集群节点
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点 通过node.name指定节点的名称。
在Elasticsearch中,节点的类型主要有4种:
master节点
- 配置文件中node.master属性为true(默认为true),就有资格被选为master节点。
- master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。
data节点
- 配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。
- data节点主要用于执行数据相关的操作。比如文档的CRUD。
客户端节点
- 配置文件中node.master属性和node.data属性均为false。
- 可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点
部落节点
- 当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行 搜索和其他操作。
搭建集群
环境
系统:CentOS 7.4
ES版本:7.6.1
由于es安装需要配置一些系统参考,安装集群前,请保障单机版的ES安装成功,单机版参考:【ElasticSearch】 ElasticSearch安装(一)
示例说明:本例由于资源有限,ES集群安装三个节点在同一台服务器上,正式安装可将节点分配到不同机器上
架构如下:
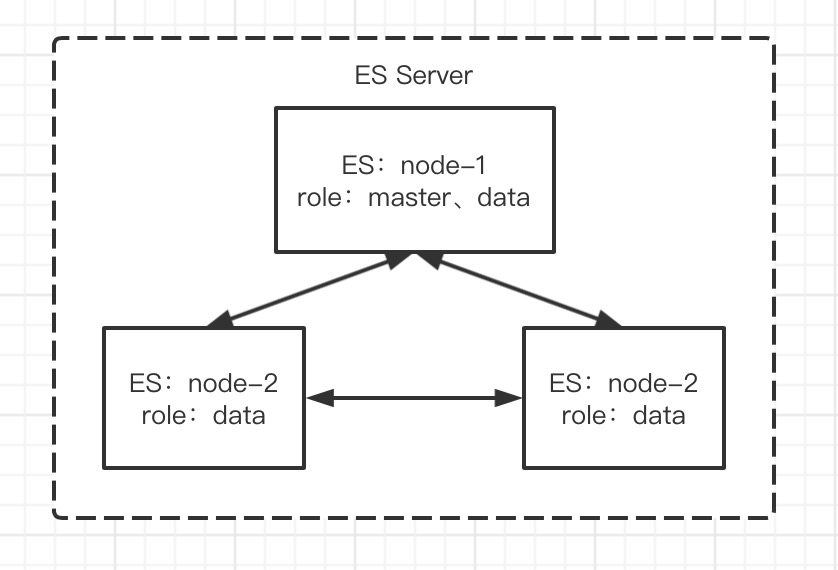
1、新建一个ES集群目录
命令:mkdir /data/soft/elasticsearch-cluster
2、解压es到集群目录中
命令:tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /data/soft/elasticsearch-cluster
3、进来集群目录,拷贝三分实例
命令:cd /data/soft/elasticsearch-cluster
命令:cp -rf elasticsearch-7.6.1 elasticsearch-7.6.1-19201
命令:cp -rf elasticsearch-7.6.1 elasticsearch-7.6.1-19202
命令:cp -rf elasticsearch-7.6.1 elasticsearch-7.6.1-19203
4、编辑三个节点的配置信息
node-1配置信息如下:
1 # ---------------------------------- Cluster ----------------------------------- 2 # 设置集群名称,集群内所有节点的名称必须一致。 3 cluster.name: my-application 4 5 # ------------------------------------ Node ------------------------------------ 6 # 节点名称 7 node.name: node-1 8 # 表示该节点会不会作为主节点,true表示会;false表示不会 9 node.master: true 10 # 当前节点是否用于存储数据,是:true、否:false 