【整体概况】
1.描述最终的代码的实现思路以及关键代码。
2.描述一条咸鱼的挣扎历程和掌握的技能。
3.效能分析,(linux下的性能分析),优化分析和心得体会。
GitHub的链接:https://github.com/Gengzigang/homework1
【代码实现】
一. 实现功能:
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'\0'不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
二. 实现思路
核心功能:统计单词,词组总数,并且找到频率最高的前十个:
单词的数据结构:
typedef struct word_part { string word; int word_num; int flag; }word_part;
第一个是单词本身,第二个是单词出现的频数,第三个是方便读出前十个单词设计的。
用了一个统计单词的hash表和统计词组的三元组表。hash表我用的处理冲突的方法是线性探查法,首先找到一个单词,hash函数为:


1 int i = 0, con = 0; 2 while (word[i] != '\0'&& con <= 7) 3 { 4 if (word[i] >= 'A' && word[i] <= 'Z') 5 { 6 hashnum += (word[i] - 'A') * 14000 / (con + 1); 7 con++; 8 } 9 else if (word[i] >= 'a' && word[i] <= 'z') 10 { 11 hashnum += (word[i] - 'a') * 14000 / (con + 1); 12 con++; 13 } 14 i++; 15 }
这样设计(没有平均分配)主要是考虑到:
①第一个字母相同的很多,前几个字母相同的就很少了。平均分配的话,就冲突会比较多。
②这样各位占的权重不一样,那么hash表就已经基本按字典序排列了。
然后把这个单词的存进hash表里面,返回这个单词在hash表中的位置,把这个位置记录下来,用这个位置在三元组中查找,直到找到有一个空的或者第一元第二元都与之相同的,并且给到三元组的第二元。而之前已经记录的前一个单词的位置,给到同一个三元组的第一元。并且三元组第三元++。这样的话找到一个单词就可以把单词跟它和前一个单词组成的词组记录下来。
用这样的方法,一个三元组就表示了一个词组,cizu[hashnum][0]表示前一个单词的位置,cizu[hashnum][1]表示现在单词的位置,cizu[hashnum][2]表示这个词组出现的次数。
在加入hash表查找的时候,有一个功能特别重要就是按我们自己的比较规则来比较新加入的word和原来在表上的word是否相同。于是我用了一个函数:
int compareword(string word1, string word2);
/*
function:compare word1 with word2;
input:word1,word2
output: IF word1 is the same word with word2:
IF word1 is after word2 in dictionary order,return 1;
IF word1 is before word2 in dictionary order,return -1;
IF word1 is different word with word2,return 3;
IF error return 0;
*/
