搭建完全分布式时,先搭建好伪分布式,在其基础上做修改 参考: url: https://www.cnblogs.com/gzgBlog/p/13703051.html
完全分布式安装
伪分布式是基于单个节点,而完全分布式是基于两个或两个以上节点完成Hadoop集群搭建。
下面基于两个节点完成,一个节点的名字是master,另一个节点的名字是slave01。
关于搭建伪分布式和完全分布式,主要区别体现在core-site.xml和hdfs-site.xml的配置不一样,完全分布式会包含更多信息,下面会逐步说明。
1.修改core-site.xml
文件core-site.xml文件中,hadoop.tmp.dir是Hadoop文件系统依赖的基础配置,默认存放在/tmp/{$user}下。但是存放在/tmp下是不安全的,因为系统重启后文件有可能被删除,所以会指向另外的路径。
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <!-- save tmp file --> <name>hadoop.tmp.dir</name> <value>/app/hadoop-2.2.0/hdfs/tmp</value> </property> </configuration>
2.修改hdfs-site.xml文件
这里主要配置了Secondary NameNode的信息,其中slave01是从节点机器名
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave01:50090</value> </property> <property> <name>dfs.namenode.secondary.https-address</name> <value>slave01:50091</value> </property> <property> <!--hdfs的副本数量--> <name>dfs.replication</name> <value>2</value> </property> <property> <!--存储namenode的路径--> <name>dfs.name.dir</name> <value>/app/hadoop-2.2.0/hdfs/name</value> </property> <property> <!--存储上传数据的路径--> <name>dfs.data.dir</name> <value>/app/hadoop-2.2.0/hdfs/data</value> </property> <property> <!--设置为false可以不用检查权限--> <name>dfs.permission</name> <value>false</value> </property> </configuration>
3.配置masters和slaves
接着需要在配置文件目录/app/hadoop-2.2.0/etc/hadoop下生成masters和slaves文件,
并在masters文件中写入master,在slaves文件中写入master和slave,其中slaves文件存放的是datanode,也就是数据节点,如下图所示

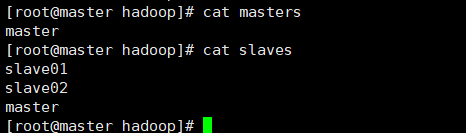
需要注意的是,这里的master和slave是节点名称,需要与/etc/hosts中的配置相映射。
4.相关文件的复制在完全分布式的环境中
master和slave节点上的文件需要一致,因此这里需要将master节点中的文件复制到slave节点中,主要包括以下文件:·Hadoop整个文件夹,如/opt/software/hadoop-2.5.1下面的所有文件。·系统配置文件,如/etc/profile文件,其中包含各类环境变量的配置。·/etc/hosts文件。操作步骤如下:
(1)复制Hadoop整个文件夹。复制文件夹需要使用scp-r指令:
scp -r /app/hadoop-2.2.0 root@slave01:/app/
(2)复制/etc/profile到salve的Home目录。
scp /etc/profile root@slave01:/etc/profile
(3)复制/etc/hosts文件,命令如下:
scp /etc/hosts root@slave02:/etc/hosts
5.启动hdfs
注意,如果提前启动过,并且创建了文件一定要删除,之后一定要先格式化hdfs 使用 Hadoop namenode -format
在master使用 start-dfs.sh启动,并使用jps查看是否已启动

