5.1 正则表达式介绍
正则表达式:正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。Linux正则表达式一般以行为单位处理。
就是一套处理字符串的规则和方法。以行为单位,对字符串进行处理,通过特殊的符号复制,快速的过滤替换某些字符串。
运维工作中会有大量的信息,比如:访问日志,错误日志,大数据时代更加离不开正则表达式,如何快速的过滤出我们需要的内容,就是要靠正则表达式。
5.2正则表达式的基础
三剑客 awk,sed,grep 三剑客要想能够工作的更加高效,那就离不开正则表达式。
正则表达式简单应用:
| 字符 | 应用 |
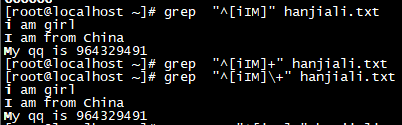
| ^ |
^word搜索以word开头的内容
|
| $ | word$ 搜索以word结尾的。
[root@localhost ~]# grep 9$ hanjiali.txt
phone are 123456 and 123456789
|
| ^$ |
表示空行,不是空格
|
|
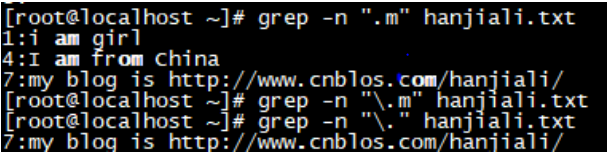
. |
代表且只能代表任意一个字符(除空行)
|
|
转义字符,让有特殊含义的字符脱掉马甲,现出原形,如.只表示小数点将“.”转译之后,它也不会代表任何字符,只是一个点。
|
|
| * | 重复之前的字符或文本0个(会输出全文)或多个,之前的文本或字符连续0次或多次 |
| .* | 任意多个字符
1, 匹配任意字符 2, 匹配以任意字符开头的 3, 匹配以任意字符结束的 |
| ^.* |
以任意多个字符串开头,.*尽可能多,有多少算多少,贪婪性
|
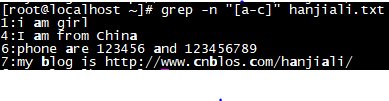
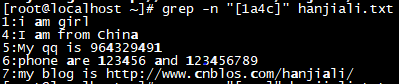
| [abc][0-9][.,/] |
匹配字符集合内的任意一个字符a或b或c:[a-z]匹配所有小写字母;表示一个整体,内藏无限可能;[abc]找a或b或c可以写成[a-c]
|
|
[^abc] |
匹配不包含^后的任意字符a或b或c,是对[abc]的取反,且与^含义不同
|






5.3 扩展正则表达式
| 特殊字符 | 含义 |
| + |
重复前一个字符一次或一次以上,前一个字符连续一个或多个,把连续的文本/字符取出.
|
| ? |
重复前面一个字符0次或1次(.是有且只有1个)
|
| 管道符 | 表示或者同时过滤多个字符
|
| ()
|
分组过滤被括起来的东西表示一个整体(一个字符),后向引 |