Java8中的流操作-基本使用&性能测试
https://note.youdao.com/ynoteshare1/index.html?id=906cb094935371d79de5940ad37a295b&type=note
Java8中的流操作-基本使用&性能测试
本文公众号来源:我没有三颗心脏
作者:我没有三颗心脏
一、流(Stream)简介
流是 Java8 中 API 的新成员,它允许你以声明式的方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。这有点儿像是我们操作数据库一样,例如我想要查询出热量较低的菜品名字我就可以像下面这样:
SELECT name FROM dishes WHERE calorie < 400;
您看,我们并没有对菜品的什么属性进行筛选(比如像之前使用迭代器一样每个做判断),我们只是表达了我们想要什么。那么为什么到了 Java 的集合中,这样做就不行了呢?
另外一点,如果我们想要处理大量的数据又该怎么办?是否是考虑使用多线程进行并发处理呢?如果是,那么可能编写的关于并发的代码比使用迭代器本身更加的复杂,而且调试起来也会变得麻烦。
基于以上的几点考虑,Java 设计者在 Java 8 版本中,引入了流的概念,来帮助您节约时间!并且有了 lambda 的参与,流操作的使用将更加顺畅!
特点一:内部迭代
就现在来说,您可以把它简单的当成一种高级的迭代器(Iterator),或者是高级的 for 循环,区别在于,前面两者都是属于外部迭代,而流采用内部迭代。
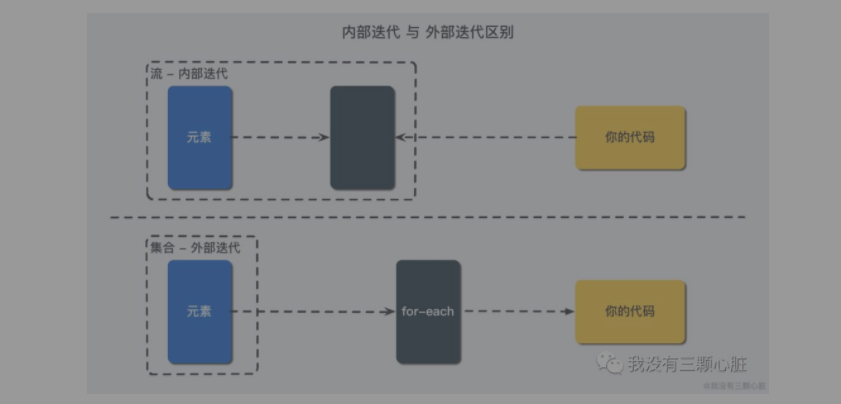
上图简要说明了内部迭代与外部迭代的差异,我们再举一个生活中实际的例子(引自《Java 8 实战》),比如您想让您两岁的孩子索菲亚把她的玩具都收到盒子里面去,你们之间可能会产生如下的对话:
- 你:“索菲亚,我们把玩具收起来吧,地上还有玩具吗?”
- 索菲亚:“有,球。”
- 你:“好,把球放进盒子里面吧,还有吗?”
- 索菲亚:“有,那是我的娃娃。”
- 你:“好,把娃娃也放进去吧,还有吗?”
- 索菲亚:“有,有我的书。”
- 你:“好,把书也放进去,还有吗?”
