python的应用场景
重复性的东西编写脚本
和对于大数据量的操作
数据搭建的环境
不建议自己在网上找下载,建议下载anaconda,可在清华镜像里面下载anaconda,下载安装之后可在桌面上找到程序image.png
jupyer Notebook 为本次学习的常用项目,可进行可视化界面操作,分段
shift+光标执行
python基础
目录
1.数据类型
2.变量
3.三大结构
3.1列表
3.2元组
3.3字典
4.控制流
5.def命名函数
6.Numpy包
7.1 Series
7.2 dataframe
8.数据的筛选
9.数据的聚合
10.多表关联
11.多重索引
12.文本函数
13.空值&去重
14.apply函数
15.数据透视表
16.链接数据库
**1.数据类型:**
数值型,直接输入可以进行计算
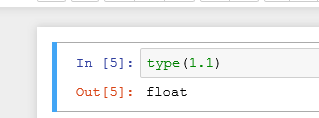
可用type进行数据类型的判断
返回整除的结果

显示余数的结果
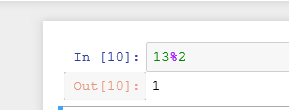
int整数直接计算
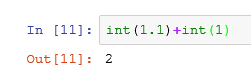
在python里面单双引号基本没有影响,但是在一段话表示的时候里面有单引号,整段话两边套上双引号才能识别,都为单引号系统则识别不了。相反,整句里面用双引号,整句的时候则用单引号作为系统区分。
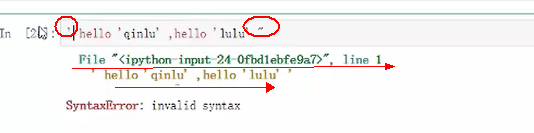
系统报错,将单引号改成双引号就可以识别(双引号为具体内容的边界)
边界用三引号的时候,内容可以包含单双引号的。
字符串:字符串同样不能直接进行计算,可用int转换成数字进行计算。
bool数组(ture默认为1,false默认为0):是可以进行与数字加减运算的
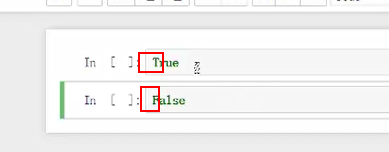
注意,第一个字母要大写
None:代表缺失值,不能进行运算(相当于表格内画斜线的格子)
“”:代表空值
2.变量
对应的叫“常量
a=1
变量=1(不加引号的时候就是变量,中文也可以,但是不建议用,因为兼容性差)
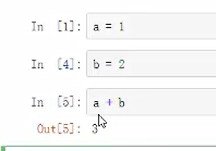
同时给对个变量赋值:a,b=1,2
3.1列表
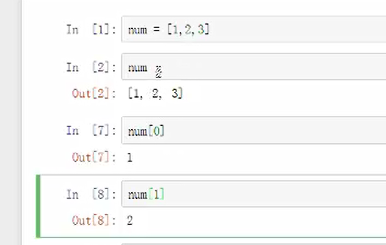
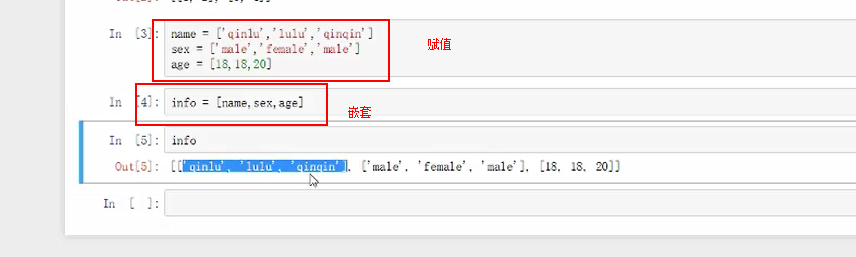
num=[1,2,3]表示数据里面有1,2,3,可以对其进行运算
len()列表里面有几个元素
访问列表里面有几个元素:列表名[] 第一个位置是“0”表示
查找sql、增加、更改、删除
shift+tab帮助键查
insert(位置,插入内容)插入
apped(插入内容)在末尾添加内容,但是插入的是唯一的值,不能添加多个因素
变量=变量+[内容1,内容2]添加多个因素可以此方法