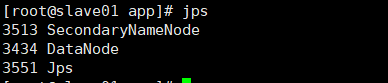
在slave01使用jps查看
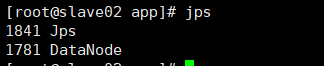
在slave02使用jps查看
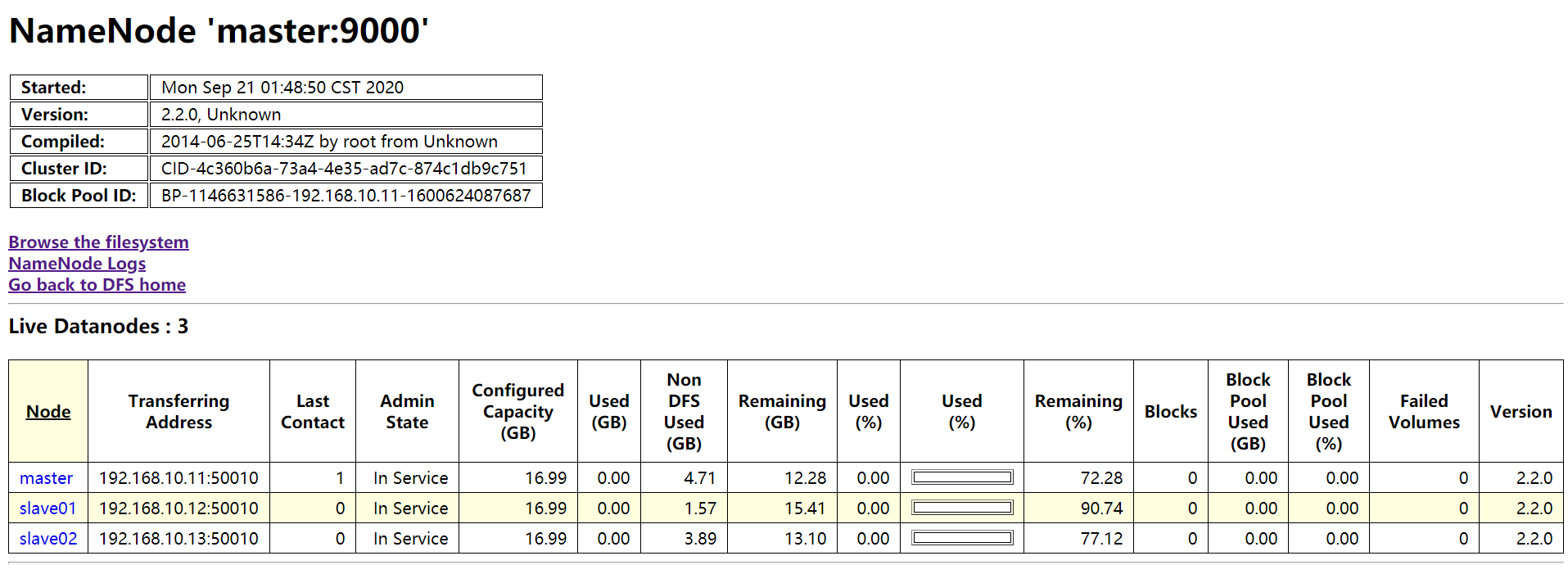
使用浏览器访问: http://192.168.10.11:50070

可看到有三个活跃的datanode,点进去查看,看到如下图所示说明没问题。
常见错误:
2020-09-21 01:42:11,607 INFO org.mortbay.log: Started SelectChannelConnector@0.0.0.0:50075 2020-09-21 01:42:11,954 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened IPC server at /0.0.0.0:50020 2020-09-21 01:42:11,965 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Refresh request received for nameservices: null 2020-09-21 01:42:11,973 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 50020 2020-09-21 01:42:11,979 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting BPOfferServices for nameservices: <default> 2020-09-21 01:42:11,981 WARN org.apache.hadoop.hdfs.server.common.Util: Path /app/hadoop-2.2.0/hdfs/data should be specified as a URI in configuration files. Please update hdfs configuration. 2020-09-21 01:42:11,987 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool <registering> (storage id unknown) service to master/192.168.10.11:9000 starting to offer service 2020-09-21 01:42:12,019 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 50020: starting 2020-09-21 01:42:12,019 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting 2020-09-21 01:42:12,117 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /app/hadoop-2.2.0/hdfs/data/in_use.lock acquired by nodename 6519@master 2020-09-21 01:42:12,118 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool BP-1291136958-192.168.10.11-1600623703239 (storage id DS-1413256501-192.168.10.11-50010-1600622208949) service to master/192.168.10.11:9000 java.io.IOException: Incompatible clusterIDs in /app/hadoop-2.2.0/hdfs/data: namenode clusterID = CID-c4d72e93-4c05-4dcc-adbf-f2cb597aadb7; datanode clusterID = CID-26056e85-5aca-491f-b946-666b5e847dd8 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:391) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:191) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:219) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:837) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:808) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:280) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:222) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:664) at java.lang.Thread.run(Thread.java:748) 2020-09-21 01:42:12,119 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool BP-1291136958-192.168.10.11-1600623703239 (storage id DS-1413256501-192.168.10.11-50010-1600622208949) service to master/192.168.10.11:9000 2020-09-21 01:42:12,220 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool BP-1291136958-192.168.10.11-1600623703239 (storage id DS-1413256501-192.168.10.11-50010-1600622208949) 2020-09-21 01:42:14,221 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Exiting Datanode 2020-09-21 01:42:14,223 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 0 2020-09-21 01:42:14,225 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down DataNode at master/192.168.10.11 ************************************************************/ 2020-09-21 01:49:04,582 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: STARTUP_MSG: /************************************************************
此处为,提前启动没成功,但是已创建,hdfs的数据及临时文件存放目录,删除之后,格式化hdfs,再重启即可