对象的内存布局
在 HotSpot虚拟机中,对象在内存中存储的布局分为三块区域:对象头,实例数据,和对齐填充。
对象头
对象头包括如下两部分信息:
-
MarkWord:用于存储对象自身的运行时数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。为了在极小空间内存储更多的信息,它被设计成了一个非固定的数据结构,根据对象的状态来复用自己的存储空间,如下:
存储内容 标志位 状态 对象哈希码、分代年龄 01 未锁定 指向锁记录的指针 00 轻量级锁定 指向重量级锁的指针 10 膨胀(重量级锁定) 空 11 GC标记 偏向线程ID偏向时间戳、分代年龄 01 可偏向 -
类型指针:到对象类型数据的指针,即虚拟机通过这个指针来确定这个对象属于哪个类。(有的虚拟机通过句柄池来实现)
-
如果对象是一个数组:对象头还需要有一块空间来记录数组长度,因为对象可以通过类型指针判断Java对象大小,而数组不行。
实例数据
是对象真正的有效数据,也就是代码中所定义的各种类型的字段内容,无论是从父类继承还是子类记录的都必须进行存储。
对齐填充
对齐填充并不是必然存在的,也没有其它的意义,仅仅是占位符的作用,因为HotSpot虚拟机的自动内存管理系统要求对象地址必须是8的整数倍,当实例数据没有对齐时,就需要对齐填充来进行补齐。
对象的访问
当我们使用对象时,我们需要通过虚拟机栈上的reference数据(即worker)来操作堆上的具体对象。
public Worker buildWorker(){
Worker woker = new Woker();
worker.setAge(21);
....
return worker;
}
访问具体对象的方式不同虚拟机有不同的实现,主流的方式有以下两种
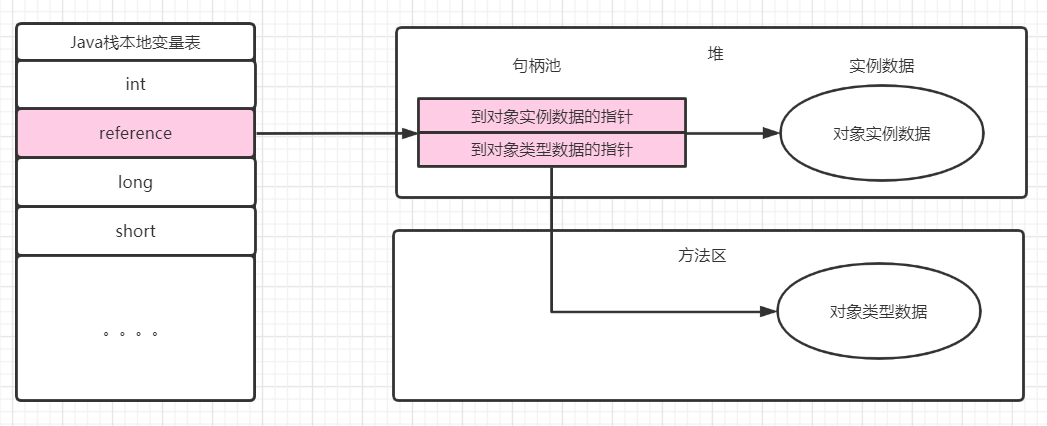
使用句柄池
在Java堆中专门划分处一部分内存作句柄池,reference中存储的是对应对象的句柄地址,而句柄池中包含了对象实例数据和类型数据具体的地址信息,如下图:
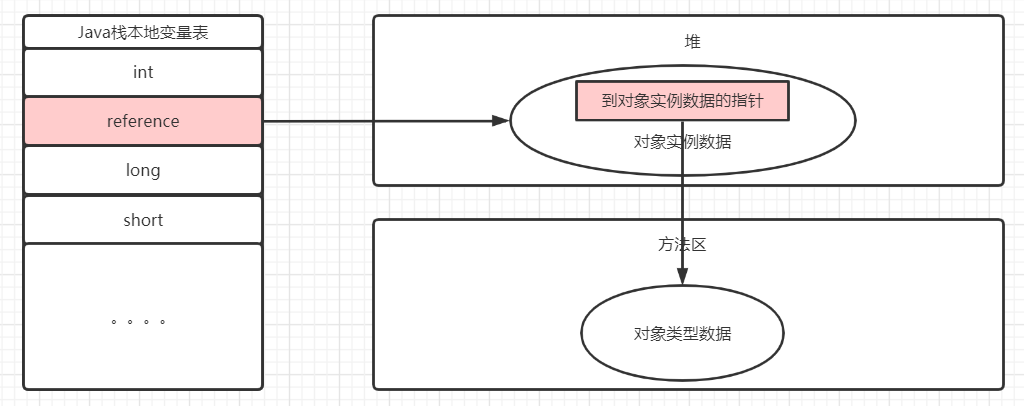
使用直接指针访问
直接指针访问,reference中直接存储对象地址。
两种方式的比较
- 使用句柄池来访问最大的好处就是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集时整体空间位置)时只会改变句柄中的实例数据指针,而reference不需要任何改变。
- 使用直接指针访问最大的好处就是快,节省了一次指针定位的时间开销,由于对象访问在java中非常频繁,积少成多,节省这样的开销效益非常可观。
- 主要虚拟机HotSpot采用直接指针访问,但是许多其他语言和框架使用句柄这种思想也非常常见。