11 node.data: true 12 13 # ----------------------------------- Paths ------------------------------------ 14 # 索引数据存放的位置 15 #path.data: /path/to/data 16 # 日志文件存放的位置 17 #path.logs: /path/to/logs 18 19 # ----------------------------------- Memory ----------------------------------- 20 # 需求锁住物理内存,是:true、否:false 21 #bootstrap.memory_lock: true 22 23 # ---------------------------------- Network ----------------------------------- 24 # 绑定IP地址 25 network.host: 0.0.0.0 26 27 # 绑定到传入HTTP请求的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 28 # 默认 9200-9300 29 http.port: 19201 30 # 用于绑定节点之间通信的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 31 # 默认 9300-9400 32 transport.tcp.port: 19301 33 34 # --------------------------------- Discovery ---------------------------------- 35 # 提供群集中符合master资格的节点的地址列表。也可以是包含用逗号分隔的地址的单个字符串。 36 # 该节点启动时,发现的主机的初始列表 37 # 每个地址的格式为host:port或host。 38 discovery.seed_hosts: ["127.0.0.1:19301", "127.0.0.1:19302", "127.0.0.1:19303"] 39 40 # 设置全新群集中符合master要求的节点的初始集合。 41 # 默认情况下,该列表为空,这意味着该节点希望加入已经被引导的集群 42 cluster.initial_master_nodes: ["node-1"]
node-2配置信息如下:


1 # ---------------------------------- Cluster ----------------------------------- 2 # 设置集群名称,集群内所有节点的名称必须一致。 3 cluster.name: my-application 4 5 # ------------------------------------ Node ------------------------------------ 6 # 节点名称 7 node.name: node-2 8 # 表示该节点会不会作为主节点,true表示会;false表示不会 9 node.master: true 10 # 当前节点是否用于存储数据,是:true、否:false 