1 int compareword(string word1, string word2) 2 { 3 int flag; 4 int i, j; 5 int big_flag; 6 7 i = word1.length() - 1; 8 j = word2.length() - 1; 9 10 while (i >= 0) 11 { 12 if (word1[i] >= '0'&&word1[i] <= '9') word1[i] = '\0'; 13 else break; 14 i--; 15 } 16 while (j >= 0) 17 { 18 if (word2[j] >= '0'&&word2[j] <= '9') word2[j] = '\0'; 19 else break; 20 j--; 21 } 22 flag = _strcmpi((char*)word1.data(), (char *)word2.data()); 23 if (flag != 0) return 3; 24 else { 25 big_flag = strcmp((char *)word1.data(), (char *)word2.data()); 26 if (big_flag == 0) big_flag++; 27 return big_flag; 28 } 29 }
边缘功能:
1.字符统计,单词统计,行数统计,字符统计按照指针每加一,就判断一次是不是标准字符,然后字符数++,其他的都是各种逻辑运算来写。
2.判断是不是单词。这个也是用纯逻辑来写的,考虑到各种情况。按照每循环一次必须读到一个单词,这种思路来写。
这个功能比较烦,逻辑也比较多。事实上就是考虑到各种情况就可以了。
至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。 英文字母:A-Z,a-z 字母数字符号:A-Z,a-z,0-9 分割符:空格,非字母数字符号 例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。 如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同 输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
1 while (*p != '\0') 2 { 3 if (*p eq '\n') 4 { 5 count_lines++; 6 p++; 7 if (*p >= 32 && *p <= asciim) count_characters++; 8 } 9 else if (*p >= 32 && *p <= asciim) //get one letter after one loop 10 { 11 word_len = 0; 12 word_now = ""; 13 14 while (!((*p >= 'a'&&*p <= 'z') || (*p >= 'A'&&*p <= 'Z'))) //when *p is not letter,then only count it and skip 15 { 16 p++; 17 if (*p == '\0')break; 18 if (*p eq '\n') break; 19 if (*p >= 32 && *p <= asciim) count_characters++; 20 } 21 22 if (*(p - 1) >= '0'&&*(p - 1) <= '9') //123a is not word 23 { 24 while ((*p >= 'a'&&*p <= 'z') || (*p >= 'A'&&*p <= 'Z') || (*p >= '0'&&*p <= '9')) 25 { 26 p++; 27 if (*p >= 32 && *p <= asciim) count_characters++; 28 } 29 continue; 30 } 31 32 while (((*p >= 'a'&&*p <= 'z') || (*p >= 'A'&&*p <= 