当拿到一份数据的时候,首先会怎么做?----描述性统计学,概率推断统计。
描述性统计学
数值数据:计算
分类数据:不能进行计算,例如,男1 女0 代表一个类别
数值数据和分类数据可以进行互相转换
一般描述统计的方式方法:
1.分类数据的描述性统计:单纯计数就可以
2.数据描述统计:
3.统计度量:平均数--数据分布比较均匀的情况下进行,中位数,众数,分位数(4分位、10分位、百分位)
4.图形:
5.权重预估(分位数)
6.数据分布(波动情况,标准差,方差)
7.数据标准化:

在实际用用的时候,有很多情况量纲不一致(即数据单位不一样)导致差异很大无法进行比较
用数据标准化将数据进行一定范围的压缩,得到的结果与数据业务意义无关,纯粹是数据上的波动达到可进行对比。
xi:数据的具体值
u:平均值
σ:标准差
标准化之后一般都是在0上下直接按波动的数字,就可以反应原始数据的典型特征进行分析。
实例演示:时间趋势下订单的变化
单纯的时间只是一种属性,隐含的一种关系。很多销量是跟时间有关系,但是时间的背后是根据用户行为或者一系列因素相关。而不是单纯连续日期几号的简单关系。所以将案例数据需要进行初步整理(坦诚讲~这个细节是比较吸引我的,因为在此之前一直是像上面所说,对日期进行简单连续日期进行趋势分析,得到的结果的确不尽人意)添加周数和星期,将其转化成日历形式进行观察。

显然,标准化之后的趋势显得更加明显清晰了,将趋势扩张到肉眼辨识度提高的形态。
在后期处理的时候,建议用标准化的数据进行预估,因为标准化后已经将正负收敛到0的附近,并且可以方便增加其他关系参加预估。

切比雪夫定理,可以帮助在知道标准差和平均数的情况下,基本就知道数据的分布情况。
另一种作用则通常用于异常值的检测。
在数据越多的情况下,数据越收敛,推算的能力就会越精准。
描述统计的可视化:
1.箱线图:描述一组数据的分布,同时反应分位数
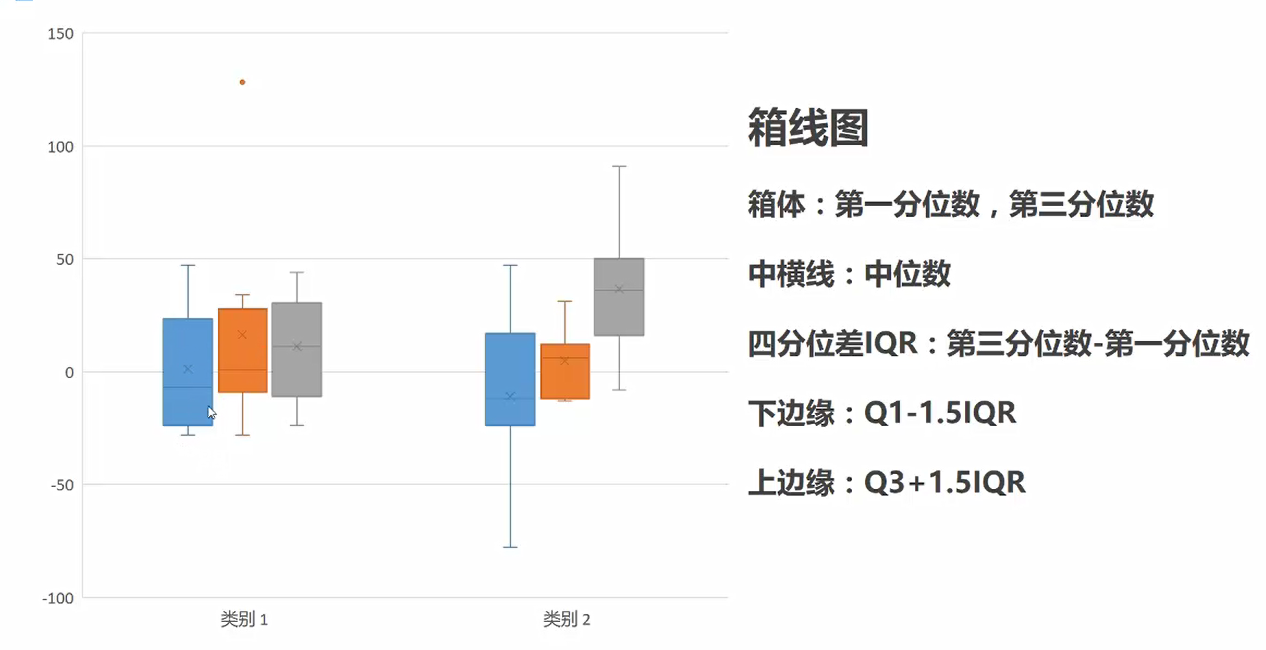
用2016版本以上的Excel可以直接利用数据作图,如低版本的则需要利用辅助线来进行(之前可视化内容的标靶图方法)绘制。
箱线图相对比其他柱形图更有对数据的分析解读性。
操作举例:
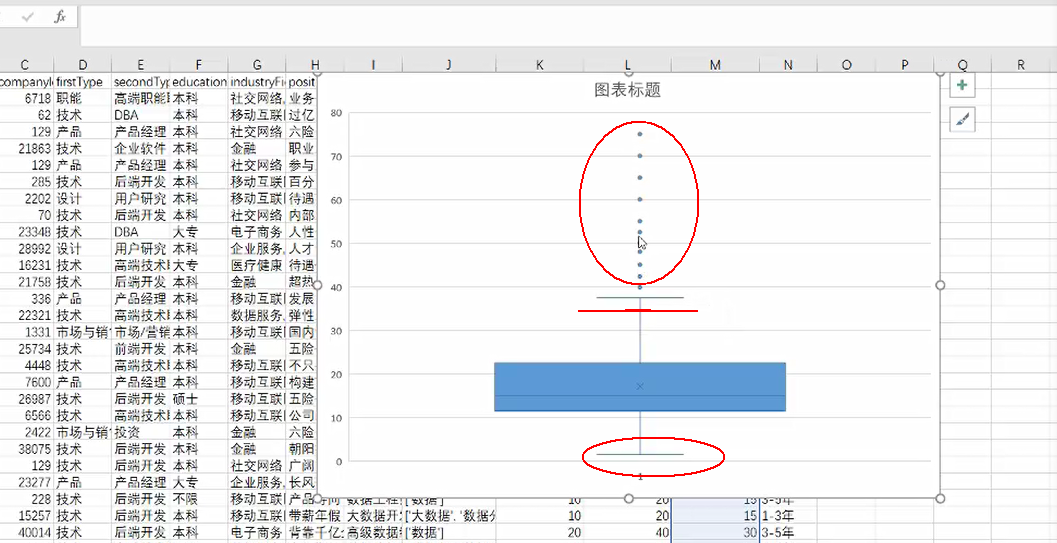