11 node.data: true 12 13 # ----------------------------------- Paths ------------------------------------ 14 # 索引数据存放的位置 15 #path.data: /path/to/data 16 # 日志文件存放的位置 17 #path.logs: /path/to/logs 18 19 # ----------------------------------- Memory ----------------------------------- 20 # 需求锁住物理内存,是:true、否:false 21 #bootstrap.memory_lock: true 22 23 # ---------------------------------- Network ----------------------------------- 24 # 绑定IP地址 25 network.host: 0.0.0.0 26 27 # 绑定到传入HTTP请求的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 28 # 默认 9200-9300 29 http.port: 19202 30 # 用于绑定节点之间通信的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 31 # 默认 9300-9400 32 transport.tcp.port: 19302 33 34 # --------------------------------- Discovery ---------------------------------- 35 # 提供群集中符合master资格的节点的地址列表。也可以是包含用逗号分隔的地址的单个字符串。 36 # 该节点启动时,发现的主机的初始列表 37 # 每个地址的格式为host:port或host。 38 discovery.seed_hosts: ["127.0.0.1:19301", "127.0.0.1:19302", "127.0.0.1:19303"] 39 40 # 设置全新群集中符合master要求的节点的初始集合。 41 # 默认情况下,该列表为空,这意味着该节点希望加入已经被引导的集群 42 cluster.initial_master_nodes: ["node-1"]
node-3配置信息如下:
1 # ---------------------------------- Cluster ----------------------------------- 2 # 设置集群名称,集群内所有节点的名称必须一致。 3 cluster.name: my-application 4 5 # ------------------------------------ Node ------------------------------------ 6 # 节点名称 7 node.name: node-3 8 # 表示该节点会不会作为主节点,true表示会;false表示不会 9 node.master: true 10 # 当前节点是否用于存储数据,是:true、否:false 11 node.data: true 12 13 # ----------------------------------- Paths ------------------------------------ 14 # 索引数据存放的位置 15 #path.data: /path/to/data 16 # 日志文件存放的位置 17 #path.logs: /path/to/logs 18 19 # ----------------------------------- Memory ----------------------------------- 20 # 需求锁住物理内存,是:true、否:false 21 #bootstrap.memory_lock: true 22 23 # ---------------------------------- Network ----------------------------------- 24 # 绑定IP地址 25 network.host: 0.0.0.0 26 27 # 绑定到传入HTTP请求的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 28 # 默认 9200-9300 29 http.port: 19203 30 # 用于绑定节点之间通信的端口。接受单个值或范围。如果指定了范围,则该节点将绑定到该范围中的第一个可用端口, 31 # 默认 9300-9400 32 transport.tcp.port: 19303 33 34 # --------------------------------- Discovery ---------------------------------- 35 # 提供群集中符合master资格的节点的地址列表。也可以是包含用逗号分隔的地址的单个字符串。 36 # 该节点启动时,发现的主机的初始列表 37 # 每个地址的格式为host:port或host。 38 discovery.seed_hosts: ["127.0.0.1:19301", "127.0.0.1:19302", "127.0.0.1:19303"] 39 40 # 设置全新群集中符合master要求的节点的初始集合。 41 # 默认情况下,该列表为空,这意味着该节点希望加入已经被引导的集群 42 cluster.initial_master_nodes: ["node-1"]
5、依次启动node-1、node-2、node-3
查看集群
1、使用elasticsearch-head插件连接,ES集群
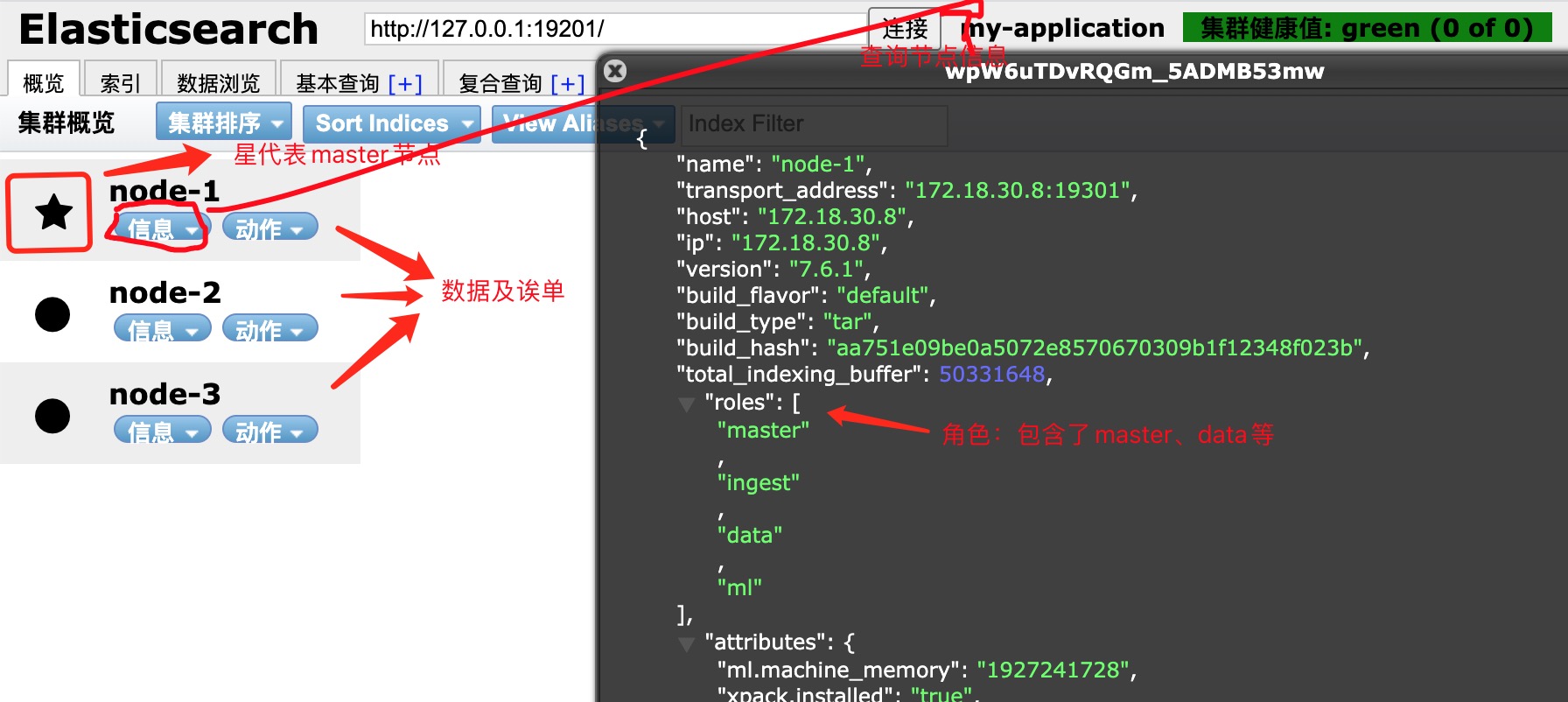
星代表master(主节点)
圆代表data(数据节点)
roles角色:master(主节点)、data(数据节点)、ingest(提取节点)、ml(机器学习节点)
2、创建索引
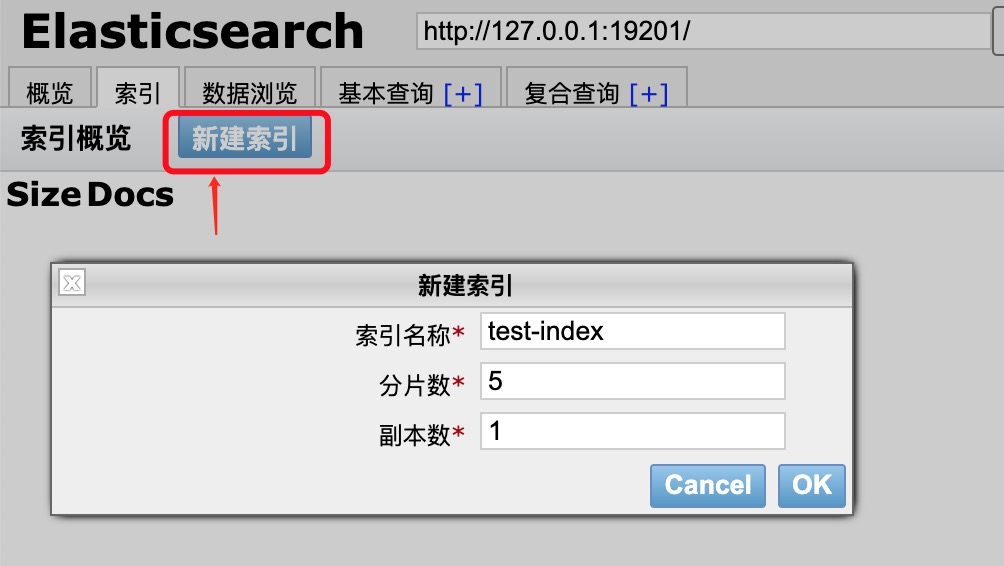
效果如下:

3、查询集群状态:/_cluster/health
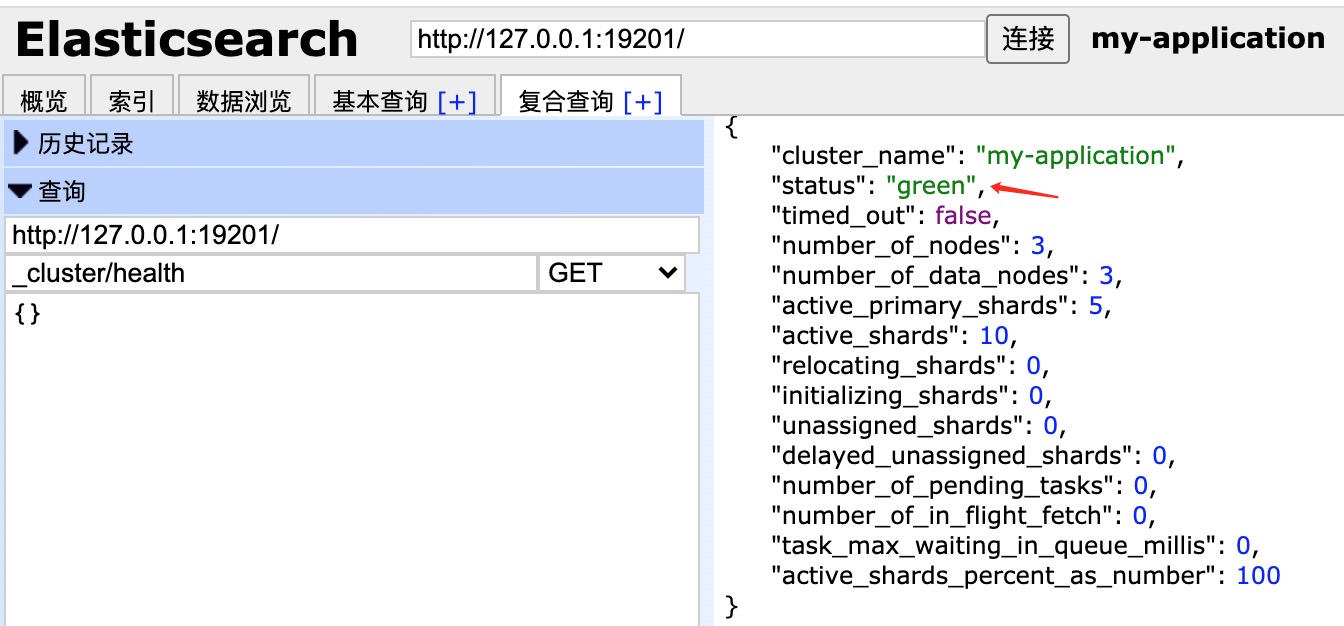
集群状态的三种颜色:
-
- green:所有主要分片和复制分片都可用
- yellow: 所有主要分片可用,但不是所有复制分片都可用
- red: 不是所有的主要分片都可用