- 索菲亚:“没有了。”
- 你:“好,我们收好啦。”
这正是你每天都要对 Java 集合做的事情。你外部迭代了一个集合,显式地取出每个项目再加以处理,但是如果你只是跟索菲亚说:“把地上所有玩具都放进盒子里”,那么索菲亚就可以选择一手拿娃娃一手拿球,或是选择先拿离盒子最近的那个东西,再拿其他的东西。
采用内部迭代,项目可以透明地并行处理,或者用优化的顺序进行处理,要是使用 Java 过去的外部迭代方法,这些优化都是很困难的。
这或许有点鸡蛋里挑骨头,但这差不多就是 Java 8 引入流的原因了——Streams 库的内部迭代可以自动选择一种是和你硬件的数据表示和并行实现。
特点二:只能遍历一次
请注意,和迭代器一样,流只能遍历一次。当流遍历完之后,我们就说这个流已经被消费掉了,你可以从原始数据那里重新获得一条新的流,但是却不允许消费已消费掉的流。例如下面代码就会抛出一个异常,说流已被消费掉了:
List<String> title = Arrays.asList("Wmyskxz", "Is", "Learning", "Java8", "In", "Action");
Stream<String> s = title.stream();
s.forEach(System.out::println);
s.forEach(System.out::println);
// 运行上面程序会报以下错误
/*
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(AbstractPipeline.java:279)
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
at Test1.main(Tester.java:17)
*/
特点三:方便的并行处理
Java 8 中不仅提供了方便的一些流操作(比如过滤、排序之类的),更重要的是对于并行处理有很好的支持,只需要加上 .parallel() 就行了!例如我们使用下面程序来说明一下多线程流操作的方便和快捷,并且与单线程做了一下对比:
public class StreamParallelDemo {
/** 总数 */
private static int total = 100_000_000;
public static void main(String[] args) {
System.out.println(String.format("本计算机的核数:%d", Runtime.getRuntime().availableProcessors()));
// 产生1000w个随机数(1 ~ 100),组成列表
Random random = new Random();
List<Integer> list = new ArrayList<>(total);
for (int i = 0; i < total; i++) {
list.add(random.nextInt(100));
}
long prevTime = getCurrentTime();
list.stream().reduce((a, b) -> a + b).ifPresent(System.out::println);
System.out.println(String.format("单线程计算耗时:%d", getCurrentTime() - prevTime));
prevTime = getCurrentTime();
// 只需要加上 .parallel() 就行了
list.stream().parallel().reduce((a, b) -> a + b).ifPresent(System.out::println);
System.out.println(String.format("多线程计算耗时:%d", getCurrentTime() - prevTime));
}
private static long getCurrentTime() {
return System.currentTimeMillis();
}
}
以上程序分别使用了单线程流和多线程流计算了一千万个随机数的和,输出如下:
本计算机的核数:8
655028378
单线程计算耗时:4159
655028378
多线程计算耗时:540
并行流的内部使用了默认的 ForkJoinPool 分支/合并框架,它的默认线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors() 得到的(当然我们也可以全局设置这个值)。我们也不再去过度的操心加锁线程安全等一系列问题。
二、流基本操作
至少我们从上面了解到了,流操作似乎是一种很强大的工具,能够帮助我们节约我们时间的同时让我们程序可读性更高,下面我们就具体的来了解一下 Java 8 带来的新 API Stream,能给我们带来哪些操作。
1、筛选和切片
filter
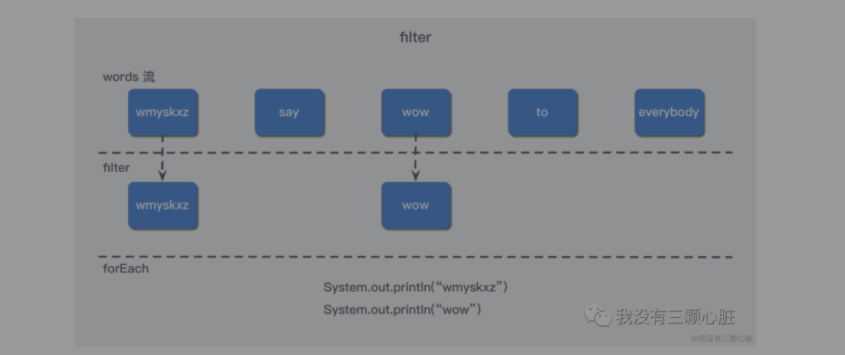
Stream 接口支持 filter 方法,该操作会接受一个返回 boolean 的函数作为参数,并返回一个包含所有符合该条件的流。例如,你可以这样选出所有以字母 w 开头的单词并打印:
List<String> words = Arrays.asList("wmyskxz", "say", "wow", "to", "everybody");
words.stream()
.filter(word -> word.startsWith("w"))
.forEach(System.out::println);
// ==============输出:===============
// wmyskxz
// wow
这个过程类似下图:
当然如果您不是想要输出而是想要返回一个集合,那么可以使用 .collect(toList()),就像下面这样:
List<String> words = Arrays.asList("wmyskxz", "say", "wow", "to", "everybody");
List<String> filteredWords = words.stream()
.filter(word -> word.startsWith("w"))
.collect(Collectors.toList());
distinct
流还支持一个叫做 distinct 的方法,它会返回一个元素各异(根据流所生成的元素的 hashCode 和 equals 方法实现)的流。例如,以下代码会筛选出列表中所有的偶数,并确保没有重复:
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 2, 1, 3, 4);
numbers.stream()
.filter(integer -> integer % 2 == 0)
.distinct()
.forEach(System.out::println);
// ==============输出:===============
// 2
// 4
limit
流支持 limit(n) 方法,该方法会返回一个不超过给定长度的流,所需长度需要作为参数传递给 limit。如果流是有序的,则最多会返回前 n 个元素。比如,你可以建立一个 List,选出前 3 个元素:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
numbers.stream()
.filter(integer -> integer % 2 == 0)
.limit(3)
.forEach(System.out::println);
// ==============输出:===============
// 2
// 4
// 6
请注意虽然上述的集合是有序的,但 limit 本身并不会做任何排序的操作。
skip
流还支持 skip(n) 方法,返回一个扔掉了前 n 个元素的流。如果流中元素不足 n 个,则返回一个空流。请注意 litmit 和 skip 是互补的!例如,下面这段程序,选出了所有的偶数并跳过了前两个输出:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
numbers.stream()
.filter(integer -> integer % 2 == 0)
.skip(2)
.forEach(System.out::println);
// ==============输出:===============
// 6
// 8
2、映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在 SQL 里,你可以从表中选择一列,Stream API 也通过 map 和 flatMap 方法提供了类似的工具。
map
流支持 map 方法,他会接受一个函数作为参数。这个函数会被应用到每个元素身上吗,并将其映射成一个新的函数。例如,下面的代码把方法引用 Words::getContent 传给了 map 方法,来提取流中 Words 的具体内容:
public static void main(String[] args) {
List<Words> numbers = Arrays.asList(new Words("我没有三颗心脏"),
new Words("公众号"), new Words("wmyskxz"));
numbers.stream()
.map(Words::getContent)
.forEach(System.out::println);
}
@Data
@AllArgsConstructor
private static class Words {
private String content;
}
// ==============输出:===============
// 我没有三颗心脏
// 公众号
// wmyskxz
但是如果你现在只想要找出每个 Words 具体内容的长度又该怎么办呢?我们可以再进行一次映射:
public static void main(String[] args) {
List<Words> numbers = Arrays.asList(new Words("我没有三颗心脏"),
new Words("公众号"), new Words("wmyskxz"));
numbers.stream()
.map(Words::getWords)
