题目:
请使用Hive SQL实现下面的题目。
下面是一张表名为user_buy_log的表,有三个字段,user(用户),grp(分组编号),time(购物时间)。
需要将用户按照grp分组,对time进行升序排序,
如果用户间购物时间间隔小于5分钟,则认为是一个小团体,标号为1;
如果时间间隔大于5分,标号开始累加1。
|
user |
grp |
time |
|
num15 |
B |
2019-01-06 13:44:20.0 |
|
num17 |
B |
2019-01-06 13:47:24.0 |
|
num10 |
A |
2019-01-09 15:45:50.0 |
|
num18 |
B |
2019-01-06 13:47:49.0 |
|
num16 |
B |
2019-01-06 13:46:40.0 |
|
num3 |
A |
2019-01-09 11:21:12.0 |
|
num4 |
A |
2019-01-09 11:24:42.0 |
|
num1 |
A |
2019-01-09 09:16:08.0 |
|
num12 |
B |
2019-01-06 13:43:32.0 |
|
num13 |
B |
2019-01-06 13:43:44.0 |
|
num2 |
A |
2019-01-09 09:17:11.0 |
|
num7 |
A |
2019-01-09 15:42:28.0 |
|
num11 |
A |
2019-01-09 15:46:05.0 |
|
num5 |
A |
2019-01-09 11:24:53.0 |
|
num9 |
A |
2019-01-09 15:45:32.0 |
|
num8 |
A |
2019-01-09 15:43:02.0 |
|
num6 |
A |
2019-01-09 11:25:04.0 |
|
num14 |
B |
2019-01-06 13:44:06.0 |
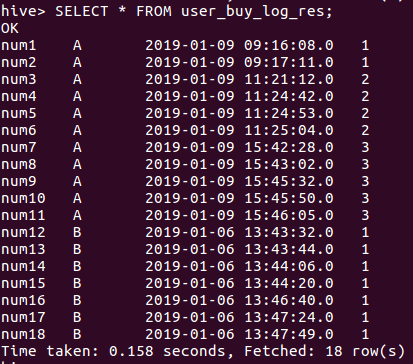
最终输出结果表名:user_buy_log_res,结果如下:
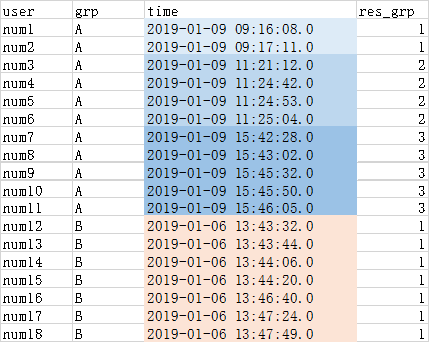
结果解析:
由于num1,num2时间间隔小于5分钟,而且他们是组A的最开始的分组,因此组号(res_grp)为1。
由于num3与num2的时间间隔超过5分钟,因此num3的组号(res_grp)开始累加,因此(res_grp)为2。
Num7跟num6的间隔超过5分钟,num7组号(res_grp)开始再次累加,因此(res_grp)为3。
num12是属于新的分组B,因此其(res_grp)重新从1开始编号,因为后续用户的购物时间间隔都小于5分钟,因此编号没有再累加。
解决办法:
set hive.support.sql11.reserved.keywords=false;
create database tab
use tab
create table user_buy_log (user string, grp string,time string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
STORED AS TEXTFILE;
load data local inpath '/home/hadoop/Desktop/user_buy_log.txt' into table user_buy_log;
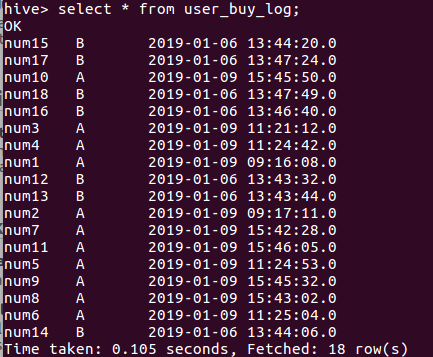
CREATE TABLE user_buy_log_1 AS
SELECT user,grp,time,
CAST(( UNIX_TIMESTAMP(time)-UNIX_TIMESTAMP(lag(time) over(PARTITION BY grp ORDER BY time ASC)))/60 AS INT) period,
row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log;
SELECT * FROM user_buy_log_1;
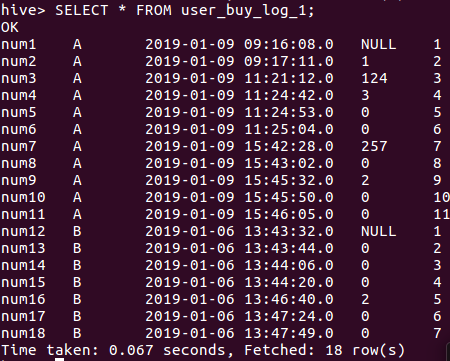
CREATE TABLE user_buy_log_2 AS
SELECT user,grp,time, period , row_num,CASE
WHEN period > 5 THEN 2
WHEN period is null THEN 1
ELSE NULL
END
AS res_grp
FROM user_buy_log_1;
SELECT * FROM user_buy_log_2;
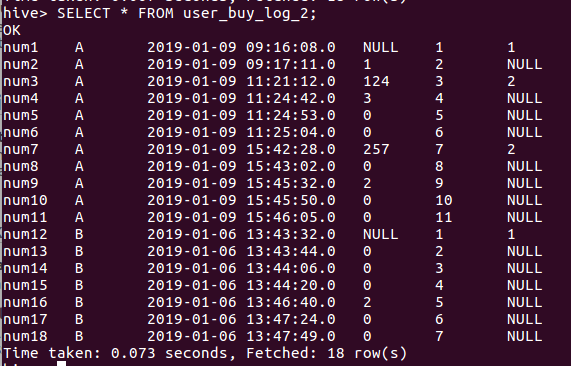
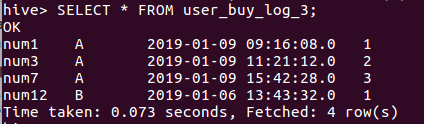
CREATE TABLE user_buy_log_3 AS
SELECT user,grp,time,row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log_2
WHERE res_grp is not null;