'Z')) && word_len<4) 33 { 34 word_now.push_back(*p); 35 word_len++; 36 p++; 37 if (*p >= 32 && *p <= asciim) count_characters++; 38 } 39 40 if (word_len >= 4) //find a word successfully 41 { 42 while ((*p >= 'a'&&*p <= 'z') || (*p >= 'A'&&*p <= 'Z') || (*p >= '0'&&*p <= '9')) 43 { 44 word_now.push_back(*p); 45 p++; 46 if (*p >= 32 && *p <= asciim) count_characters++; 47 } 48 count_words++; 49 hashadd(word_now); 50 } 51 else //the situation that asd123 52 { 53 while ((*p >= 'a'&&*p <= 'z') || (*p >= 'A'&&*p <= 'Z') || (*p >= '0'&&*p <= '9')) 54 { 55 p++; 56 if (*p >= 32 && *p <= asciim) count_characters++; 57 } 58 } 59 } 60 else 61 { 62 p++; 63 if (*p >= 32 && *p <= asciim) count_characters++; 64 } 65 }
3.判断文件夹与文件,并且递归文件夹里面的所有子文件,也是一个简单的递归就可以做到。
All file of path
4.用命令行来输入一个路径。这就是用main函数的参数。argc和argv可以做到:argc指的是传入的参数个数,包括文件名本身。argv是传入的参数,第一个是文件名,其他的就是你输入的。
5.输出频数最高的前十位:这个算法有点慢,采用暴力遍历。不过不关紧要,只有前十位。词组也是这种方法。
1 int Select() { 2 int i, j = 0, max, maxi; 3 while (j < 10) { 4 max = 0; 5 maxi = 0; 6 for (i = 0; i < MAXHASH; i++) 7 { 8 if (hashat[i].word_num > max && hashat[i].flag == 0) 9 { 10 max = hashat[i].word_num; 11 maxi = i; 12 } 13 } 14 if (max != 0) 15 { 16 hashat[maxi].flag = 1; 17 fprintf(fp, "%d:%s,its number is %d\n", j + 1, (char*)hashat[maxi].word.data(), hashat[maxi].word_num); 18 } 19 else fprintf(fp, "%d does not exist\n", j + 1); 20 j++; 21 } 22 return 0; 23 }
三.最终完成
最终完成版本,遍历给的sample文件夹,用时14s,读出的跟助教的词组都一样。单词的话,我发现我每运行一次程序,得出的结果都不一样,但都和助教的相差在5之内,而且每次都只有1-2个单词数不一样。但是行数,单词数相差不到80,字符数差300,我想这是对这些不同的理解,定义造成的。毕竟文件真的太大了,这些误差在可以接受范围内。