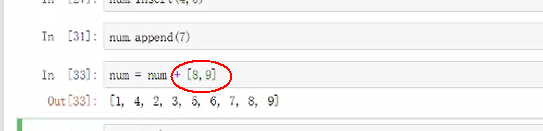
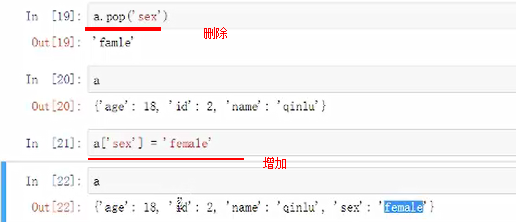
pop(位置)删除,直接空的话默认删除末尾的数字
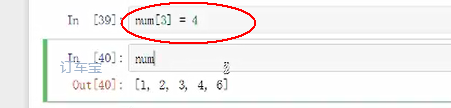
更改
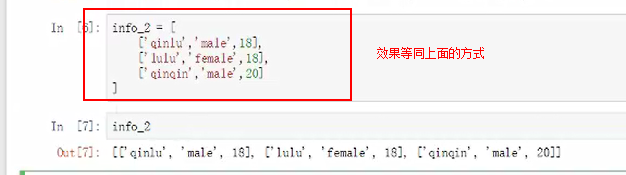
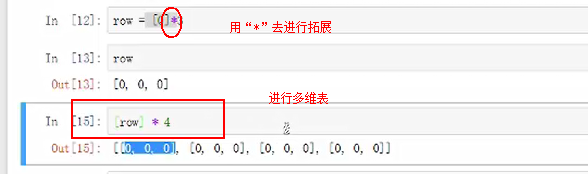
二维列表的创建
元组
()
元组不能修改,与列表对比
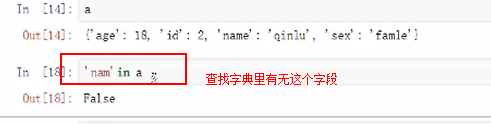
字典
键key值value对
在磁盘上占用空间比较大,查询效果一直会很快
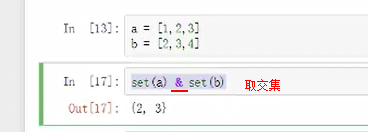
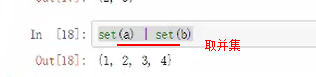
set()将列表集合化,相当并集去重
list(set())将set进行嵌套变成新的列表
if for while
【if】判断
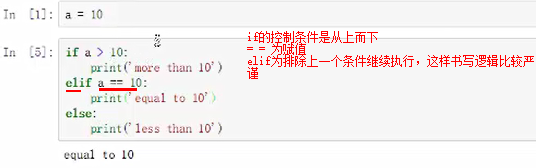
【while】循环
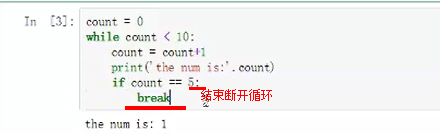
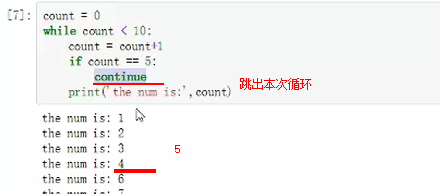
【for】for i in range(10) #10代表一个列表
for优点就是不容易形成死循环
需要1~100之间的数字
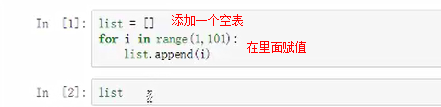
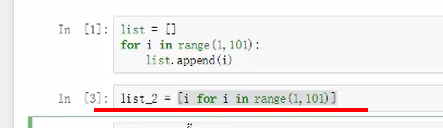
换一种写法,一句等同以上三句的效果
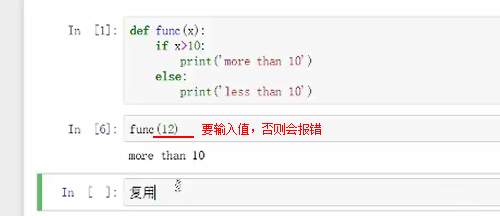
5.def命名函数
”:“
换行缩进表示def内部的函数内容
1~10之间求平方
map()全匹配
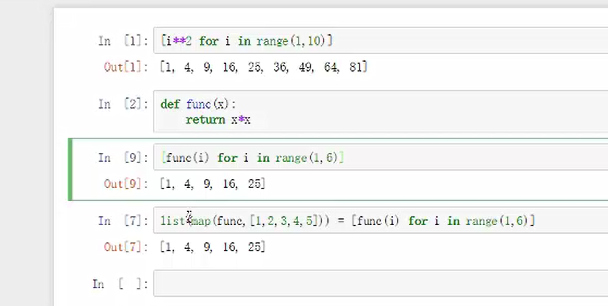
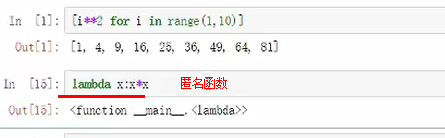
免除了定义函数的苦恼
python有很多第三方库,可以进行加载使用
加载:import collection
其中collection为第三方模块
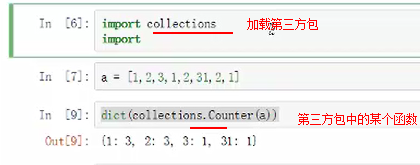
常用包:
特性是用法比较简单,并且有很多共享的第三方包
6.Numpy包
进行加载
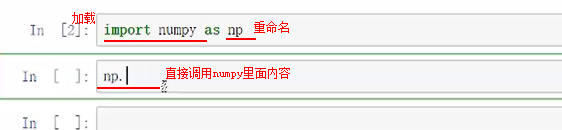
Python的特点是语法比较简单,并且有很多可以共享的第三方包其中今天提到的Numpy和Pandas这两个包常用语统计分析,这两个包会帮助我们保证速度的处理上千条数据。
【Numpy包进行加载和使用】
可用type查看数据类型
利用a变量对数组进行赋值
一样可以接受与数组一样的切片,简单运算

