- 数组越界
数组越界,是刚开始学习编程时,就不断被别人提醒的一个点,“相当可怕”。获取不合理数值,造成程序异常or操作计算机重要内存,造成威胁。。。原因是什么呢?数组在汇编中以栈机制实现,汇编中数组的内存的分配方式与数组越界的风险有很大关系。今天做个小实验,来简单探讨下这个。并拓展一下,这样的“小问题”跟汇编中的函数调用框架结合起来形成的更严重的问题。
- 代码
先展示问题代码
1 #include<stdio.h> 2 int main(){ 3 int a[3]={0,1,2}; 4 for(int i=0;i<=3;i++){ 5 a[i]=0; 6 printf("test"); 7 } 8 return 0; 9 }
诸君很容易看出,第4行for循环内的结束条件设置的显然有问题,数组a长度位3,显然下标只能到2,而循环中却做了一个对所谓a[3]的赋0操作,这就是常说的数组下标越界问题。
看一下,这个问题代码给我们带来了什么样的麻烦。。。
我编译出可执行文件,运行。。。瞬间屏幕被 “test” 字符串填满。。。

仅仅两三秒,就不知做了多少次循环了,计算机运算就是快/xyx/xyx/xyx,展示下页长。。。
显然,由于这个数组越界的问题,我们陷入了死循环,(疯狂ctrl+c,终于停了,如图)

- 思考
那。。。为什么会死循环?
汇编语言里找问题,用gcc拿出中间汇编文件,查看汇编代码(没有采用什么O1/O2的优化编译,所以以下仍含有栈帧的概念)。
1 .file "test.c" 2 .intel_syntax noprefix 3 .section .rodata 4 .LC0: 5 .string "test" 6 .text 7 .globl main 8 .type main, @function 9 main: 10 .LFB0: 11 .cfi_startproc 12 push rbp 13 .cfi_def_cfa_offset 16 14 .cfi_offset 6, -16 15 mov rbp, rsp 16 .cfi_def_cfa_register 6 17 sub rsp, 16 18 mov DWORD PTR [rbp-16], 0 19 mov DWORD PTR [rbp-12], 1 20 mov DWORD PTR [rbp-8], 2 21 mov DWORD PTR [rbp-4], 0 22 jmp .L2 23 .L3: 24 mov eax, DWORD PTR [rbp-4] 25 cdqe 26 mov DWORD PTR [rbp-16+rax*4], 0 27 mov edi, OFFSET FLAT:.LC0 28 mov eax, 0 29 call printf 30 add DWORD PTR [rbp-4], 1 31 .L2: 32 cmp DWORD PTR [rbp-4], 3 33 jle .L3 34 mov eax, 0 35 leave 36 .cfi_def_cfa 7, 8 37 ret 38 .cfi_endproc 39 .LFE0: 40 .size main, .-main 41 .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-16)" 42 .section .note.GNU-stack,"",@progbits
(杂鱼懒得删了,全贴,这是intel风格64位汇编代码,带诸君看)
开始分析,第11行到38行就是main函数了,.cfi_startproc和.cfi_endproc是调用框架指令,用来标记这是一段函数(这里涉及调用框架,诸君有兴趣自行探索)。
12行起到16行:一系列操作据说是函数调用框架的规范步骤,成为前序,就是为了调用main函数和函数返回的正常做的工作,这里不做深究。
我们看17行,将rsp(栈顶寄存器)减了16字节,这就是为下面的数组及变量开辟空间。接着四步就可以看出一次录入了 a[0],a[1],a[2],i 的值。接着jmp无条件跳转到 L2段。
!!!L2里就涉及到for循环的控制了,我们开始接近问题的本源了。cmp 操作数,用来比较 [rbp-4] (我们知道这里放的是变量i) 与3的大小,接着jle(什么jump when less or equal,差不多这样),若结果为小于等于则跳转到L3。
L3内,上来就把我们的i的值取了出来(因为后面依据下标取数组元素要用到),接着cdqe是将32为寄存器拓展为64为寄存器rax。我们就从出问题的时间点来排查,假设这时i的值已为3(即下标已经越界了),可是到了26行时 i 的值又被赋为了0,这一步其实对应 c 文件里for循环中 a[i] = 0; 这一步,但是这里由于栈帧中内存的分配导致越界后操作到了 i 的值。可想而知,程序的逻辑是for循环到 i==4(i<=3) 时结束,而每次 i一到 3 又被我们重置为 0,for循环又如何停止???所以就死循环了呗。
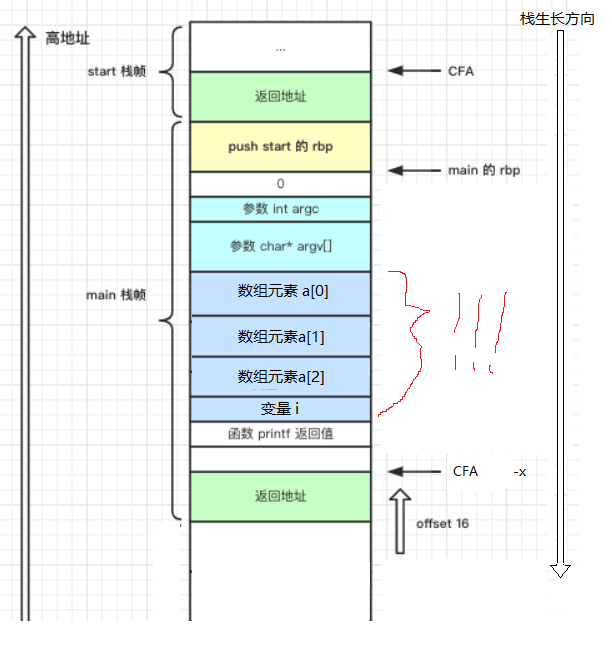
(附一张main栈帧的简图,方便诸君理解)
没错,分析到这里基本就没什么问题了,可是学习不止于此。。。
- 拓展
既然我们知道死循环是由于 i 变量被非法篡改了,导致无法满足 i>3 的截止条件,那么我们可不可以“将错就错”,使 i 的值被非法篡改为满足条件的值(比如4)
即 a[i]=0; ==> a[i]=4; 那么汇编就变为 mov DWORD PTR [rbp-16+rax*4],4 。(虽然没啥意义,但从侧面印证了,的确是 i 的值被篡改导致问题)
- 思考
幸而这里只是一个不那么紧要的变量被改,导致这个小小的程序出错。然而更多时候,这样的问题威胁更大:堆栈溢出!这是缓冲区溢出中危害较大的一种了,原理就是我们设计的程序并没有对接受的数据做长度的检查,导致该程序分配到的内存空间(栈区/缓冲区)放不下这么多内容,从而,这些数据被写入到其他不合理的内存空间,比如上图中返回地址,一旦被修改,下一条被执行的保不齐就是一条shellcode,系统被别人拿了特权;又或者恶意导致计算机宕机。。。(懂得不多,差不多也就了解到写。意在引起诸君对栈溢出的关注,无论是以后走安全,还是走马农,有良好的“意识”)
- 扯闲篇
关于CFI(函数调用框架),还是想扯点东西的,毕竟专门去了解了一堆,但是看网上人家都说现在都不用栈帧这些了,不知诸君想看不。。。