1:THAT,its number is 259186 2:SAID,its number is 208861 3:CLASS,its number is 192006 4:HARRY,its number is 184732 5:WITH,its number is 158745 6:THIS,its number is 152454 7:THEY,its number is 145945 8:Span,its number is 116120 9:HAVE,its number is 107383 10:FROM,its number is 105494 ----------- 1 : Span CLASS,its number is 62861 2 : THAT GOOD,its number is 61427 3 : Span Span,its number is 41286 4 : CLASS Reference,its number is 31289 5 : Reference INTERNAL,its number is 26668 6 : INTERNAL href,its number is 26668 7 : SAID HARRY,its number is 24981 8 : CLASS Span,its number is 23146 9 : href LEAP,its number is 22569 10 : SAID HERMIONE,its number is 19193 word is 16630032 character is173654668 line is2278465
【咸鱼的挣扎历程与get的新技能】
3月22日下午:开始。
接收到这个作业,目瞪口呆,思维混乱,完全不知所措。(主要是啥命令行输入,github管理,PSP表格以前听都没听过,还有一堆堆的单词的特殊定义。。。还有瞬间想到的各种没有明确规定的带有主观性的东西 )。
3月22日晚上6:00-6:10 :PSP表格
不管怎样,先开始了解一下PSP表格这种主观性比较强的东西把,于是晚上构思了一下时间,进度安排。以下是我的PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1140 | 1910 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 60 |
| · Design Spec | · 生成设计文档 | 120 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 10 |
| · Design | · 具体设计 | 240 | 180 |
| · Coding | · 具体编码 | 480 | 480 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 1080 |
| Reporting | 报告 | 180 | 150 |
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 1350 | 2000 |
这就是我得PSP表格,可以看到除了测试,其他的都还好。为什么测试会这么长呢。。。。。具体原因随后慢慢道来。。
3月22日晚上6:10-6:40:内心想法。
这道题目让人看起来眼花缭乱,特别是它有别于常理的各种乱七八糟的规定。但是静下心来梳理了一下,发现这些规定中有的是为了增加点难度,而有的是巧妙地方法会让难度降低一些。
后来自己梳理了一下,发现还是有很多bug没有规定明确的,所以说把他们列出来一一问了老师:比如说 ,有汉字怎么办,word123a12和word123a12a不是一个单词,那么word123a12a12和word123a12a算不算一个单词,有jpg怎么办,等等。
发现后一种规定会让问题简单一些,那就是除了后面的单词,只要前面的相同就可以了。
3月22日晚上6:40-9:40:写需求文档,代码规范。
梳理了一下题目,想了各种需求分析,设计文档,并且把他们记录下来。参照老师上课讲的东西,给自己建立了一份代码的注意事项:
注意:
①模块小一些,降低耦合。