能够进行多维数据结构

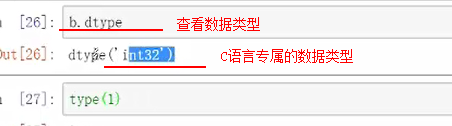
注意数据类型的区别“int32“
7.Pandas包
性价比会相对较高一些(因为是基于Numpy开发的)--操作方面更加习惯,数据框的形式。
进行加载并重命名为pd:import pandas as pd
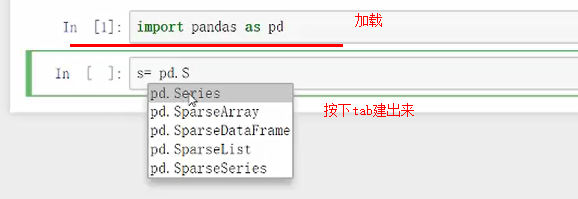
其主要有两个数据结构:
- 7.1 Series
一维的,在tab搜索时首字母S要大写
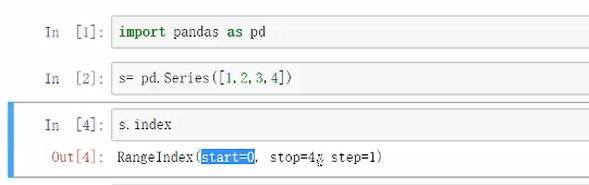
从0开始到4结束,索引
有一些比较高的属性shift+tab调出查看里面支持哪些参数

结果区别
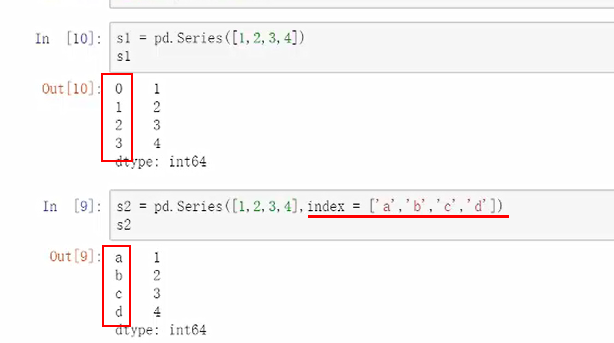
索引查找

索引也可以进行多个值索引,索引是列表表示,所以需要有方括号。
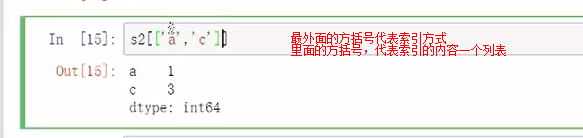
最外面的方括号代表索引方式
里面的方括号,代表索引的内容一个列表

