据库做搜索会怎么样?
做软件开发的话,或者对IT、计算机有一定的了解的话,都知道,数据都是存储在数据库里面的,比如说电商网站的商品信息,招聘网站的职位信息,新闻网站的新闻信息,等等吧。所以说,很自然的一点,如果说从技术的角度去考虑,如何实现如说,电商网站内部的搜索功能的话,就可以考虑,去使用数据库去进行搜索。
1、比方说,每条记录的指定字段的文本,可能会很长,比如说“商品描述”字段的长度,有长达数千个,甚至数万个字符,这个时候,每次都要对每条记录的所有文本进行扫描,懒判断说,你包不包含我指定的这个关键词(比如说“牙膏”)
2、还不能将搜索词拆分开来,尽可能去搜索更多的符合你的期望的结果,比如输入“生化机”,就搜索不出来“生化危机”
用数据库来实现搜索,是不太靠谱的。通常来说,性能会很差的。

------------------------------------------------------------------------------------------------------------------------
3、什么是全文检索和Lucene?
(1)全文检索,倒排索引
(2)lucene,就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候,引入lucene jar,然后基于lucene的api进行去进行开发就可以了。
用lucene,我们就可以去将已有的数据建立索引,lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用lucene提供的一些功能和api来针对磁盘上额
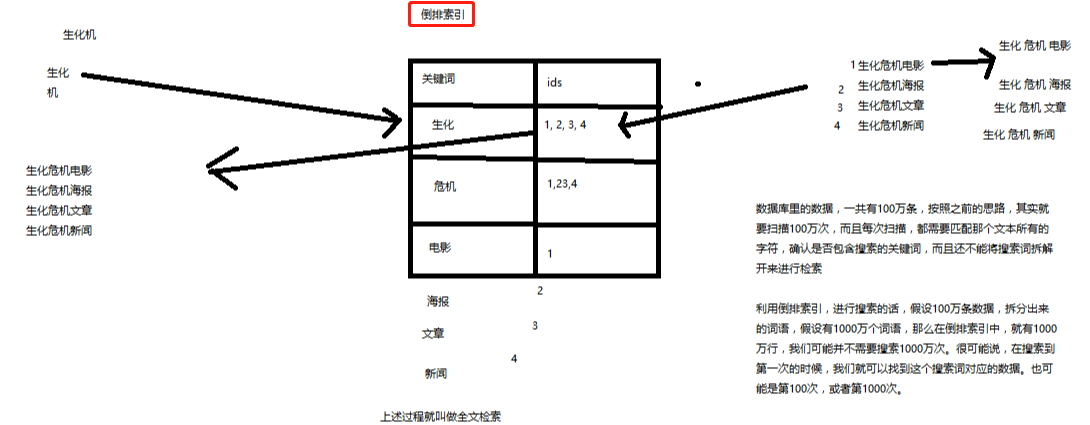
------------------------------------------------------------------------------------------------------------------------
4、什么是Elasticsearch?
(1)图解分析
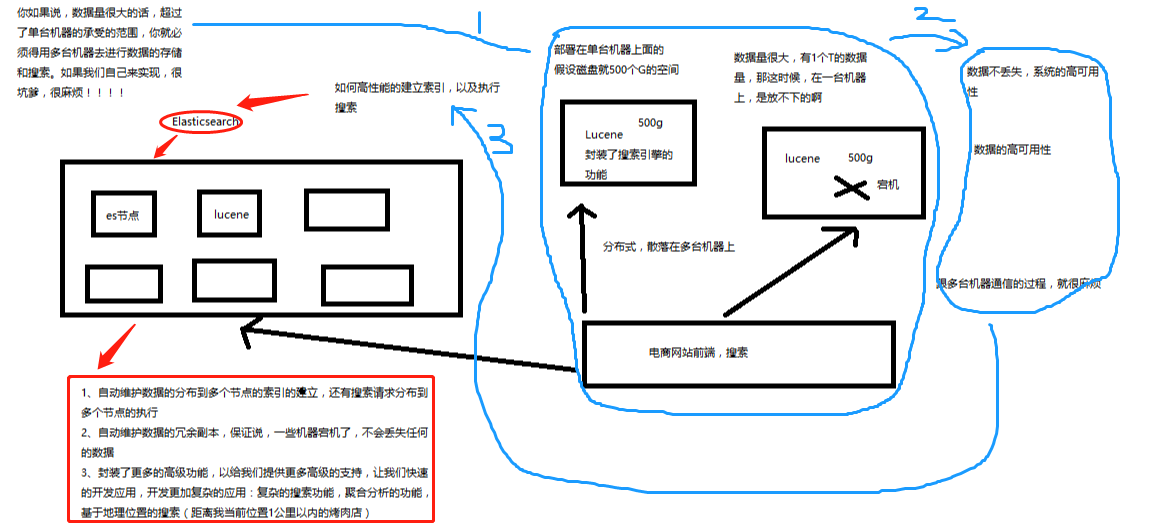
---------------------------------------------------------------------------------------------------------
2、Elasticsearch功能以及适用场景
1、Elasticsearch的功能,干什么的
2、Elasticsearch的适用场景,能在什么地方发挥作用
3、Elasticsearch的特点,跟其他类似的东西不同的地方在哪里
1、Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些
分布式,搜索,数据分析
(2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含牙膏的商品,select * from products where product_name like "%牙膏%"
结构化检索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id='日化用品'
部分匹配、自动完成、搜索纠错、搜索推荐
数据分析:我们分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
(3)对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
海量数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费1小时(这就不叫近实时,离线批处理,batch-processing);在秒级别对数据进行搜索和分析
跟分布式/海量数据相反的:lucene,单机应用,只能在单台服务器上使用,最多只能处理单台服务器可以处理的数据量
2、Elasticsearch的适用场景
国外
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
国内
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
3、Elasticsearch的特点
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
(2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
(3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能
----------------------------------------------------------------------------------------------------------------------
3、手工画图剖析Elasticsearch核心概念:NRT、索引、分片、副本等 [高质量和大小] [高质量和大小]
1、lucene和elasticsearch的前世今生
2、elasticsearch的核心概念
3、elasticsearch核心概念 vs. 数据库核心概念
----------------------------------------------------------------------------------------------------------------------------------------
