一、Hadoop理论
Hadoop是一个专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理)
一、HDFS部分:
Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。
用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
hadoop使用java编写,版本较为混乱,初学者可从1.2.1开始学习
1.成百上千台服务器组成集群,需要时刻检测服务器是否故障
2.用流读取数据更加高效快速
3.存储节点具有运算功能,省略了服务器之间来回传数据的网络带宽限制
4.一次写入,多次访问,不修改数据
5.多平台
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
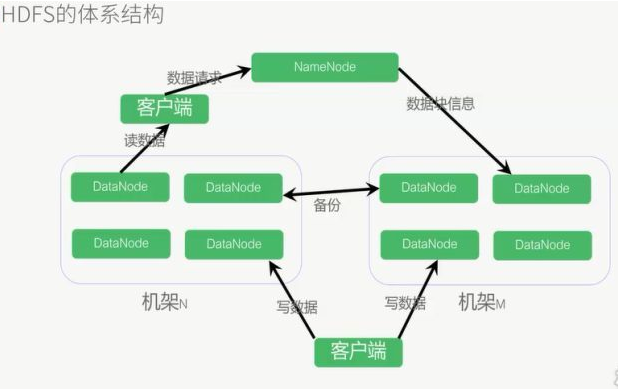
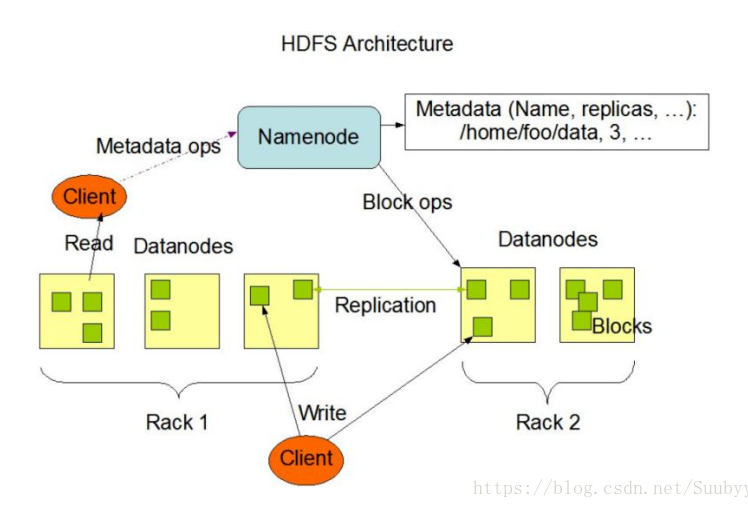
namenode:master
负责总体调度,处理协调请求等(一个集群只能有一个namenode,但是可以多个集群组成一个更大的集群,这时就有多个namenode,这时的namenode有两种状态,一种叫active并且一个大集群只能有一个namenode处于该状态,一种为standby)