.map(String::length)
.forEach(System.out::println);
}
@Data
@AllArgsConstructor
private static class Words {
private String words;
}
// ==============输出:===============
// 7
// 3
// 7
flatMap:流的扁平化
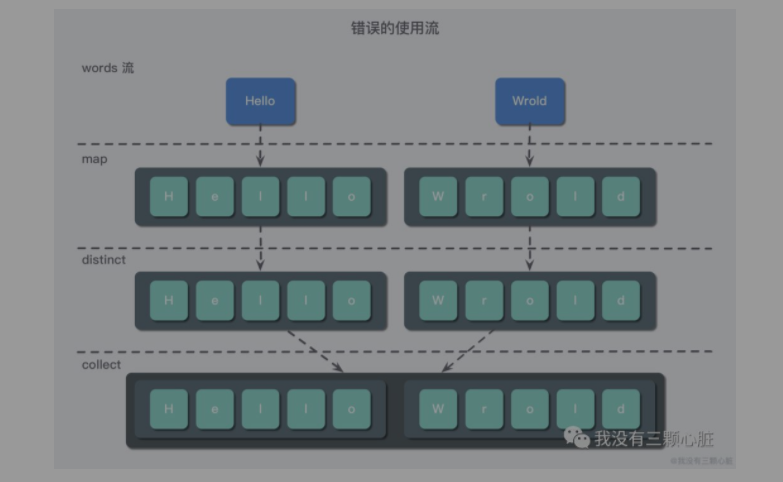
你已经看到我们是如何使用 map 方法来返回每个 Words 的具体长度了,现在让我们来扩展一下:对于一个 Words 集合,我需要知道这个集合里一共有多少个不相同的字符呢?例如,给定单词列表为:["Hello", "World"],则需要返回的列表是:["H", "e", "l", "o", "W", "r", "d"]。
您可能会觉得简单,而后写下下列错误的第一版本:
List<String> words = Arrays.asList("Hello", "World");
words.stream()
.map(s -> s.split(""))
.distinct()
.collect(Collectors.toList())
.forEach(System.out::println);
// ==============输出:===============
// [Ljava.lang.String;@238e0d81
// [Ljava.lang.String;@31221be2
为什么会这样呢?这个方法的问题在于,传递给 map 方法的 lambda 表达式为每个单词返回了一个 String[],所以经过 map 方法之后返回的流就不是我们预想的 Stream<String>,而是 Stream<String[]>,下图就说明了这个问题:
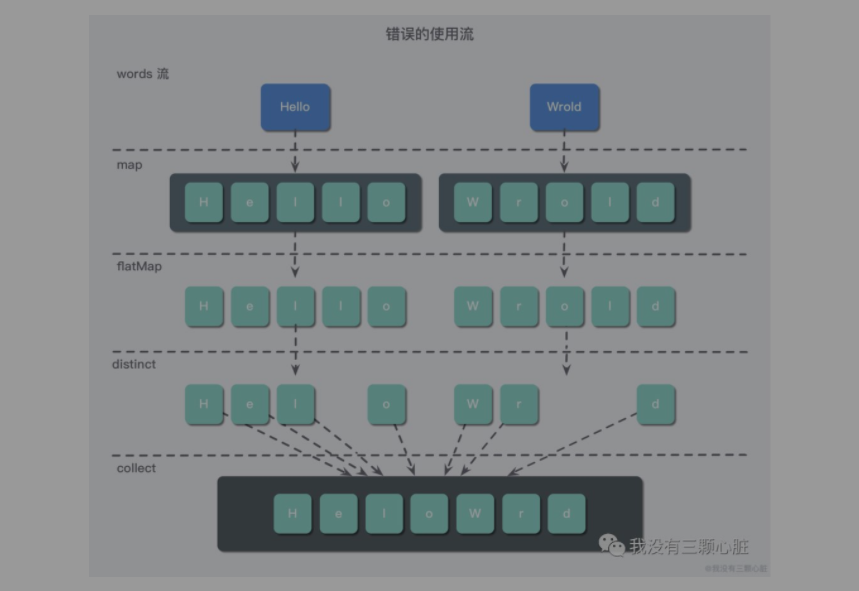
幸好我们可以使用 flatMap 来解决这个问题:
List<String> words = Arrays.asList("Hello", "World");
words.stream()
.map(s -> s.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList())
.forEach(System.out::println);
// ==============输出:===============
// H
// e
// l
// o
// W
// r
// d
使用 flatMap 方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。一言蔽之就是 flatMap 让你一个流中的每个值都转换成另一个六,然后把所有的流连接起来成为一个流,具体过程如下图:
3、查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性,Stream API 通过 allMatch、anyMatch、noneMatch、findFirst 和 findAny 方法提供了这样的工具(其实到这里看名字就会大概能够知道怎么使用了)。
我们简单的举两个例子就好。
比如,你可以用它来看看集合里面是否有偶数:
List<Integer> numbers = Arrays.asList(1, 2, 3);
if (numbers.stream().anyMatch(i -> i % 2 == 0)) {
System.out.println("集合里有偶数!");
}
再比如,你可以用来它来检验是否集合里都为偶数:
List<Integer> numbers = Arrays.asList(2, 2, 4);
if (numbers.stream().allMatch(i -> i % 2 == 0)) {
System.out.println("集合里全是偶数!");
}
再或者,给定一个数字列表,找出第一个平方能被 3 整除的数:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
Optional<Integer> firstSquareDivisibledByThree =
numbers.stream()
.map(x -> x * x)
.filter(x -> x % 3 == 0)
.findFirst();
System.out.println(firstSquareDivisibledByThree.get());
// ==============输出:===============
// 9
Optional 简介:
Optional<T> 类是 java.util.Optional 包里的一个容器类,代表一个值存在或者不存在。在上面的代码中,findFirst() 可能什么元素都找不到,Java 8 的设计人员引入了 Optional<T>,这样就不用返回众所周知容易出问题的 null 了。我们在这里不对 Optional 做细致的讨论。
4、归约:reduce