上下边缘线外部分散的点,可视分析情况视为异常值处理,如果想要分析的结果更精准,可视情况将这部分异常值数据剔除。

可添加类别进行细致分析。
2.直方图:特殊的柱形图,把条形图下面的类别换成数据的柱形图。
直方图一般的是等距划分,每一个等距的距离不能重复。
直方图的形状有以下几种:
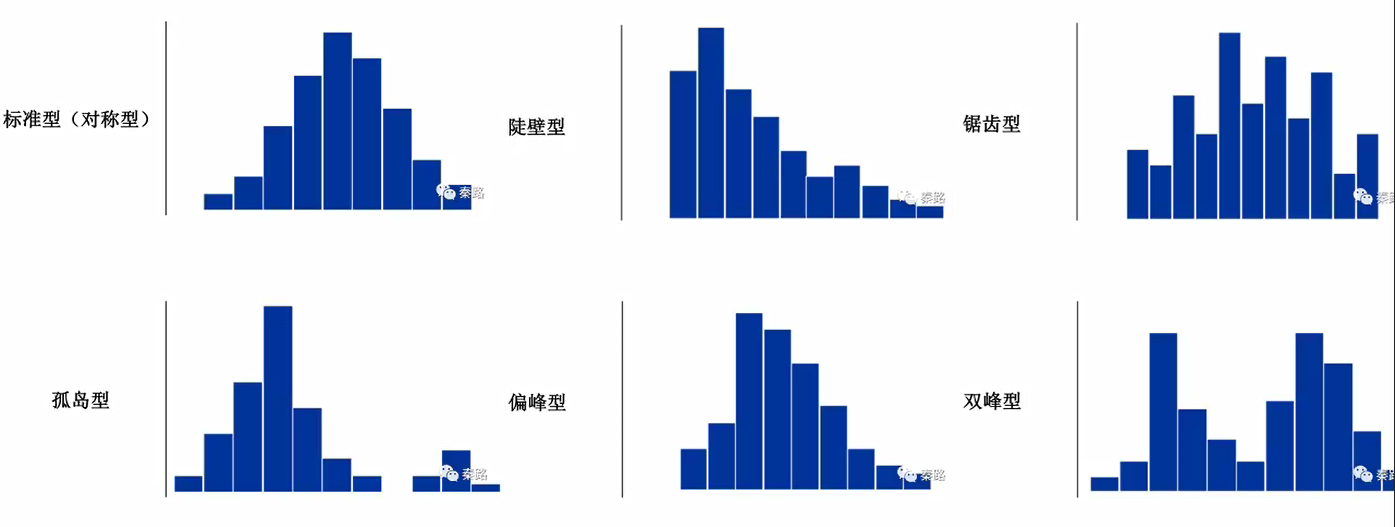
标准型:分布均匀较理想
陡壁型:比较容易出现在收费领域
锯齿型:说明数据不够稳定
孤岛型:要研究分析孤岛产生的原因
偏峰型:销售数据一般会产生偏锋,一般会出现长尾(或左或右)
双峰型:两者数据混合一般会形成双峰
由直方图引出一个统计学指标-
-偏度
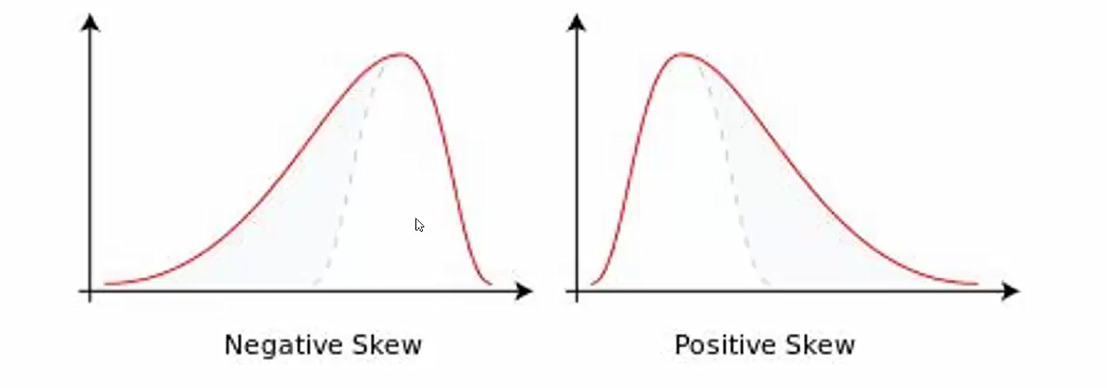
---正太分布
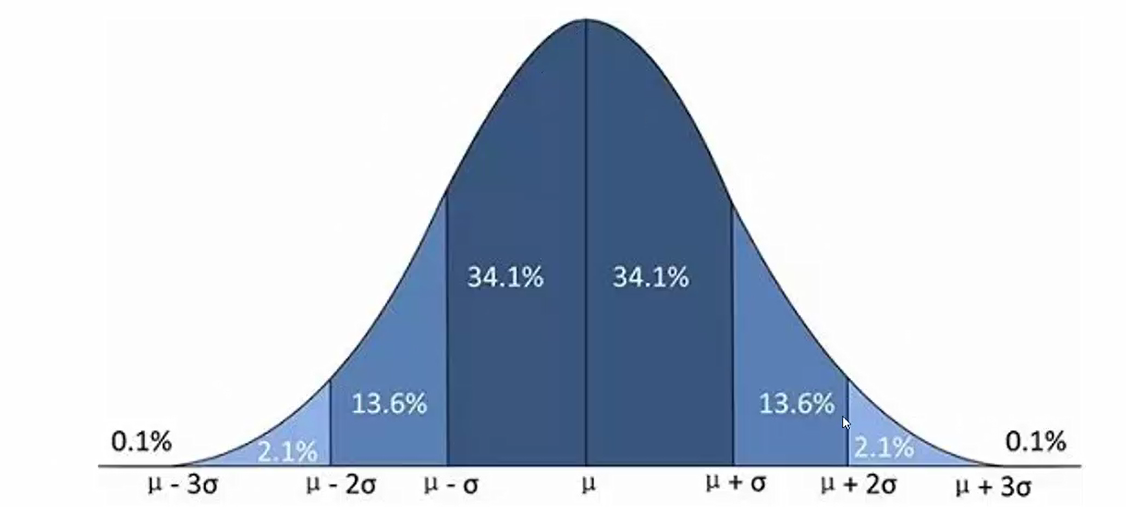
正太分布的特殊应用:

描述性统计的计算值,可通过Excel里面的数据--数据分析---描述性统计直接通过界面勾选需要内容进行计算。
概率推断统计
推断统计,描述一件事情发生的可能性
例如:抛硬币的游戏
事件:正面、反面
