今天是1024程序员节,不得整点活~
虽然不太好教爬1024,但是可以爬点其它的!
比如妹子图,这不都是各位喜欢的~

代码流程
模拟浏览器向服务器发送一个http请求,网站接收到请求后返回数据。
在写爬虫代码的时候一定先要去模拟浏览器访问,因为现在的网站当接收到http请求后会校验当前请求是否是一个浏览器,如果是,允许访问,如果不是,禁止访问!

环境啥的我就不说了,还是老样子~
首先把我们要用的包导进去
import os # 自动创建文件夹 import requests # requests 爬虫包 需要下载 pip install requests from bs4 import BeautifulSoup # 网页选择器 pip install bs4
然后我们就要开始模拟浏览器
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', # 反盗链 'referer': 'https://www.mzitu.com/' }
既然我们要下载,当然要有文件夹去保存对吧,这里就实现自动创建文件夹,不用我们去额外创建。
def get_girls(url): # 自动创建文件夹 if not os.path.exists('./学习资料/'): os.mkdir('./学习资料/')
当然,为了不让你的小秘密被别人看到,咱们这里就把它命名为学习资料吧~

我们现在来发送请求,http协议中 有几种请求方法:
- get 获取数据
- post 数据提交 [账号密码提交]
html = requests.get(url, headers=headers).text
print(html)
对刚刚抓取到的数据进行二次筛选
需要两个参数,想要二次提取的网页 html变量临时保存了。
html解析库 lxml pip install lxml
html解析库可以将html代码转成我们的python对象
soup = BeautifulSoup(html, 'lxml')
通过刚刚分析得出一个结论,一张图片是由img标签保存的,li标签包含一个img标签。如果我们获取了所有的li标签,相当于获取到了所有的img标签,因为一个ul标签包含了所有的li标签,所以获取一个ul就相当于获取到了所有的li标签。
遍历所有的li标签
all_list = soup.find('ul', id='pins').find_all_next('li') for _ in all_list: girl_title = _.get_text() girl_url = _.find('img')['data-original'] print(girl_title, girl_url)
这个时候就可以开始下载了
response = requests.get(girl_url, headers=headers) fileName = girl_title + '.jpg' print('正在保存图片:', girl_title) with open('./学习资料/' + fileName, 'wb') as f: f.write(response.content)
当然,只下载一页的话当然不过瘾,咱们这里就来实现翻页下载,当然,别爬多了,克制一下自己。
代码虽好,但还是要克制一下自己哟~
for page in range(1, 256): url = 'https://www.mzitu.com/page/%s' % page get_girls(url)
你要下载多少页,直接改成多少页就好了。
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码!
还会有大佬解答!
包括本文源代码、对应视频都在这里了 点击蓝色字体即可获取这些福利
欢迎加入,一起讨论 一起学习!
我们看看结果
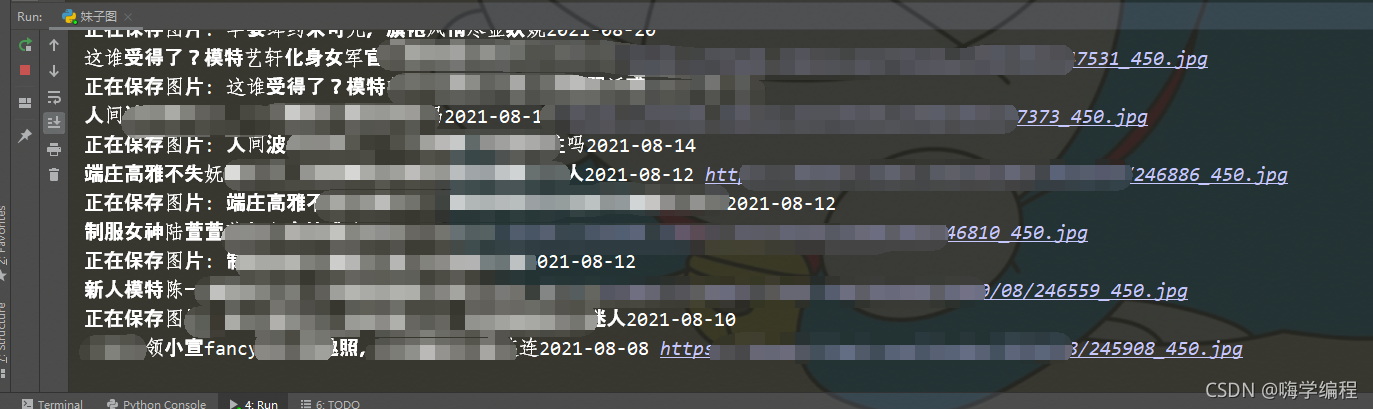

只能打码了,委婉一点。
文件夹我也不打开了,大家等下自己去试试,然后再慢慢打开把哈哈~

兄弟们,如果看完了感觉还过的去的话,记得来个三连,你的三连就是我最大的动力!
有啥问题和建议都可以在评论区一起交流~