②边开发,边测试,及时排错,小口吃饭。
③分支,重复计算,函数调用应该尽可能避免。
④函数接口尽可能简化。
⑤减少全局变量。
⑥函数入口参数检查,变量初始化检查。特别重要:文件打开,是否存在,内存分配。
⑦空指针检测,数组越界,分母为0。
⑧命名规则:高区分度,统一。
⑨代码行尽可能短。适度空行,代码子块化。
⑩多用宏和枚举,尽量不要用常数(魔鬼数)(这个是我以前经常忽略的问题)。用宏# define eq ==也是一个比较好的做法。
3月24日早上10:00到中午11:00:构思
构思,并且开始编码。我得编码思路是:因为我对多文件处理还没有接触过,所以我选择先从单个文件入手,编写完核心功能,然后再拓展到多文件这些附加功能。我编写了打开单个文件,按字符去读,统计行数,字符数,并且找到单词,然后测试了这个在一个文本中找单词的功能,发现做的还挺好的,各种情况都有考虑:123asd,123asdf,asd212,asdf123asdaf等等。
3月24日晚上7:00到晚上11:00:解决word,单词。
编写了把找到的单词加入到hash表的功能,解决冲突用了线性探查法,我初步预计了英文单词一共也就50000,于是hash开了100000的空间(这种想当然的想法给我后来三天的调试suffering带来了极其不好的体验,单词不一定是英文单词等等,反正hash表不能开的这么扣),又编写了把在单词紧接着的一个单词加成它的hash表中的拉链的方法(后来get了更好的方法),又编写了给hash表按照字典序排序的方法(因为hash函数决定他已经按字典序基本有序,所以我用了冒泡排序法。这一条是因为我觉得题目表达不清,我以为要都用字典序排序输出),最后写了一下取单词和词组的前十。
3月25日上午9:00到上午11:00:联合调试。
把昨天写好的各个基本功能联合在一起,进行联合测试,用多个txt文件,发现运行的挺好的,输出也合情合理。觉得大功告成。(其实suffer才刚刚开始)。
3月25日下午2:00到晚上11:00:遍历文件夹与遭遇挫折。
在网上学习了怎么打开文件夹,怎么判断文件夹与文件,怎么获取文件名字符串等一系列操作,并且自己写了一个递归查看文件夹里面所有文件的函数,感觉还挺容易的。以前都是用C写,很明显C在这个文件操作就有点吃亏,从读文件开始边学边用C++,写完之后,发现可以用,而且很好用。所以就开始用助教给的sample来测。。。
不测不知道,一测吓一跳。开始跑了,一分钟一个min.map那种程序文件,等了两个小时后,到文本文件根本动不了了。。。于是群里面有人说不要用debug模式,用release模式,最大速度优化,不产生调试信息。心头一喜,赶紧了解了release模式,然后用起来。
然而,并没有多大改变,我就想着是不是打开性能分析器优化一下,发现性能分析器也是要跑程序的。。然而我的程序就跑不动。折腾了一下午,一晚上,在等待的过程,我get到了初步的性能分析器的使用,于是试了一下,发现我得竟然自动不显示热行,问东问西,都不知道。这下就悲剧了。(其实那时候有性能分析器也没啥用)。平时的技术小白心理觉得我肯定有哪些算法太差了,但是我觉得我起码跑得慢但是能跑对,于是电脑开了一晚上来跑程序。用100000的hash表来对抗那么多KB的文件。。。。晚上一直调到1点多没希望。然后跑着程序就睡了,希望第二天可以看到正确结果。
3月26日上午6:00,中午12点到下午5点:VS性能分析器迷之打不开,后来自动就好了。
起床发现程序意外中断了,难道是我算法上有漏洞?啥没有考虑到,然而现在也没有debug信息,于是一行一行看代码,倒是发现了几个无关紧要的函数返回信息没判断等等,于是上午上课的时候又开着程序跑,还是很慢,中午发现又挂了,发现了挂在哪个文件上面,是一个叫 我的生活.txt 的文件,每次都是,单独拿出来测试,很快而且完全没有错误,后来我猜,hash链太长了,内存不够,这可怎么办,一方面速度太慢无从优化,另一方面程序出不来结果。用一个文件来看热行,根本无济于事,而且热行还是打不开,无奈之下,一行一行看代码,打算重新写一下,又不知道别人的算法怎么那么强,这时几万倍的差距。开始了我自己为的优化之路。