到目前为止,你见到过的终端操作(下面我们会说到这些操作其实分为中间操作和终端操作)都是返回一个 boolean(allMatch 之类的)、void(forEach)或 Optional 对象(findFirst 等)。你也见到过了使用 collect 来将流中的所有元素合并成一个 List。
接下来我们来接触更加复杂的一些操作,比如 “挑出单词中长度最长的的单词” 或是 “计算所有单词的总长度”。此类查询需要将流中的元素反复结合起来,得到一个值。这样的查询可以被归类为归约操作(将流归约成一个值)。
数组求和
在研究 reduce 之前,我们先来回顾一下我们在之前是如何对一个数字数组进行求和的:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = 0;
for (int x : numbers) {
sum += x;
}
System.out.println(sum);
// ==============输出:===============
// 15
numbers 中的每个元素都用加法运算符反复迭代来得到结果。通过反复使用加法,我们最终把一个数字列表归约成了一个数字。在这段代码中,我们一共使用了两个参数:
- sum:总和变量的初始值,在这里是 0;
- x:用于接受 numbers 中的每一个元素,并与 sum 做加法操作不断迭代;
要是还能把所有的数字相乘,而不用复制粘贴这段代码,岂不是很好?这正是 reduce 操作的用武之地,它对这种重复应用的模式做了抽象。你可以像下面这样对流中所有的元素求和:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
System.out.println(sum);
// ==============输出:===============
// 15
其中 reduce 接受了两个参数:
- 一个初始值,这里是 0;
- 一个是 BinaryOperator 来将两个元素结合起来产生一个新值,这里我们用的是 lambda (a, b) -> a + b;
你也可以很容易改造成所有元素相乘的形式,只需要将另一个 Lambda:(a, b) -> a * b 传递给 reduce 就可以了:
int product = numbers.stream().reduce(0, (a, b) -> a * b);
我们先来深入研究一下 reduce 是如何对一个数字流进行求和的:
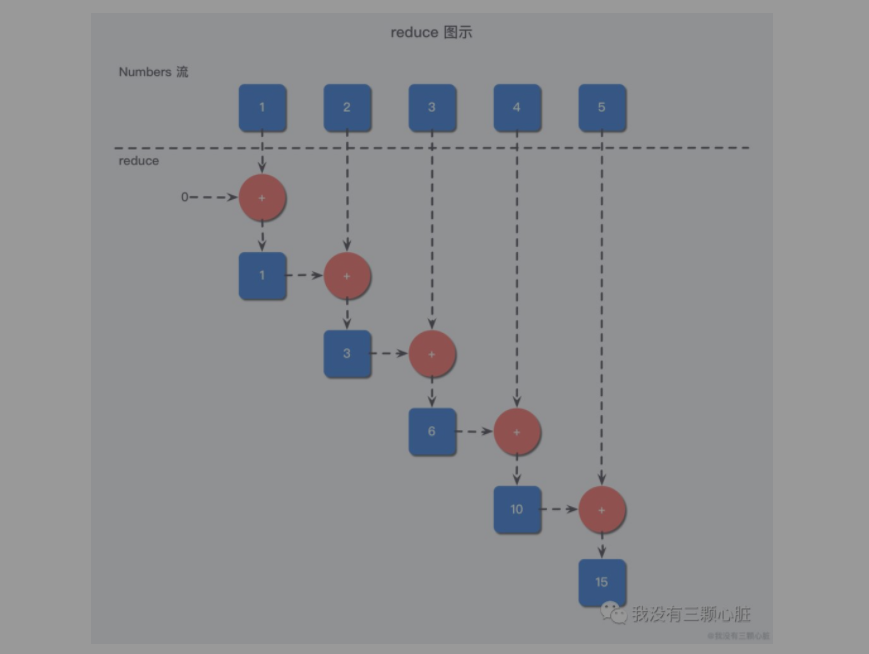
如上图所示一样的,reduce 每一次都把结果返回并与下一次的元素进行操作,比如第一次当遍历到元素 1 时,此时返回初始值 0 + 1 = 1,然后再用此时的返回值 1 与第二个元素进行叠加操作,如此往复,便完成了对数字列表的求和运算。
当然你也可以使用方法引用让这段代码更加简洁:
int sum = numbers.stream().reduce(0, Integer::sum);
无初始值
reduce 还有一个重载的变体,它不接受初始值,但是会返回一个 Optional 对象(考虑到流中没有任何元素的情况):
Optional<Integer> sum = numbers.stream().reduce(Integer::sum);
最大值和最小值
有点类似于上面的操作,我们可以使用下面这样的 reduce 来计算流中的最大值or最小值:
// 最大值
Optional<Integer> max = numbers.stream().reduce(Integer::max);
// 最小值
Optional<Integer> max = numbers.stream().reduce(Integer::min);
5、中间操作和结束操作(终端操作)
Stream API 上的所有操作分为两类:中间操作和结束操作。中间操作只是一种标记,只有结束操作才会触发实际计算。
中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;
结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。为了更好的理解流的中间操作和终端操作,可以通过下面的两段代码来看他们的执行过程:
IntStream.range(1, 10)
.peek(x -> System.out.print(" A" + x))
.limit(3)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
// ==============输出:===============
// A1B1C1
// A2B2C2
// A3B3C3
中间操作是懒惰的,也就是不会对数据做任何操作,直到遇到了结束操作。而结束操作都是比较热情的,他们会回溯之前所有的中间操作。
拿上面的例子来说,当执行到 forEach() 的时候,它会回溯到上一步中间操作,再到上一步中间操作,再上一步..直到第一步,也就是这里的 .peek(x -> System.out.println(" A" + x),然后开始自上而下的依次执行,输出第一行的 A1B1C1,然而第二次执行 forEach() 操作的时候等同,以此类推..