namenode两大功能:接受客户端读写服务,存放元数据(DataNode存储的位置等基本信息,fsimage和edits文件)
fsimage是namenode格式化时产生的,edits是用户操作增删改查的时候生成的日志
datanode:slave,存储节点,会备份,一般本地2分,其他服务器一份
机架:多个DataNod节点组成,master通过机架感知技术得知所需数据的位置
数据块:存储单元,一般64M(hadoop2中是128M)
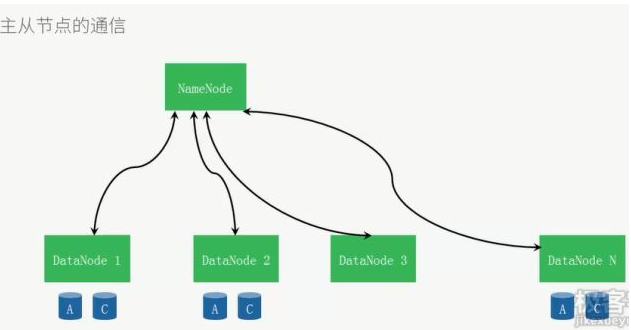
时刻保持心跳通讯,保证每个数据都备份于3个节点上

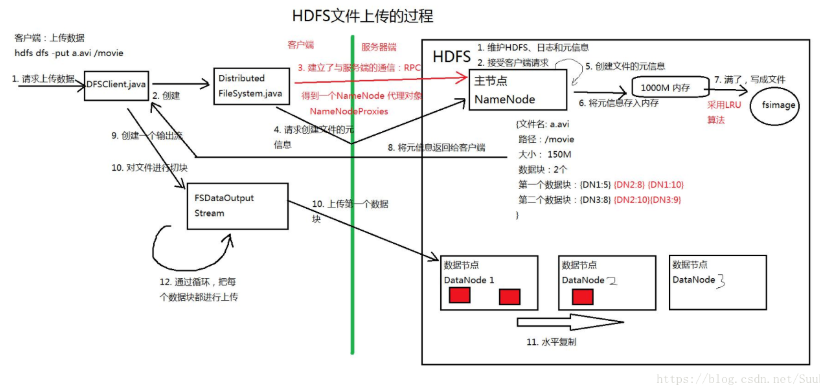
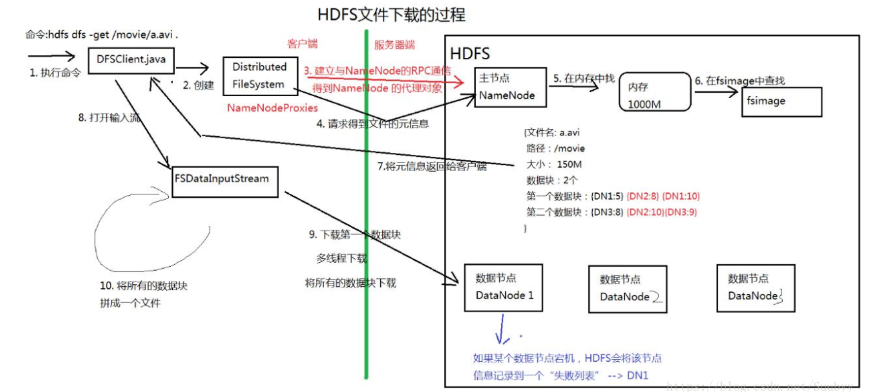
5的read为第一个数据块读完后,读下一个数据块,如果在读取过程中某一个数据块出问题,则会记录下来并且找其他的备份,并且以后不再读取错误数据块

--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DataNode数据节点
