1.下载 http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz 最新版
解压: tar -zxvf hadoop-2.7.1.tar.gz
2.配置环境变量
user@EBJ1023.local:/Users/user> vim ~/.bash_profile
export HADOOP_HOME=/usr/local/flume_kafka_stom/hadoop_2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.单机版测试
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,即将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
user@EBJ1023.local:/Users/user> cd /usr/local/flume_kafka_stom/hadoop_2.7.1
mkdir input
cp ./etc/hadoop/*.xml input # 将配置文件作为输入文件.user@EBJ1023.local:/usr/local/flume_kafka_stom/hadoop_2.7.1> ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'cat ./output/*
查看运行结果:


表示单机版的安装成功。
4.伪分布式安装与配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。
Hadoop 的配置文件位于 /usr/local/flume_kafka_stom/hadoop_2.7.1/etc/hadoop 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (vim /usr/local/flume_kafka_stom/hadoop_2.7.1/etc/hadoop/core-site.xml),将当中的
<configuration> </configuration>
修改如下:

<configuration>
<property>
<name>hadoop_2.7.1.tmp.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp/dfs/data</value>
</property>
</configuration>
虽 然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 namenode 的格式化:
bin/hdfs namenode -format
结果如下:
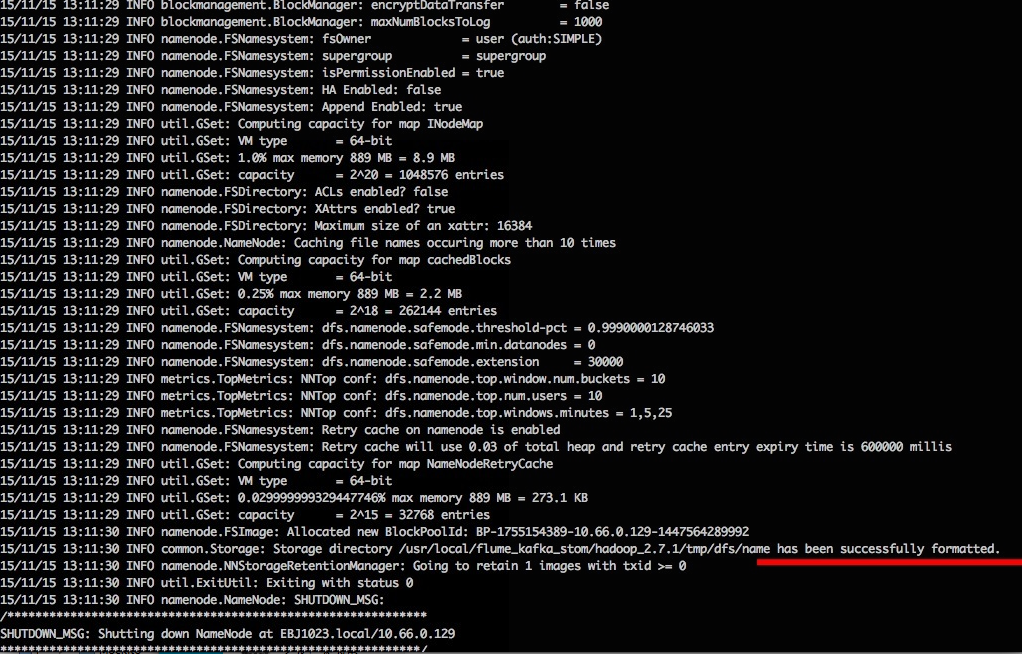
成功的话,会看到 successfully formatted 的提示,且倒数第5行的提示如下,Exitting with status 0 表示成功,若为 Exitting with status 1 则是出错。若出错(不该如此,请仔细检查之前步骤),可试着加上 sudo, 既 sudo bin/hdfs namenode -format 再试试看。
接着开启 NaneNode 和 DataNode 守护进程。
sbin/start-dfs.sh
启动碰到以下问题:连接localhost port 22 Connection 由于本机是mac
解决办法:http://blog.csdn.net/jymn_chen/article/details/39931469