我们再来看第二段代码:
IntStream.range(1, 10)
.peek(x -> System.out.print(" A" + x))
.skip(6)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
// ==============输出:===============
// A1
// A2
// A3
// A4
// A5
// A6
// A7B7C7
// A8B8C8
// A9B9C9
根据上面介绍的规则,同样的当第一次执行 .forEach() 的时候,会回溯到第一个 peek 操作,打印出 A1,然后执行 skip,这个操作的意思就是跳过,也就是相当于 for 循环里面的 continue,所以前六次的 forEach() 操作都只会打印 A。
而第七次开始,skip 失效之后,就会开始分别执行 .peek() 和 forEach() 里面的打印语句了,就会看到输出的是:A7B7C7。
OK,到这里也算是对 Stream API 有了一定的认识,下面我们对中间操作和结束操作做一个总结:

三、Stream 性能测试
引用自:下方参考文档第 4 条。
已经对 Stream API 的用法鼓吹够多了,用起简洁直观,但性能到底怎么样呢?会不会有很高的性能损失?本节我们对 Stream API 的性能一探究竟。
为保证测试结果真实可信,我们将 JVM 运行在 -server 模式下,测试数据在 GB 量级,测试机器采用常见的商用服务器,配置如下:
测试所用代码在这里,测试结果汇总.
测试方法和测试数据
性能测试并不是容易的事,Java性能测试更费劲,因为虚拟机对性能的影响很大,JVM对性能的影响有两方面:
- GC的影响。GC的行为是Java中很不好控制的一块,为增加确定性,我们手动指定使用CMS收集器,并使用10GB固定大小的堆内存。具体到JVM参数就是-XX:+UseConcMarkSweepGC -Xms10G -Xmx10G
- JIT(Just-In-Time)即时编译技术。即时编译技术会将热点代码在JVM运行的过程中编译成本地代码,测试时我们会先对程序预热,触发对测试函数的即时编译。相关的JVM参数是-XX:CompileThreshold=10000。