- 以数据块为单位储存数据
- 数据保存的目录由hadoop.tmp.dir决定
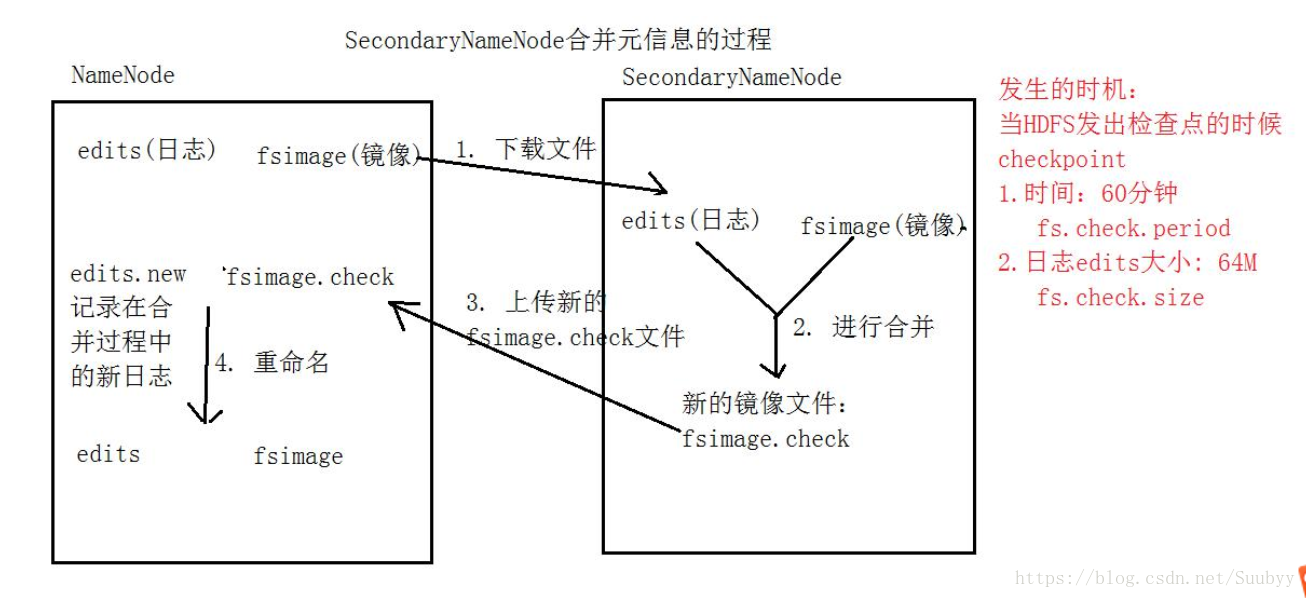
- Secondary NameNode第二名称节点
- 主要是合并日日志
- 日志合并过程
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
二、HDFS + Yarn部分:

分布式计算Yarn``MapReduce
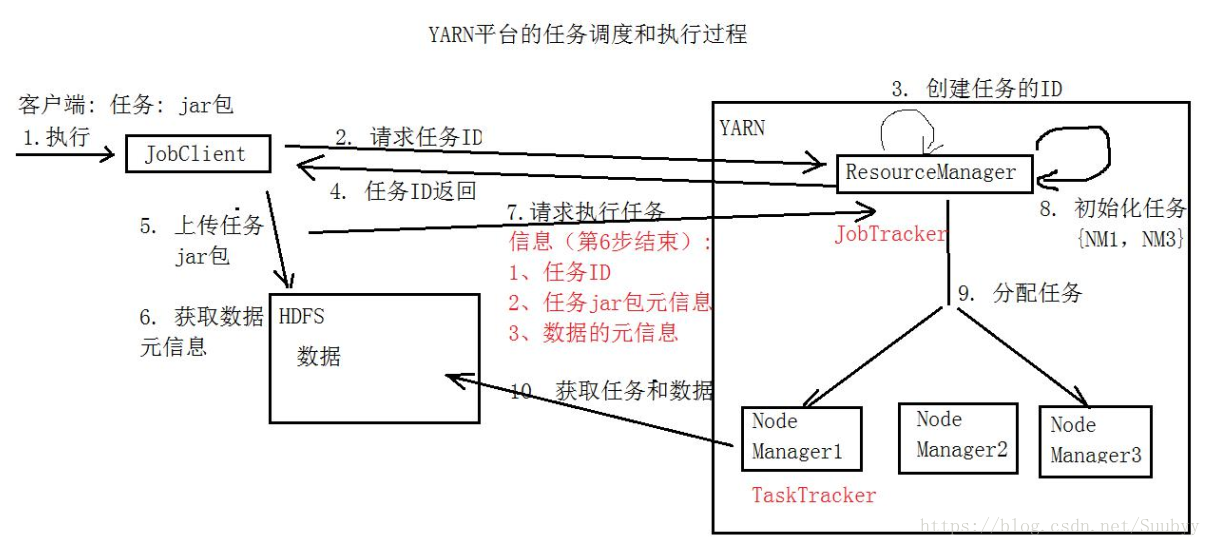
- ResourceManager(资源管理器)
- 接受客户端的请求:执行任务
- 分配任务资源
- 分配任务
- NodeManager(节点管理器,运行MapReduce任务)
- 从DataNode获取数据,执行任务
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
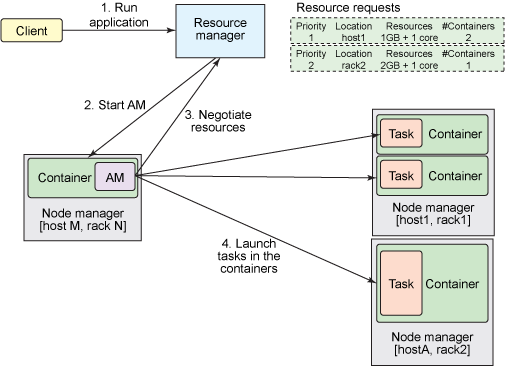
三. 提交一个Application到Yarn的流程
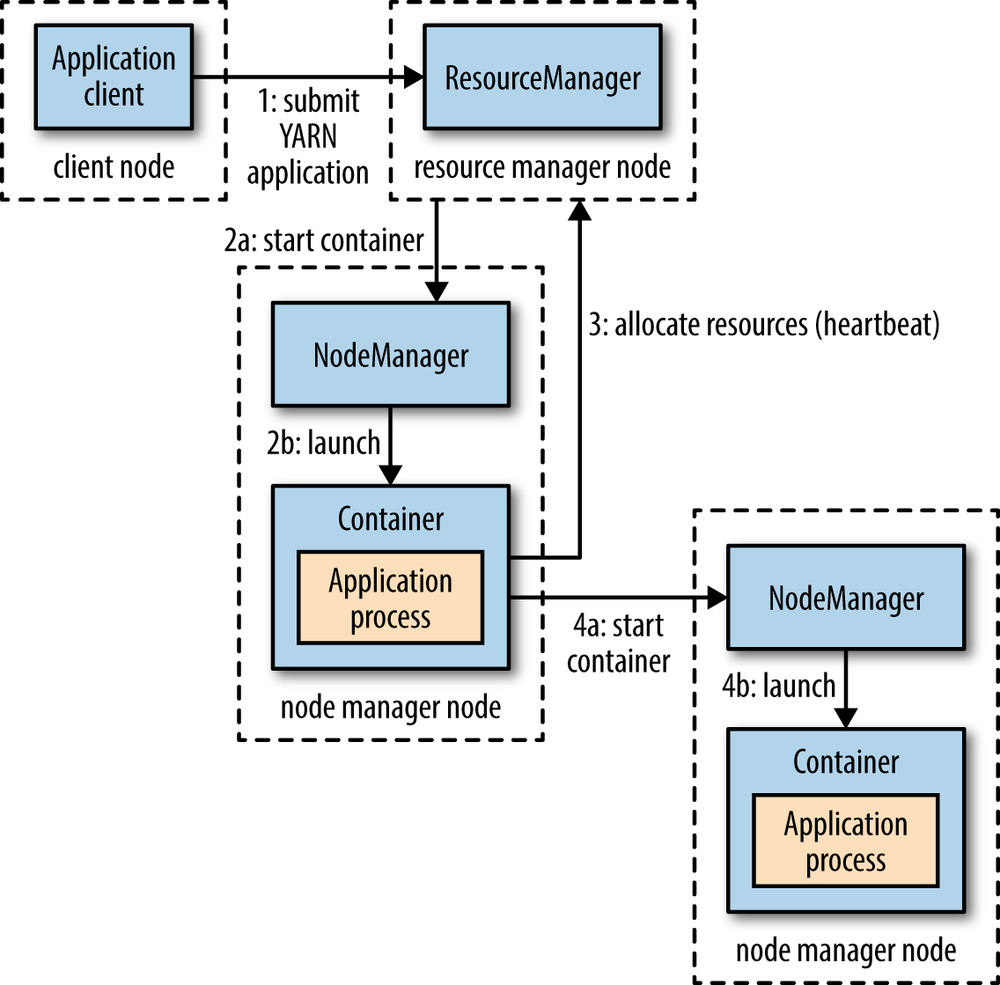
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
-
Client向Yarn提交Application,这里我们假设是一个MapReduce作业。
-
ResourceManager向NodeManager通信,为该Application分配第一个容器。并在这个容器中运行这个应用程序对应的ApplicationMaster。
-
ApplicationMaster启动以后,对作业(也就是Application)进行拆分,拆分task出来,这些task可以运行在一个或多个容器中。然后向ResourceManager申请要运行程序的容器,并定时向ResourceManager发送心跳。
-
申请到容器后,ApplicationMaster会去和容器对应的NodeManager通信,而后将作业分发到对应的NodeManager中的容器去运行,这里会将拆分后的MapReduce进行分发,对应容器中运行的可能是Map任务,也可能是Reduce任务。
-
容器中运行的任务会向ApplicationMaster发送心跳,汇报自身情况。当程序运行完成后,ApplicationMaster再向ResourceManager注销并释放容器资源。
以上就是一个作业的大体运行流程。
为什么会有Hadoop Yarn框架的出现?