1、lucene和elasticsearch的前世今生
lucene,最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂(实现一些简单的功能,写大量的java代码),需要深入理解原理(各种索引结构)
elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何额外设置,完全开源
关于elasticsearch的一个传说,有一个程序员失业了,陪着自己老婆去英国伦敦学习厨师课程。程序员在失业期间想给老婆写一个菜谱搜索引擎,觉得lucene实在太复杂了,就开发了一个封装了lucene的开源项目,compass。后来程序员找到了工作,是做分布式的高性能项目的,觉得compass不够,就写了elasticsearch,让lucene变成分布式的系统。
----------------------------------------------------------------------------------------------------------------------------------------
2、elasticsearch的核心概念
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
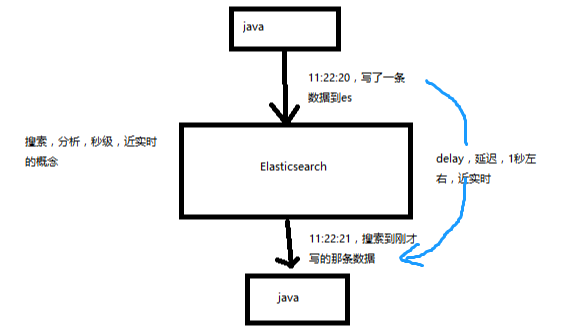
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(6)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
--------------------------------------------------------------------------
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
(7)shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
**************************************** 图示解析原理 ************************************
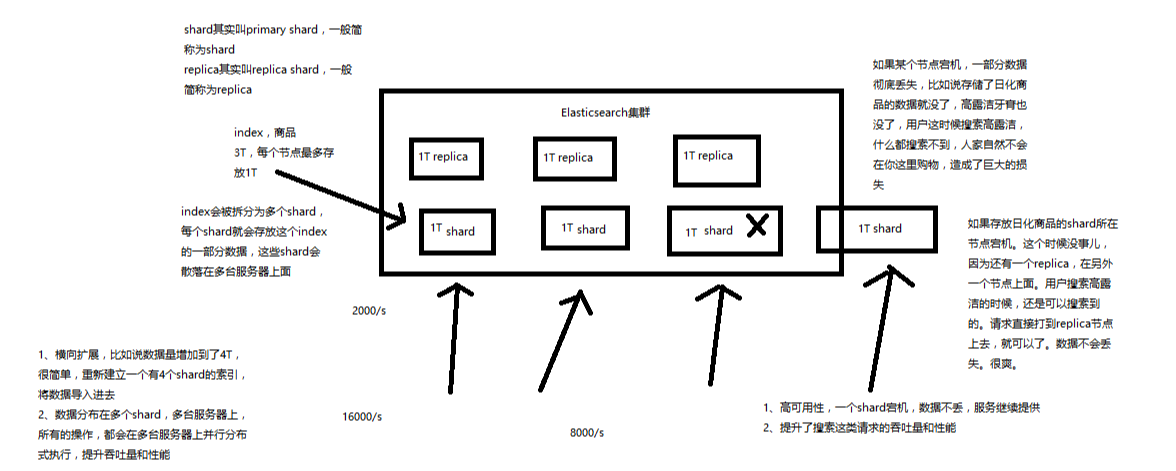
----------------------------------------------------------------------------------------------------------------------------------------
3、elasticsearch核心概念 vs. 数据库核心概念
Elasticsearch | 数据库
-----------------------------------------
Document | 行
Type | 表
Index | 库
-----------------------------------------------------------------------------------------------------------------------
4、ES的安装
1、安装JDK,至少1.8.0_73以上版本,java -version
2、下载和解压缩Elasticsearch安装包,目录结构
3、启动Elasticsearch:binelasticsearch.bat,es本身特点之一就是开箱即用,如果是中小型应用,数据量少,操作不是很复杂,直接启动就可以用了
4、检查ES是否启动成功:http://localhost:9200/?pretty
name: node名称
cluster_name: 集群名称(默认的集群名称就是elasticsearch)
version.number: 5.2.0,es版本号
{
"name" : "4onsTYV",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "nKZ9VK_vQdSQ1J0Dx9gx1Q",
"version" : {
"number" : "5.2.0",
"build_hash" : "24e05b9",
"build_date" : "2017-01-24T19:52:35.800Z",
"build_snapshot" : false,
"lucene_version" : "6.4.0"
},
"tagline" : "You Know, for Search"
}
5、修改集群名称:elasticsearch.yml
6、下载和解压缩Kibana安装包,使用里面的开发界面,去操作elasticsearch,作为我们学习es知识点的一个主要的界面入口
7、启动Kibana:binkibana.bat
8、进入Dev Tools界面
9、GET _cluster/health
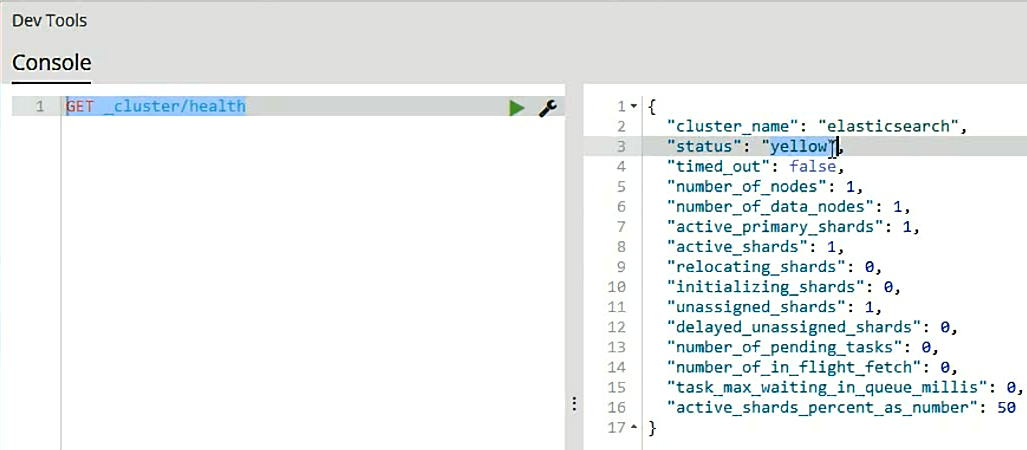
5、集群健康检查,文档CRUD
----------------------------面向文档的搜索分析引擎
1)应用系统的数据结构都是面向对象的,复杂的
2)对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦
传统数据库应用系统格式:
--------------------------------------------------------------------------------------------------------------------