概率:50%


在B发生的概率下,A发生的概率是多少
当A与B之间无关联的时候,则P(A|B)=P(A)
条件概率的关键点
贝叶斯定理

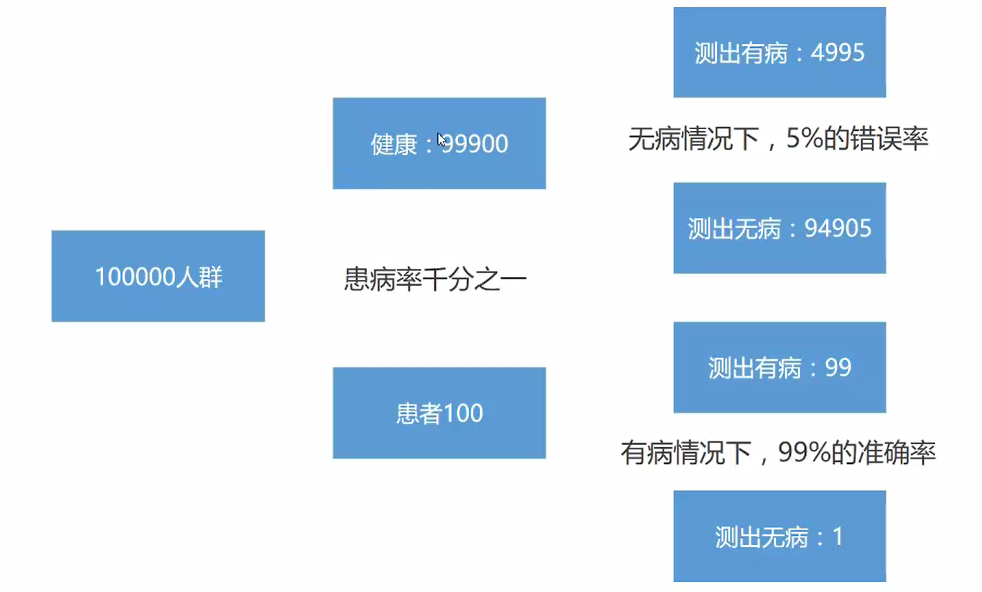
看到题目的时候与最后分析的结果相差巨大的原因是因为上题目中,有多重诱因所导致。
事件发生会有很多原因,我们单纯只知道结果的情况下去反推原因是不太好的。
贝叶斯公式:

P(A1):真实患者的概率
P(A2):实际为健康人群的概率
P(B):代表试纸查出患者的概率
P(B|A1):为真实患者条件下试纸查出患者的概率,即99%
P(B|A2):为健康人群的条件下试纸查出患者的概率,即5%
P(A1)为真实患者的概率0.1%,P(A2)为健康率99.9%
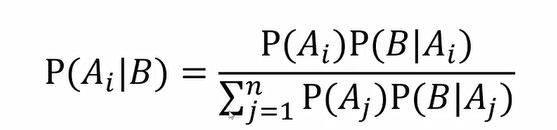
i:为特定场景下
贝叶斯特点:知道结果A已经发生了,想要推导出各种原因发生的可能性有多大。(结果----->发生因素的概率)
对于贝叶斯多倾向用于机器算法。网络上也有很多关于贝叶斯的解释可供参考学习。
概率分布
离散分布