Stream并行执行时用到ForkJoinPool.commonPool()得到的线程池,为控制并行度我们使用Linux的taskset命令指定JVM可用的核数。
测试数据由程序随机生成。为防止一次测试带来的抖动,测试4次求出平均时间作为运行时间。
实验一 基本类型迭代
测试内容:找出整型数组中的最小值。对比for循环外部迭代和Stream API内部迭代性能。
测试程序IntTest,测试结果如下图: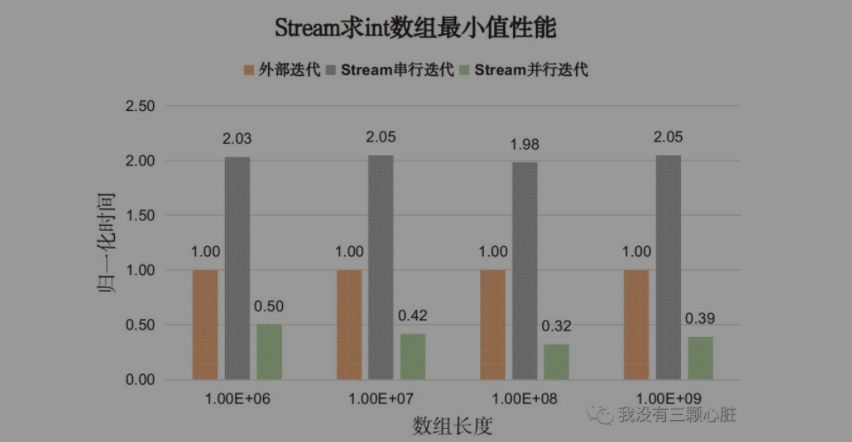
图中展示的是for循环外部迭代耗时为基准的时间比值。分析如下:
对于基本类型Stream串行迭代的性能开销明显高于外部迭代开销(两倍);
Stream并行迭代的性能比串行迭代和外部迭代都好。
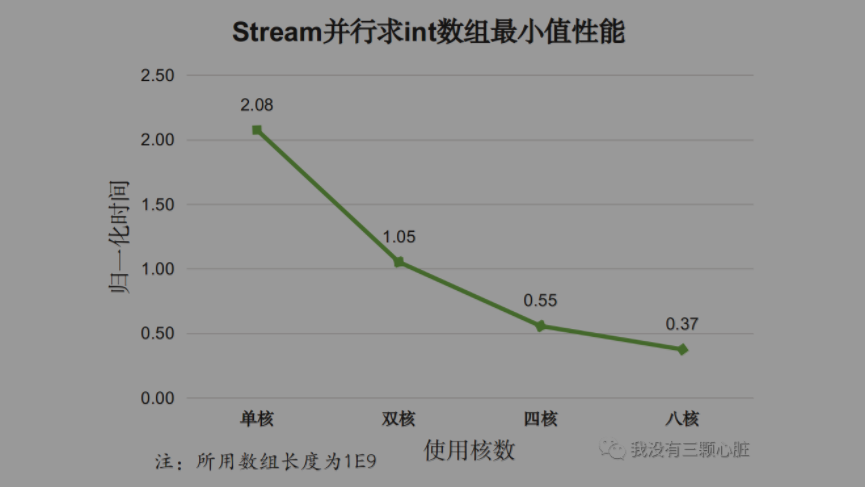
并行迭代性能跟可利用的核数有关,上图中的并行迭代使用了全部 12 个核,为考察使用核数对性能的影响,我们专门测试了不同核数下的Stream并行迭代效果:
分析,对于基本类型:
- 使用Stream并行API在单核情况下性能很差,比Stream串行API的性能还差;
- 随着使用核数的增加,Stream并行效果逐渐变好,比使用for循环外部迭代的性能还好。
以上两个测试说明,对于基本类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验二 对象迭代
再来看对象的迭代效果。
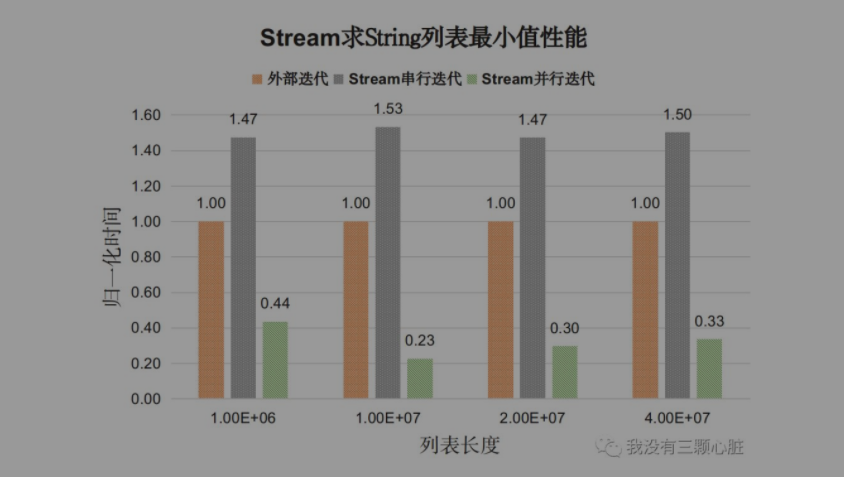
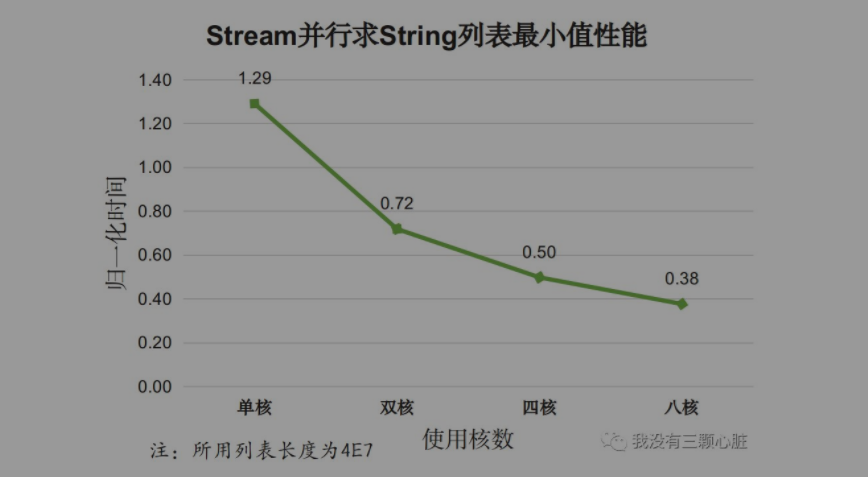
测试内容:找出字符串列表中最小的元素(自然顺序),对比for循环外部迭代和Stream API内部迭代性能。
测试程序StringTest,测试结果如下图:
结果分析如下:
- 对于对象类型Stream串行迭代的性能开销仍然高于外部迭代开销(1.5倍),但差距没有基本类型那么大。
- Stream并行迭代的性能比串行迭代和外部迭代都好。
再来单独考察Stream并行迭代效果
分析,对于对象类型:
- 使用Stream并行API在单核情况下性能比for循环外部迭代差;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个测试说明,对于对象类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验三 复杂对象归约