public class Employee {
private String email;
private String firstName;
private String lastName;
private EmployeeInfo info;
private Date joinDate;
}
private class EmployeeInfo {
private String bio; // 性格
private Integer age;
private String[] interests; // 兴趣爱好
}
EmployeeInfo info = new EmployeeInfo();
info.setBio("curious and modest");
info.setAge(30);
info.setInterests(new String[]{"bike", "climb"});
Employee employee = new Employee();
employee.setEmail("zhangsan@sina.com");
employee.setFirstName("san");
employee.setLastName("zhang");
employee.setInfo(info);
employee.setJoinDate(new Date());
employee对象:里面包含了Employee类自己的属性,还有一个EmployeeInfo对象
两张表:employee表,employee_info表,将employee对象的数据重新拆开来,变成Employee数据和EmployeeInfo数据
employee表:email,first_name,last_name,join_date,4个字段
employee_info表:bio,age,interests,3个字段;此外还有一个外键字段,比如employee_id,关联着employee表
3)、ES是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es可以提供复杂的索引,全文检索,分析聚合等功能
4)、es的document用json数据格式来表达
ES格式:
---------------------------------------------------------------------------------------------------------------------------
{
"email": "zhangsan@sina.com",
"first_name": "san",
"last_name": "zhang",
"info": {
"bio": "curious and modest",
"age": 30,
"interests": [ "bike", "climb" ]
},
"join_date": "2017/01/01"
}
我们就明白了es的document数据格式和数据库的关系型数据格式的区别
----------------------------------------------------------------------------------------------------------------------------
2、电商网站商品管理案例背景介绍
有一个电商网站,需要为其基于ES构建一个后台系统,提供以下功能:
(1)对商品信息进行CRUD(增删改查)操作
(2)执行简单的结构化查询
(3)可以执行简单的全文检索,以及复杂的phrase(短语)检索
(4)对于全文检索的结果,可以进行高亮显示
(5)对数据进行简单的聚合分析
----------------------------------------------------------------------------------------------------------------------------
3、简单的集群管理
(1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488006741 15:12:21 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007113 15:18:33 elasticsearch green 2 2 2 1 0 0 0 0 - 100.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007216 15:20:16 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
为什么现在会处于一个yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
做一个小实验:此时只要启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
(2)快速查看集群中有哪些索引
GET /_cat/indices?v
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(3)简单的索引操作
创建索引:PUT /test_index?pretty
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test_index XmS9DTAtSkSZSwWhhGEKkQ 5 1 0 0 650b 650b