连续变量分布
1.二项分布:
是一种离散型的概率分布。二项代表他有两种可能的结果,把一种称为成功,另外一种称为失败。
每次成功和失败的概率都是相同的,每次实验相互独立(抛硬币是一个典型的二项分布)
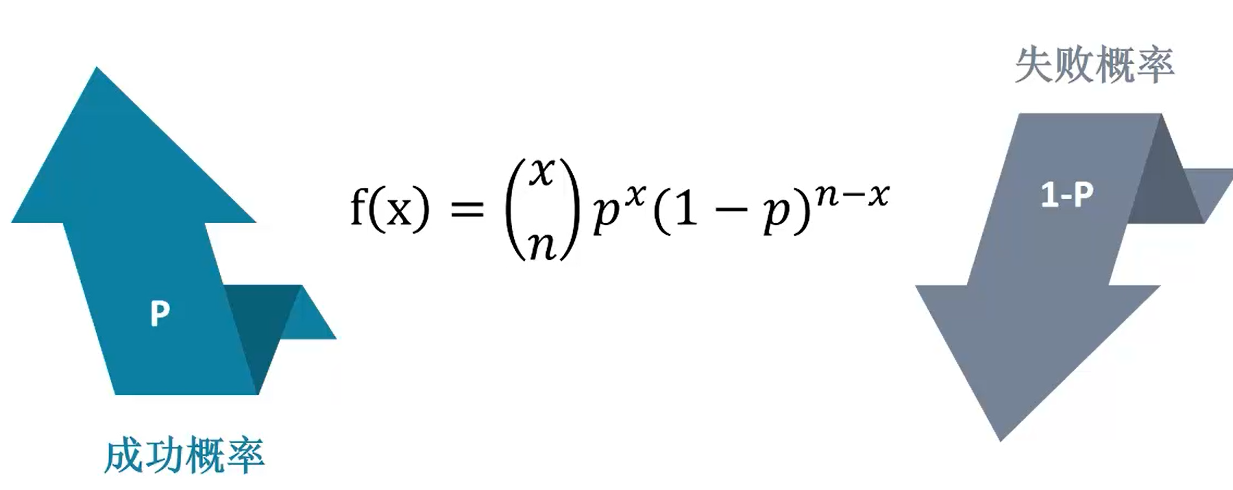
Excel计算概率示例:
概率密度=BINOM.DIST(3,10,0,1,FALSE)
抽3次以上,限制10次,中间概率是10%(示例需求详见见课程)
2.泊松分布:
主要用于预估某事件在特定的事件或者空间中发生的次数。比如一天内中奖的个数,一个月内机器损坏的次数等。
在任意一个单位区间、时间内发生的概率是相同的(知道平均发生的概率)。
每次事件相互独立
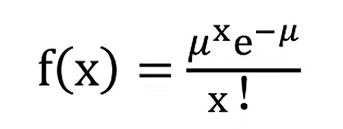
x:想要知道具体发生的概率值
μ:平均概率值平均期望值
e:自然对数、常数
Excel计算概率示例:
=POISSON.DIST(x事件出现的次数,Mean期望值,逻辑值)
需求:想要知道在之前平均几天中奖5次(前几天每天中奖5次),下一时间段中奖概率是7次的概率是多少?