比较智能的可以自动补缺

特性:原始的数值类型的内容增加一个字符串,则整体都会变成字符串,数据类型会保证统一。
基础是一维的近似于数组的结构。
- 7.2 dataframe
二维的,视觉上比较接近表格
相当于无数的一维叠加起来,支持多形式输入
通过字典来输入数据框:
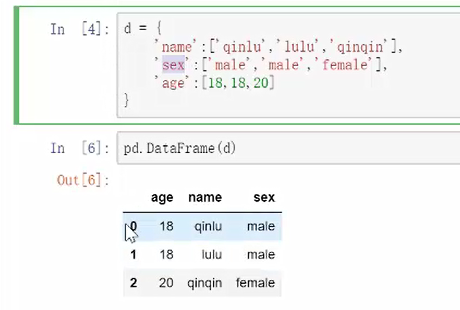
会发现顺序改变,是因为字典本身就是无需的
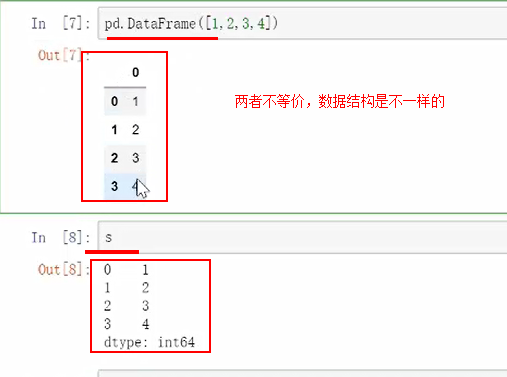
进行一维输入:会发现,两者不等价,数据结构是不一样的
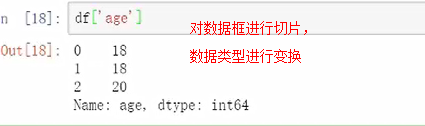
对数据框进行切片,数据类型进行变换
等价代码df.age,与别的一起写有可能会报错,建议用方括号的切片形式
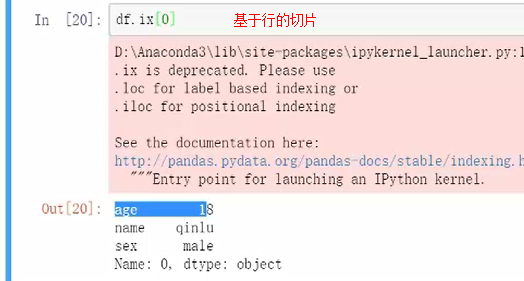
基于行的切片
同时可切多个值
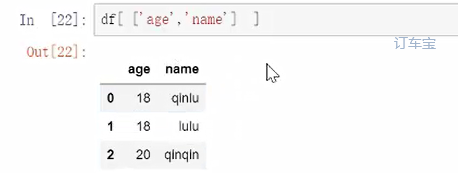
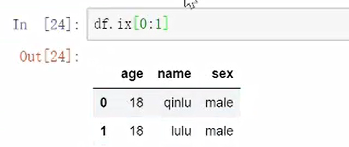
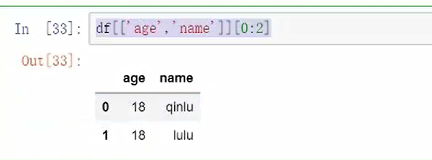
以上主要是些标准的查找
单独搜索某一值
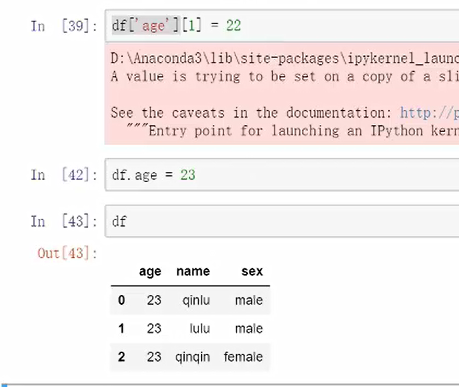
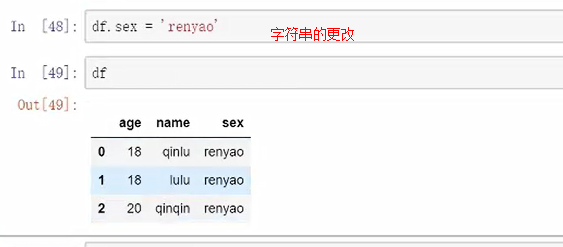
字符串的更改
针对的是某个行和某个列
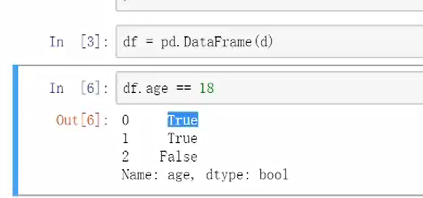
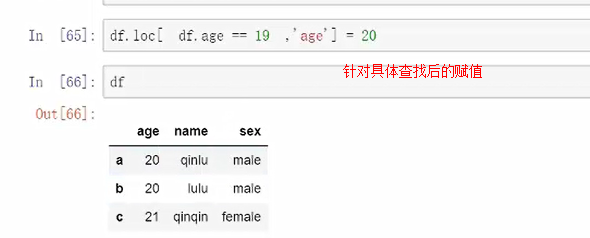
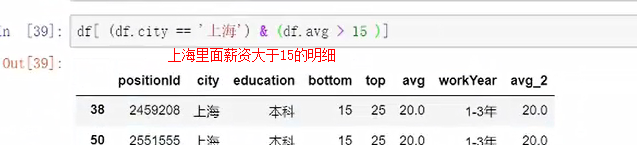
某一个特定值的筛选“年龄为18岁的”
方法1:逻辑判断
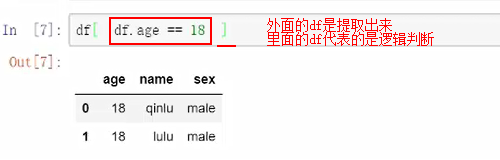
外面的df是提取出来,里面的df代表的是逻辑判断。
提取结构就是TRUE的结果内容