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
删除索引:DELETE /test_index?pretty
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
----------------------------------------------------------------------------------------------------------------------------
4、商品的CRUD操作
(1)新增商品:新增文档,建立索引
PUT /index/type/id
{
"json数据"
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
PUT /ecommerce/product/2
{
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
}
PUT /ecommerce/product/3
{
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
}
es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(2)查询商品:检索文档
GET /index/type/id
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GET /ecommerce/product/1
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(3)修改商品:替换文档
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao"
}
替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(4)修改商品:更新文档
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
POST /ecommerce/product/1/_update
{
"doc": {
"name": "jiaqiangban gaolujie yagao"
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我的风格,其实有选择的情况下,不太喜欢念ppt,或者照着文档做,或者直接粘贴写好的代码,尽量是纯手敲代码
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(5)删除商品:删除文档
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DELETE /ecommerce/product/1
{
"found": true,
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 9,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"found": false
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6、演示多种查询方式
课程大纲
1、query string search
2、query DSL
3、query filter
4、full-text search
5、phrase search
6、highlight search
---------------------------------------------------------------------------------------------------------------------------------
把英文翻译成中文,让我觉得很别扭,term,词项
1、query string search
------------- 在生产环境中,几乎很少使用query string search
搜索全部商品:
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
GET /ecommerce/product/_search
-------------------------------------------------------------------------------------------------------------------------------
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 1,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": [
"qingxin"
]
}
}
]
}
}
query string search的由来,因为search参数都是以http请求的query string来附带的
搜索商品名称中包含yagao的商品,而且按照售价降序排序:GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
适用于临时的在命令行使用一些工具,比如curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的.
