0×01 前言
前两天在百家号上看到一篇名为《反击爬虫,前端工程师的脑洞可以有多大?》的文章,文章从多方面结合实际情况列举了包括猫眼电影、美团、去哪儿等大型电商网站的反爬虫机制。的确,如文章所说,对于一张网页,我们往往希望它是结构良好,内容清晰的,这样搜索引擎才能准确地认知它;而反过来,又有一些情景,我们不希望内容能被轻易获取,比方说电商网站的交易额,高等学校网站的题目等。因为这些内容,往往是一个产品的生命线,必须做到有效地保护。这就是爬虫与反爬虫这一话题的由来。本文就以做的较好的“猫眼电影”网站为例,搞定他的反爬虫机制,轻松爬去我们想要的数据!
0×02 常见反爬虫
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。而作为程序员的我们只关心数据采集部分,处理什么的还是交给那些数据分析师去搞吧。
一般来说,大多数网站会从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫,而第三种则相对比较特殊,一些应用ajax的网站会采用,这样无疑会增大了爬虫爬取的难度。
然而,这三种反爬虫策略则早已有应对的方法和策略。如果遇到了从用户请求的Headers反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。对于基于用户行为的反爬虫其实就是通过限制同一IP短时间内多次访问同一页面,应对策略也是很粗暴——使用IP代理,可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。有了大量代理ip后可以每请求几次更换一个ip,即可绕过这种反爬虫机制。对于最后一种动态页面反爬虫机制来讲,selenium+phantomJS框架能够让你在无界面的浏览器中模拟加载网页的动态请求,毕竟selenium可是自动化渗透的神器。
0×03 猫眼反爬虫介绍
介绍完常见的反爬虫机制,我们回过头看看我们今天的主角:猫眼电影的反爬虫是什么样的。
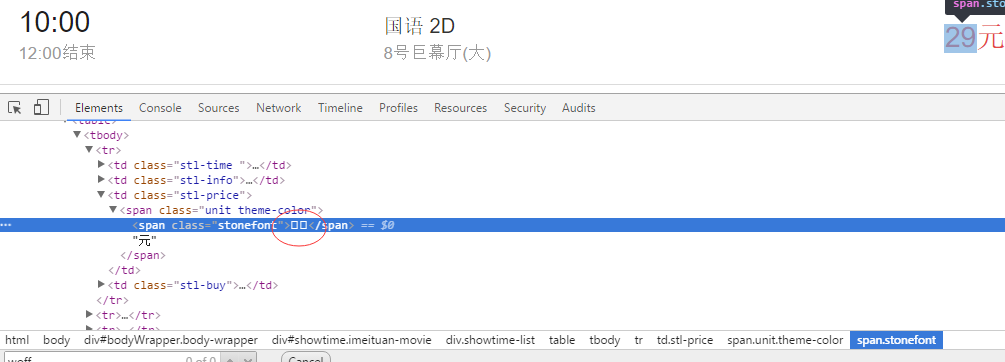
对于每日的电影院票价这一重要数据,源代码中展示的并不是纯粹的数字。而是在页面使用了font-face定义了字符集,并通过unicode去映射展示。简单介绍下这种新型的web-fongt反爬虫机制:使用web-font可以从网络加载字体,因此我们可以自己创建一套字体,设置自定义的字符映射关系表。例如设置0xefab是映射字符1,0xeba2是映射字符2,以此类推。当需要显示字符1时,网页的源码只会是0xefab,被采集的也只会是 0xefab,并不是1:

因此采集者采集不到正确的票价数据:
采集者只能获取到类似的数据,并不能知道””映射的字符是什么,实现了数据防采集。而对于正常访问的用户则没有影响,因为浏览器会加载css中的font字体为我们渲染好,实时显示在网页中。也就是说,除去图像识别,必须同时爬取字符集,才能识别出数字。
查看猫眼的网站源文件正是如此:

所有的票价信息都是由动态font字体“加密”后得到的。既然知道了原理,我们就继续发掘,通过分析网站HTML结构,我们发现网站每次渲染票价的font字体都可以在网页的script标签中被找到:

字体是由base64加密后存储在网页中的,于是乎,上python:
#将base64加密的font文件解密转存本地
font = re.findall(r"src: url(data:application/font-woff;charset=utf-8;base64,(.*?)) format",response_all)[0]
fontdata=base64.b64decode(font)
file=open('/home/jason/workspace/1.ttf','wb')
file.write(fontdata)
file.close() 我们在爬取时将font文件解密后存储在本地存储为ttf文件,留做备用。
前文提到过这种web-font定义了字符集,要通过unicode去映射展示,所以,我们要构建ttf字体文件中unicode映射出来的字符字典:

python代码:
import fontforge
def tff2Unicode():#将字体映射为unicode列表
filename = '/home/jason/workspace/1.ttf'
fnt = fontforge.open(filename)
for i in fnt.glyphs():
print i.unicode
我们猜测映射关系如下:

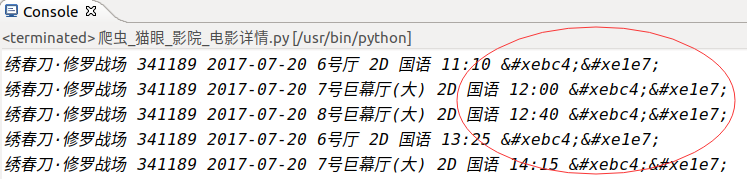
还记得嘛,第三张图我们爬取到的数据是“绣春刀·修罗战场 341189 2017-07-20 6号厅 2D 国语 11:10 ”,我们将“&#”替换成“0”后对应上表得出的票价不是刚好是“29”嘛!
python代码:
tmp_dic={}
ttf_list = []
def creatTmpDic():#创建映射字典
tmp_dic={}
ttf_list = []
num_list = [-1,-1,0,1,2,3,4,5,6,7,8,9]
filename = '/home/jason/workspace/1.ttf'
fnt = fontforge.open(filename)
ttf_list = []
for i in fnt.glyphs():
ttf_list.append(i.unicode)
tmp_dic = dict(zip(ttf_list,num_list))#构建字典
return tmp_dic,ttf_list
def tff2price(para = ";",tmp_dic={},ttf_list = []):#将爬取的字符映射为字典中的数字
tmp_return = ""
for j in para.split(";"):
if j != "":
ss = j.replace("&#","0")
for g in ttf_list:
if (hex(g) == ss):
tmp_return+=str(tmp_dic[g])
return tmp_return
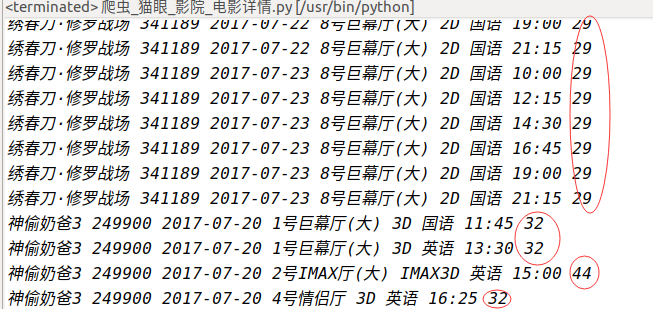
好的,到此,我们已经可以说已经完成了对票价“加密”数据的破解啦~还是有点小小的成就感呢!但是,这里面还是有个很坑的地方:开发者已经想到采集者可以通过分析,知道每一个映射代表的意思,从而进行采集后转换处理,所以我们每次访问都是随机得到一种字体,而且开发者还定期更新一批字体文件和映射表用来加大采集的难度,所以我们在采集的过程中不得不每采集一个页面就更新一次本地的该网页的web-font字体,无疑会大大增加爬虫的爬取成本和爬取效率,所以从一定意义上确实实现了反爬虫。
参考文献:
http://blog.csdn.net/fdipzone/article/details/68166388
https://baijiahao.baidu.com/s?id=1572788572555517&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/20520370?columnSlug=python-hacker