SELECT * FROM user_buy_log_3;
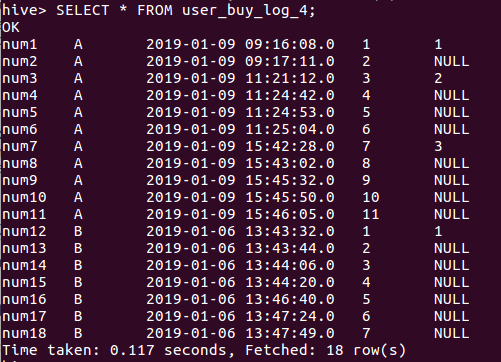
CREATE TABLE user_buy_log_4 AS
SELECT t2.user,t2.grp,t2.time,t2.row_num,t3.row_num AS res_grp
FROM user_buy_log_2 t2
LEFT JOIN user_buy_log_3 t3
ON t2.user = t3.user;
SELECT * FROM user_buy_log_4;
CREATE TABLE user_buy_log_res AS
SELECT user,grp,time,
MAX(res_grp) over(PARTITION BY grp ORDER BY time ASC) AS res_grp
FROM user_buy_log_4;
SELECT * FROM user_buy_log_res;
所有代码:
set hive.support.sql11.reserved.keywords=false; create database tab use tab create table user_buy_log (user string, grp string,time string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE; load data local inpath '/home/hadoop/Desktop/user_buy_log.txt' into table user_buy_log; CREATE TABLE user_buy_log_1 AS SELECT user,grp,time, CAST(( UNIX_TIMESTAMP(time)-UNIX_TIMESTAMP(lag(time) over(PARTITION BY grp ORDER BY time ASC)))/60 AS INT) period, row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num FROM user_buy_log; SELECT * FROM user_buy_log_1; CREATE TABLE user_buy_log_2 AS SELECT user,grp,time, period , row_num,CASE WHEN period > 5 THEN 2 WHEN period is null THEN 1 ELSE NULL END AS res_grp FROM user_buy_log_1; SELECT * FROM user_buy_log_2; CREATE TABLE user_buy_log_3 AS SELECT user,grp,time,row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num FROM user_buy_log_2 WHERE res_grp is not null; SELECT * FROM user_buy_log_3; CREATE TABLE user_buy_log_4 AS SELECT t2.user,t2.grp,t2.time,t2.row_num,t3.row_num AS res_grp FROM user_buy_log_2 t2 LEFT JOIN user_buy_log_3 t3 ON t2.user = t3.user; SELECT * FROM user_buy_log_4; CREATE TABLE user_buy_log_res AS SELECT user,grp,time, MAX(res_grp) over(PARTITION BY grp ORDER BY time ASC) AS res_grp FROM user_buy_log_4; SELECT * FROM user_buy_log_res;
user_buy_log.txt
num15 B 2019-01-06 13:44:20.0 num17 B 2019-01-06 13:47:24.0 num10 A 2019-01-09 15:45:50.0 num18 B 2019-01-06 13:47:49.0 num16 B 2019-01-06 13:46:40.0 num3 A 2019-01-09 11:21:12.0 num4 A 2019-01-09 11:24:42.0 num1 A 2019-01-09 09:16:08.0 num12 B 2019-01-06 13:43:32.0 num13 B 2019-01-06 13:43:44.0 num2 A 2019-01-09 09:17:11.0 num7 A 2019-01-09 15:42:28.0 num11 A 2019-01-09 15:46:05.0 num5 A 2019-01-09 11:24:53.0 num9 A 2019-01-09 15:45:32.0 num8 A 2019-01-09 15:43:02.0 num6 A 2019-01-09 11:25:04.0 num14 B 2019-01-06 13:44:06.0