方法:=POISSON.DIST(7,5,TRUE)
TRUE是计算统计公式的概率累加值,同二项分布公式中的FALSE一样,FALSE是指单次,就是说刚好恰好发生7次的概率。
现实场景中,不能满足任意一个特定事件内或者空间内发生的次数概率是相同的,所以应用于现实场景中需要考虑实际条件。
一般现实生活中二项分布会比较常用。
3.正态分布
连续变量分布是一个随机变量在其区间内能够取任何数值所具有的分布。正态分布是一种连续型的随机变量分布。
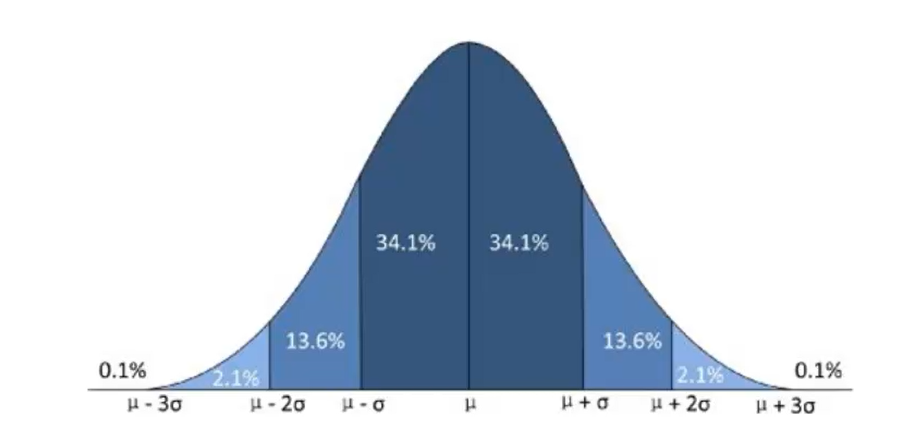
世界上绝大多数分布都属于正态分布。正态分布的形状是一条钟型曲线。以均值为中心左右对称,形状和均值μ以及方差有关。
切比雪夫定义,可以帮助快速的估约数据。
正态分布公式:
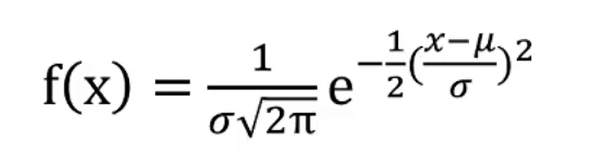
标准正态分布:
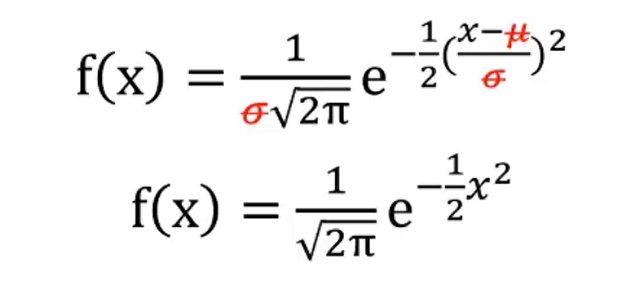
均值为0,方差为1的正态分布。
概率密度函数和累计分布函数(在更多的应用场景中,更多的看累计分布函数)

应用示例:
要求:标准正态分布中,z小于等于1的概率?z在区间-1~1.25的概率?z大于2的概率?