上面说了这么多,最后我们来聊聊为什么会有Yarn吧。
直接的原因呢,就是因为Hadoop1.0中架构的缺陷,在MapReduce中,jobTracker担负起了太多的责任了,接收任务是它,资源调度是它,监控TaskTracker运行情况还是它。这样实现的好处是比较简单,但相对的,就容易出现一些问题,比如常见的单点故障问题。
要解决这些问题,只能将jobTracker进行拆分,将其中部分功能拆解出来。彼时业内已经有了一部分的资源管理框架,比如mesos,于是照着这个思路,就开发出了Yarn。这里多说个冷知识,其实Spark早期是为了推广mesos而产生的,这也是它名字的由来,不过后来反正是Spark火起来了。。。
闲话不多说,其实Hadoop能有今天这个地位,Yarn可以说是功不可没。因为有了Yarn,更多计算框架可以接入到Hdfs中,而不单单是MapReduce,到现在我们都知道,MapReduce早已经被Spark等计算框架赶超,而Hdfs却依然屹立不倒。究其原因,正式因为Yarn的包容,使得其他计算框架能专注于计算性能的提升。Hdfs可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,Yarn功不可没。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
二、Hive的原理以及使用
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析Facebook公司最早完成并开源了hive框架,可以将sql语句直接翻译成MapReduce程序。Hive是基于Hadoop的一个数据仓库工具,可以将结构化数据文件映射成一张表,并提供类似SQL的查询功能。Hive相当于一个客户端。
Hive框架的作用:
(1)可以让不懂java的数据分析人员使用hadoop进行数据分析;
(2)MapReduce开发非常繁琐复杂,使用hive可以提高效率。
(3)统一的元数据管理,可与impala/spark共享元数据。
2. Hive基础:
(1)使用HQL作为查询接口;使用MapReduce进行计算;数据存储在HDFS上;运行在Yarn上。
(2)Hive比较灵活和可扩展性,支持UDF和多种文件格式。
(3)Hive适合离线数据分析(批量处理、延时要求很大)。
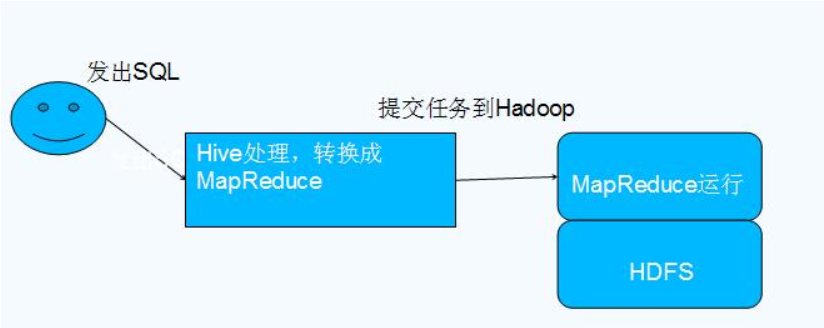
Hive 是 SQL解析引擎,它将SQL语句转译成Map/Reduce Job然后在Hadoop执行。Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在Map/Reduce Job里使用这些数据。
Hive的系统结构

由上图可知,HDFS和Mapreduce是Hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件可以分为两大类:服务端组件和客户端组件。
(1)客户端组件:
①CLI:command line interface,命令行接口。
②Thrift客户端:上面的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口是建立在Thrift客户端之上,包括JDBC和ODBC接口。
③WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的hwi组件(hive web interface),使用前要启动hwi服务。
(2)服务端组件:
①Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
②Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
③Thrift服务:Thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
(3)底层根基:
—>Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive的执行流程