从3月26日晚上6点开始,开启了我自以为的优化程序道路:
①别人说char *不会变长,可能会炸。于是我学了string类,并把所有的用C写的char *都改成了C++的string,无济于事。
②觉得词组拉链是不是太占用时间,先把词组功能去掉吧,变成只有单词的,发现还是要读好几个小时。
③只有单词还这么慢就有些奇怪了,我想我得hash算法再差也不至于差到这种程度把。。
④修改hash值,把原先的单词先四位加权相加得到的hash值修改为前n位相加,然而并没什么用。
⑤又听说char *要比string快一些,又把string都改回了char *。
⑥我以前自己写的compareword函数有些繁琐,改进了一下使用了自己改造过的系统的stricmp这个函数。
但是,这些措施都一点用都没有。一直到3月27日下午,我觉得我不想继续做了,要做也得重写。
3月27日晚上7:00:茅塞顿开,发现了以前愚蠢的bug
正当我看着电脑不知所措的时候,突然想到随便折腾吧,反正这个程序也不行了,凉就凉透点吧。
情况发生了突变,我把hash表开到了300000,发现快了好多好多,突然想到原来是这么回事。我们所说的单词并不仅仅是英文单词。还有很多,这样的话hash开50000是个很不明智甚至是极其错误的决定。千算万算没有算到这一点。
之后我就一直暴力开大hash表的空间,发现程序越跑越快,非常开心,又很悔恨自己的经验太少,以至于这几天一直爆肝。
3月27日晚上7:00到晚上11:00:换词组存储的算法。
加入了词组的功能,想了一下不用散列存词组了,换成了给词组编号,然后数组存词组编号的算法(相当于又开了个hash表),果然方便多了,于是整体测试,加入了一些边边角角的小功能。跑了一次,发现和助教的单词和词组都一致,然后其他的误差也挺小,用了14s,终于告一段落了,松了一口气。
3月28日一整天断断续续:陷入了迷之bug,程序跑一次结果都会差一点点,1个或3个。
跑了一次,发现和助教的词组都一样,怎么单词突然有一个span多了一个呢?不敢相信,明明昨天好好的,然后又跑了一次,为啥单词跟刚才的又不一样,span对了CLASS又多了一个呢?很迷,又一直跑,发现每次得出的结果都不一样(这就很迷了),于是我问了同学,他们说内存是不是溢出了,于是把hash开的小一些,没用。想着既然class多了一个,那我就把所有的class输出,我看一下有哪种漏网之鱼是我没考虑到的情况,结果没发现,而且他跟助教的又一模一样了。
后来想了一下,只跑txt文件。发现没有玄学错误。每次跑出来都一样。又找作对的同学对了一下,没错误。都一样。这说明我得算法,我的各种程序功能还是实现了。
跑了一下乱七八糟格式的文件,发现每次跑出来都不一样,但是相差在3个单词以内,问题锁定了,是文件格式的锅,各种百度,然而真的无法解决了。我觉得我尽力了。。。而且结果也比较好吧,词组都一样,单词也大都一样。相差也是1个。
ddl也快到了。
3月29日傍晚:移植linux大翻大折惊险操作
突然得知程序必须移植到linux系统下面跑,所以说我开始慌了,这么短时间来装linux显然是对我这个从没接触过linux的小白是不可能的,所以找小伙伴一起找有linux的人,于是找到了班长,帮了我们一晚上。(特别感谢)。于是我就改代码,代码没多少要改的。以下是对代码的改动:
①C++头文件<io.h>在linux下不能用了,改成了<dirent.h>,然后它里面的函数刚好可以在linux下找到替代,所以就不慌了,按照功能替换了一下。
在linux上测试,在linux下可以遍历文件夹,说明改的没问题。
②有一个c++里面忽略大小写比较字符串的函数stricmp,在linux下不能用,于是改成了linux下功能相同的strcasecmp,也测试过功能相同。