方法:Excel计算概率示例
=NORM.DIST(X函数值的区间点1,算数平均数0,分布的标准方差1,逻辑值TRUE累计分布值)
求出的是小于等于某一个值
在一定区间的,求解方法相当于两个区间的概率相减求面积。
求解大于的,1-前一段的面积。
用Excel可不用转成标准正态分布进行运算,可直接进行运算。
现实工作场景中,很少会遇见满足正态分布的情况,更多的是密率分布,某个奖品随机积分,质量检测等满足正态分布的情况下使用。
【假设检验】
思想是反正法,如果一件事情发生的概率很小,但是它发生了,我们就把这件事情的原始结论推翻。
个案的发生,不能去证明某一个结论,但是可以去否定它。
例如:某个工厂的产品合格率是99.9999%,但我们拿出100个样本的时候,发现有2个不合格,这个时候就能去否定这个合格率了。
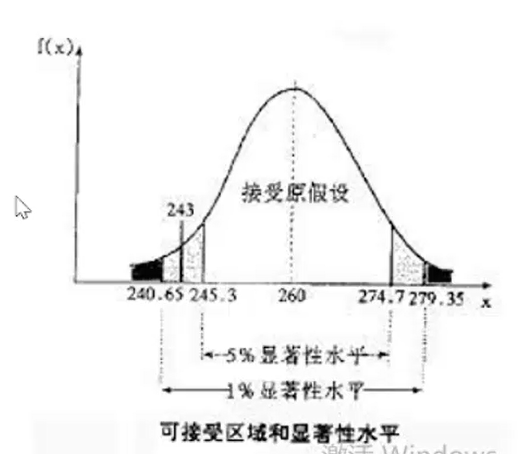
原假设H0:为了验证某一个假设是否发生,而去检验它。
备选假设H1:原假设不成立,则选择备选假设,包含一切让原假设不成立的概率。
原假设一般是小概率的事件,如果它发生了,我们就要怀疑并拒绝它。如果没发生,则接受它。
一般在做假设检验的时候,一般都是为了把它否定掉。所以在设立原假设的时候一般设立的场景是比较宽泛,或是看上去比较常规正常个,看上去更像是可能发生的,然后用小概率把它否定掉。
1.A&B测试:原理就是假设检验
通常采用抽样方式将数据划分成两组,通过一组控制一组对照的方式进行观察。
原假设为测试没有效果,分析师的目的是去否定它,当B组的数据和A组的数据有显著差异时,则能否定它。
2.Z检验
因为AB测试的数据都比较大(较大的数据基础容易把一些误差淡化掉,波动不明显),所以常用Z检验的方式进行验证,核心方法是当标准差已知时,验证A组合B组分均值是否相等。
Z检验公式:

示范案例:(具体详见课程91课时)

用Excel可计算Z值:=SDTR
根号=SQRT()
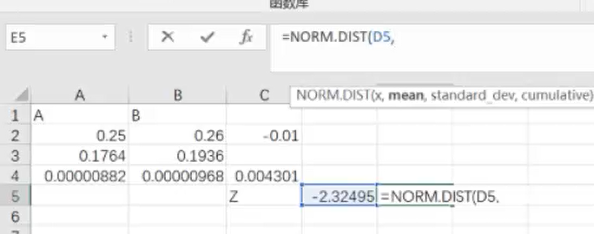
算出z值后转成正态分布,利用正态分布公式,把z值带入因为是标准正态分布,取值为均值为0,方差为1带入
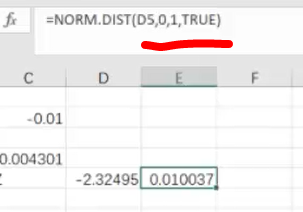
得出概率是1%,可以把原始假设拒绝掉
当基础数据变小的时候(基础数据变小,波动则明显)概率会发生变化(变大),这样得出结论则发生变化。
样本量、阈值(转化率标准差),决定假设概率的变化。
3.置信区间
它的作用是不轻易拒绝原假设,而是给一个可靠的范围。一般来说用95%作为可靠度。
在A&B测试中,我们可以定义为,用户购买转化率,有95%的可能性是在23%~27%之间,另外5%是小概率了。
在实际业务中,当样本量足够时,转化率的计算可以越过Z检验的计算过程,直接看转化结果,因为样本量越大,对置信区间会越严格。
转化率在数据类型上是0和1的集合。除此,还有数值型的计算,比如消费额度、消费频次等。
A&B测试用于产品设计和运营是比较好的方法,对于数据分析来讲,是一个很好的思维。