重启正常:

若你使用的是 Hadoop 2.7.1 64位,则此时可能会出现一连串的warn提示,如 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 这个提示,这些warn提示可以忽略,不会影响正常使用。
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: NameNode、DataNode和SecondaryNameNode。(如果SecondaryNameNode没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试;如果 NameNode 或 DataNode 没有启动,请仔细检查之前步骤)。
查看进程
jps

有时 Hadoop 无法正确启动,如 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,注意几点:
- 启动时会提示形如 “DBLab-XMU: starting namenode, logging to /usr/local/flume_kafka_stom/hadoop_2.7.1/logs”,其中 DBLab-XMU 对应你的机器名,但其实启动日志信息是记录在/usr/local/flume_kafka_stom/hadoop_2.7.1/logs 中,所以应该查看这个后缀为 .log 的文件;
- 每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,看下记录的时间就知道了。
- 一般出错的提示在最后面,也就是写着 Fatal、Error 或者 Java Exception 的地方。
- 可以在网上搜索一下出错信息,看能否找到一些相关的解决方法。
成功启动后,可以访问 Web 界面 http://localhost:50070 来查看 Hadoop 的信息。
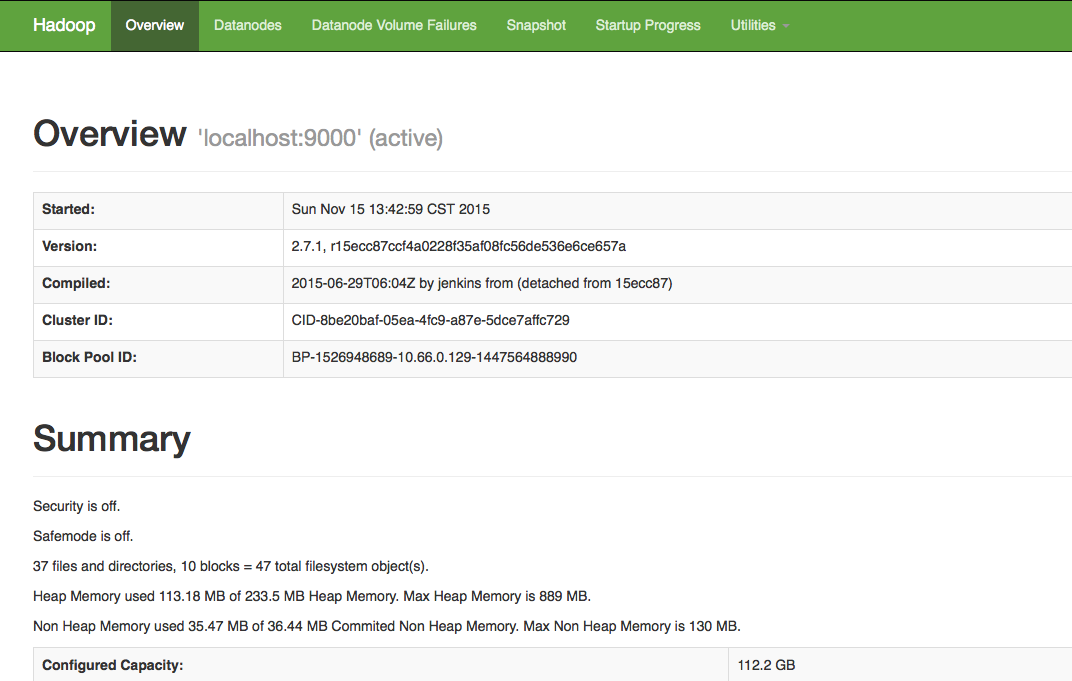
说明安装成功。
参考文章:http://www.powerxing.com/install-hadoop/ 单机和伪分布式hadoop环境搭建
参考文章:http://www.powerxing.com/install-hadoop-cluster/ 集群搭建