但是就在一切可以编译,可以运行的时候,看结果,大吃一惊,怎么回事。词组可以很正常的显示,数目也一致。单词完全显示不了,是一堆乱码。要知道我得单词printf是完全copy的词组。而且词组也是从单词的hash表里面printf单词的。完全想不通为什么。调试了一晚上也没发现有什么bug。
重复移植了好几次,还是不行。这跨平台的问题,对于我这种小白来说,真的一点头绪都没有。只能不停尝试。但是到了ddl也没出来,想着交了吧,反正词组做出来了,单词也做出来了(因为我得单词功能是词组的一个子功能)(词组都出来了,单词没道理错),但就是输出不了。至少把能想到的方案都试过了,没办法。硬着头皮进行性能分析把。
【优化与总结】
linux下的性能分析:
好,我的程序在linux下词组是对的,说明我得算法没问题,而且程序也都执行到了。因为词组是单词的高级功能。所以小白开始进阶linux下的性能分析:
首先,linux下跑了一下我的代码:
g++ wenwen.cpp ./a.out newsample/
跑出来结果,接下来用了一下linux最基础的功能,也是计算时间比较好的一个函数。因为gprof只能分析应用程序在运行过程中所消耗掉的用户时间,无法得到程序内核空间的运行时间。所以说,用time程序结束后会有一个总的运行时间和系统运行时间以及用户态时间。
接下来我想用gprof来分析一下flat profile和call graph,所以用了一下命令:
g++ -pg wenwen.cpp ./a.out gprof a.out gmon.out //wenwen.cpp是我的程序名 //a.out是系统默认的可执行文件的文件名称 //gmon.out是-pg运行下生成的信息文件
然而,和我VS性能分析器一样,折腾了一下午一晚上。最后不是我的问题,我也不知道谁的问题。也许是我的问题,但是我真的没做什么他就第二天好了。gprof跪了,我问了google,baidu问了身边的同学,他们都这样操作就可以出结果,但是我就是不行。我把网上提供的例程,方法都试过,就是不行,我不知道我漏掉了什么细节。只希望过路的大神dalao能解决我这种低级问题一定要告诉我一下,万分感谢。好,我性能分析的结果如下:表面上有模有样的,连flat profile,call graph的表格都给你列出来列好了。
好,这就是我get到的linux性能分析hhhhhhhhhhhh。(如果有dalao路过发现问题,一定要告诉博主,万分感谢)。
优化:
在一直被hash表大小困住的情况下,进行了一系列不用性能探查器的优化。包括算法啊,函数调用啊,等等。虽然效果不是很大。但我觉得有的算法还是蛮好的:
①词组用开链表来处理,改成了给每个单词编号用一个数组来处理。
②比如说把strcmp这种费时间的函数放到if里面去,能不用就尽量不用。
③我的优化基本上就是调两个hash大小,真的对性能有很大帮助。从14小时变到了14s。。。
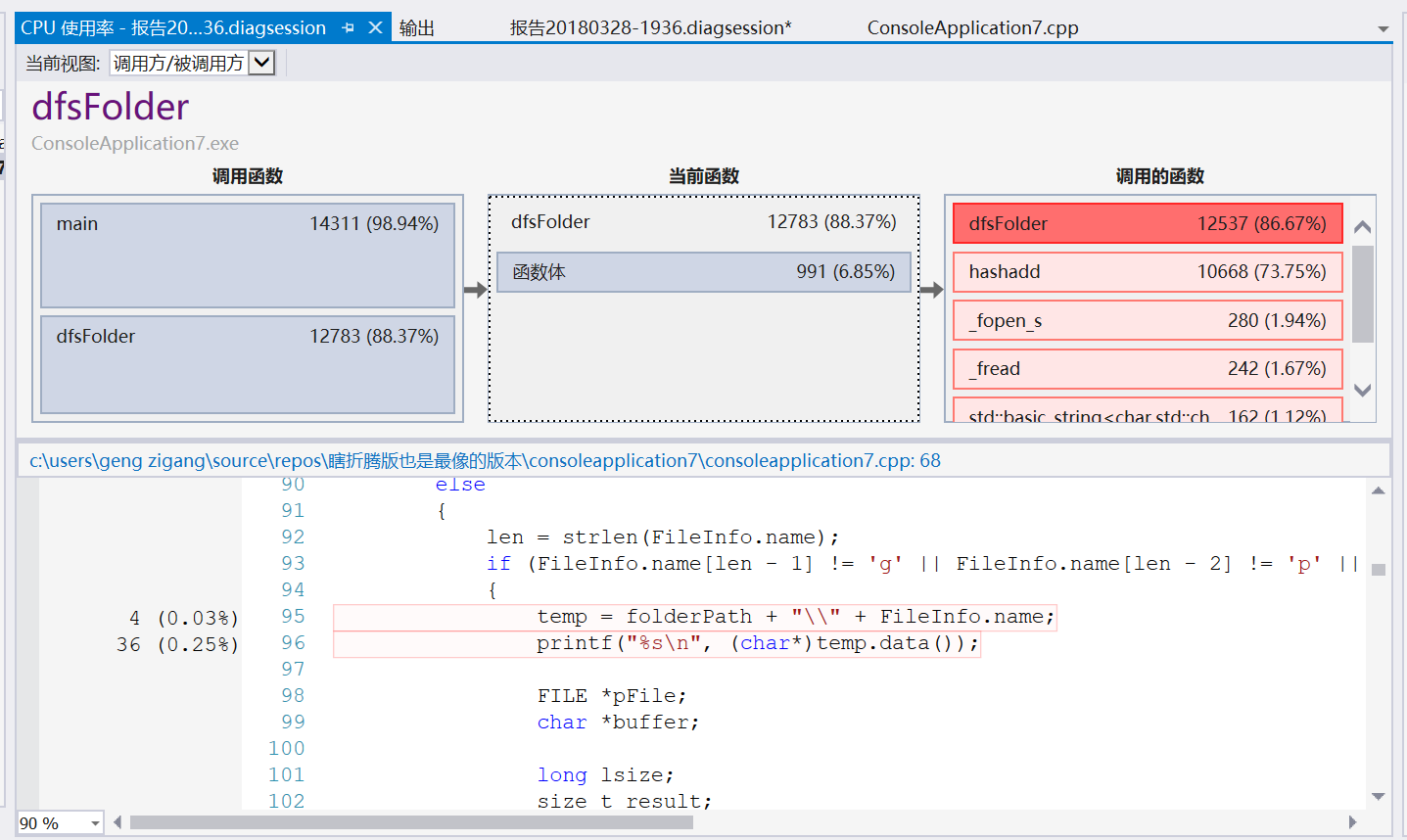
开热行分析。发现了几个可有可无的语句,把他们删掉,其实对速度没多大提升。
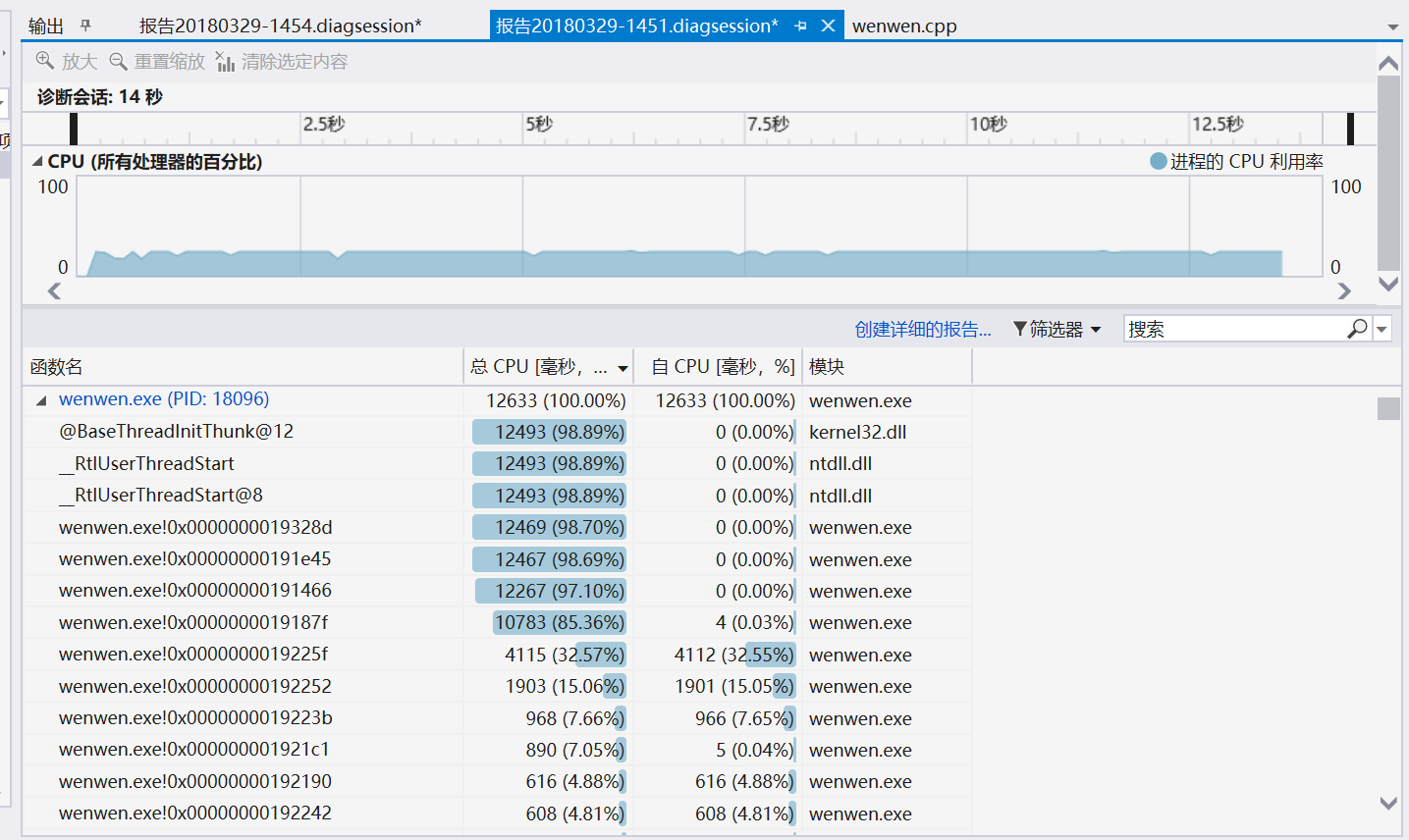
这就是我的函数关系图。
总结与体会:
①感觉以后真的不用再用纯C语言硬刚了。。小白看到群里面的dalao讲各种名词,重构,啥unordered map各种东西一脸懵逼,啥都不知道。而且似乎C++好用很多。感觉以后真的要努力更新技能了,不然的话,软件路中的suffer还会有很多。
②还有各种工具一定要用起来,真的会很方便,比如debug,比如性能分析器。
③遇到问题一定要多与别人交流,千万不要闭门造车。我如果一开始就跟别人交流的话,也不会在hash表的大小这么明显的问题上面载这么大的跟头。然而自己调试了3天,突然发现了这么一个幼稚的bug,后悔莫及。
一只咸鱼还要努力学习。差得还很远,知识上和经验上。