---------------------------------------------------------------------------------------------------------------------------------
2、query DSL
-----------更加适合生产环境的使用,可以构建复杂的查询
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了
---------------------------------------------------------------------------------------------------------------------------------
查询所有的商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} }
}
---------------------------------------------------------------------------------------------------------------------------------
查询名称包含yagao的商品,同时按照价格降序排序
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" : "yagao"
}
},
"sort": [
{ "price": "desc" }
]
}
---------------------------------------------------------------------------------------------------------------------------------
分页查询商品,总共3条商品,假设每页就显示1条商品,现在显示第2页,所以就查出来第2个商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
---------------------------------------------------------------------------------------------------------------------------------
指定要查询出来商品的名称和价格就可以
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"_source": ["name", "price"]
}
---------------------------------------------------------------------------------------------------------------------------------
3、query filter
搜索商品名称包含yagao,而且售价大于25元的商品
GET /ecommerce/product/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "yagao"
}
},
"filter" : {
"range" : {
"price" : { "gt" : 25 }
}
}
}
}
}
---------------------------------------------------------------------------------------------------------------------------------
4、full-text search(全文检索)
---------------------------------------------------------------------------------------------------------------------------------
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "yagao producer"
}
}
}
尽量,无论是学什么技术,比如说你当初学java,学linux,学shell,学javascript,学hadoop。。。。一定自己动手,特别是手工敲各种命令和代码,切记切记,减少复制粘贴的操作。只有自己动手手工敲,学习效果才最好。
producer这个字段,会先被拆解,建立倒排索引:
special 4
yagao 4
producer 1,2,3,4
gaolujie 1
zhognhua 3
jiajieshi 2
yagao producer ---> yagao和producer
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": [
"meibai"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 0.25811607,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 0.25811607,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": [
"qingxin"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 0.1805489,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
}
]
}
}
---------------------------------------------------------------------------------------------------------------------------------
5、phrase search(短语搜索)
跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
---------------------------------------------------------------------------------------------------------------------------------
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : {
"producer" : "yagao producer"
}
}
}
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": [
"meibai"
]
}
}
]
}
}
---------------------------------------------------------------------------------------------------------------------------------
6、highlight search(高亮搜索结果)
---------------------------------------------------
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "producer"
}
},
"highlight": {
"fields" : {
"producer" : {}
}
}
}
---------------------------------------------------------------------------------------------------------------------------------
嵌套聚合,下钻分析,聚合分析
第一个分析需求:计算每个tag下的商品数量
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": { "field": "tags" }
}
}
}
将文本field的fielddata属性设置为true
PUT /ecommerce/_mapping/product
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"all_tags": {
"terms": { "field": "tags" }
}
}
}
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2
},
{
"key": "meibai",
"doc_count": 2
},
{
"key": "qingxin",
"doc_count": 1
}
]
}
}
}
----------------------------------------------------------------------------------------------------------------
第二个聚合分析的需求:对名称中包含yagao的商品,计算每个tag下的商品数量
GET /ecommerce/product/_search
{
"size": 0,
"query": {
"match": {
"name": "yagao"
}
},
"aggs": {
"all_tags": {
"terms": {
"field": "tags"
}
}
}
}
----------------------------------------------------------------------------------------------------------------
第三个聚合分析的需求:先分组,再算每组的平均值,计算每个tag下的商品的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "tags" },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2,
"avg_price": {
"value": 27.5
}
},
{
"key": "meibai",
"doc_count": 2,
"avg_price": {
"value": 40
}
},
{
"key": "qingxin",
"doc_count": 1,
"avg_price": {
"value": 40
}
}
]
}
}
}
----------------------------------------------------------------------------------------------------------------
第四个数据分析需求:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"all_tags" : {
"terms" : { "field" : "tags", "order": { "avg_price": "desc" } },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
我们现在全部都是用es的restful api在学习和讲解es的所欲知识点和功能点,但是没有使用一些编程语言去讲解(比如java),原因有以下:
1、es最重要的api,让我们进行各种尝试、学习甚至在某些环境下进行使用的api,就是restful api。如果你学习不用es restful api,比如我上来就用java api来讲es,也是可以的,但是你根本就漏掉了es知识的一大块,你都不知道它最重要的restful api是怎么用的
2、讲知识点,用es restful api,更加方便,快捷,不用每次都写大量的java代码,能加快讲课的效率和速度,更加易于同学们关注es本身的知识和功能的学习
3、我们通常会讲完es知识点后,开始详细讲解java api,如何用java api执行各种操作
4、我们每个篇章都会搭配一个项目实战,项目实战是完全基于java去开发的真实项目和系统
----------------------------------------------------------------------------------------------------------------
第五个数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 20
},
{
"from": 20,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
--------------------------------------------------------------------------------------------------------------------- 上 完成。