从实验一、二的结果来看,Stream串行执行的效果都比外部迭代差(很多),是不是说明Stream真的不行了?先别下结论,我们再来考察一下更复杂的操作。
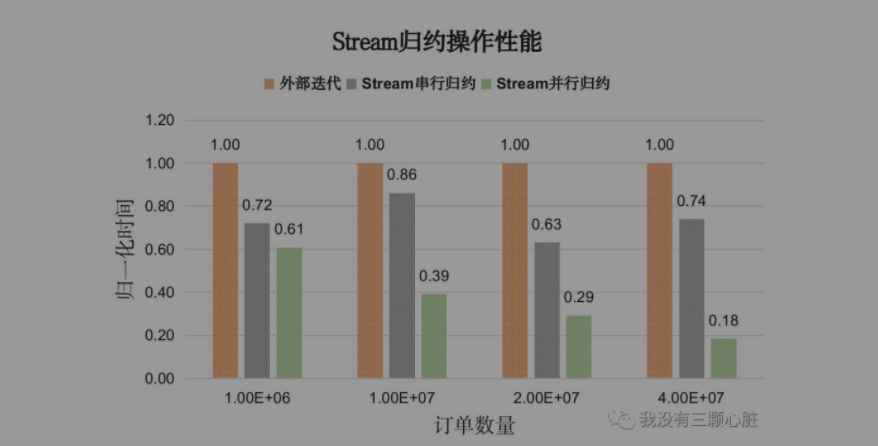
测试内容:给定订单列表,统计每个用户的总交易额。对比使用外部迭代手动实现和Stream API之间的性能。
我们将订单简化为<userName, price, timeStamp>构成的元组,并用Order对象来表示。测试程序ReductionTest,测试结果如下图:
分析,对于复杂的归约操作:
- Stream API的性能普遍好于外部手动迭代,并行Stream效果更佳;
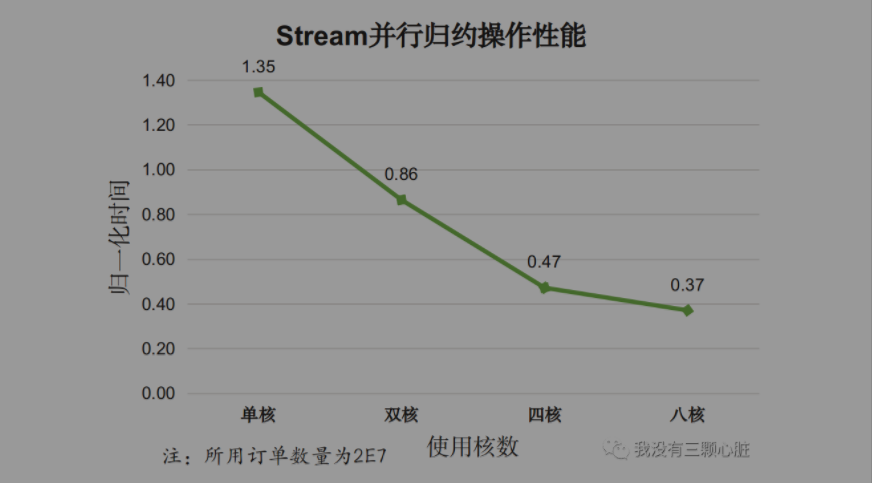
再来考察并行度对并行效果的影响,测试结果如下:
分析,对于复杂的归约操作:
- 使用Stream并行归约在单核情况下性能比串行归约以及手动归约都要差,简单说就是最差的;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个实验说明,对于复杂的归约操作,Stream串行归约效果好于手动归约,在多核情况下,并行归约效果更佳。我们有理由相信,对于其他复杂的操作,Stream API也能表现出相似的性能表现。
结论
上述三个实验的结果可以总结如下:
- 对于简单操作,比如最简单的遍历,Stream串行API性能明显差于显示迭代,但并行的Stream API能够发挥多核特性。
- 对于复杂操作,Stream串行API性能可以和手动实现的效果匹敌,在并行执行时Stream API效果远超手动实现。
所以,如果出于性能考虑,1. 对于简单操作推荐使用外部迭代手动实现,2. 对于复杂操作,推荐使用Stream API, 3. 在多核情况下,推荐使用并行Stream API来发挥多核优势,4.单核情况下不建议使用并行Stream API。
如果出于代码简洁性考虑,使用Stream API能够写出更短的代码。即使是从性能方面说,尽可能的使用Stream API也另外一个优势,那就是只要Java Stream类库做了升级优化,代码不用做任何修改就能享受到升级带来的好处。