字符编码
将人类的字符编码/转换成计算机能识别的数字
这种转换必须遵循一套固定的标准,该标准无非是
人类字符与数字的对应关系,称之为字符编码表
字符编码转换
unicode------>encode(编码)-------->utf-8
utf-8---------->decode--------->unicode
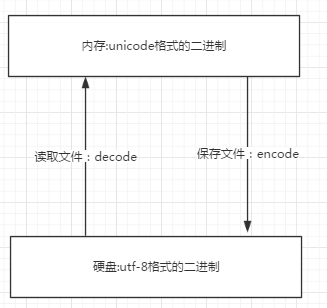
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码:存文件时就已经乱码 或者 存文件时不乱码而读文件时乱码
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
#字符编码需要记住的概念
#01 内存中固定使用unicode编码,我们唯一可以改变的存储到硬盘时使用的编码
#02 要想保证存取文件不乱乱码,应该保证文档当初是以什么编码格式存的,就应该以什么编码格式去读取
#03 python3解释器默认编码是UTF-8
python2解释器默认编码是ASCII
在python2中有两种字符串编码格式
1、unicode:
x=u'上'
2、unicode编码后的结果
x='上' #如果文件头为coding:utf-8,那么"上"被存成utf-8格式的二进制
在python3只有一种字符串编码格式:
1、unicode
x='上’
#04 编码与解码
unicode-------编码encode-------->gbk
unicode<-------解码decode--------gbk
#***
#coding:gbk
x='上’
x.decode('gbk')
#coding:gbk
x=u'上'
x.encode('gbk')
x.encode('utf-8')
#在python3中(*****)
x='上'
x只能进行编码
x.encode('gbk')
总结python2与python3:
(***)
在python2中的字符串类型str都是unicode按照文件头的指定的编码,编码之后的结果
在python2中也可以制造unicode编码的字符串。需要在字符串前加u
(*****)
在python3中的字符串类型str都是unicode编码的
所以python3中的字符串类型可以编码成其他字符编码格式,编码的结果
是bytes类型