多条件的筛选查找
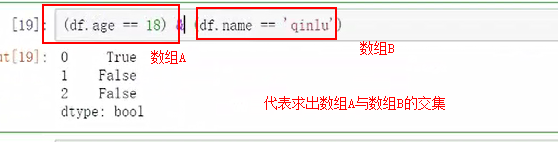
同时满足这两个条件的,“|”为并集
方法2:逻辑判断

iloc和loc查找(可同时满足两个参数进行切片的)
iloc所在行的数字进行索引,是针对第几行的
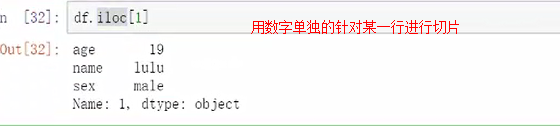
loc是针对标签进行切片的
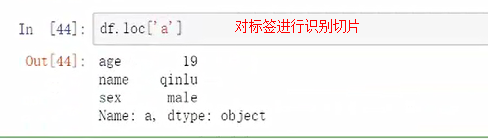
(可同时满足两个参数进行切片的)


df.ix是可以行和标签一起使用,但是还是会报错,不建议使用。
读入.csv文件:read.csv
首先把文件放在相同的目录下面
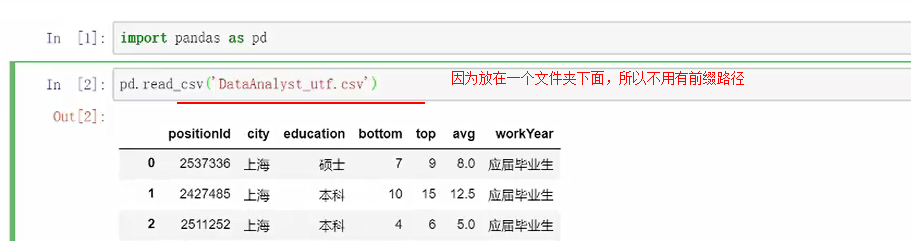
本身默认读取就是utf所以读取会很顺畅
如果改成读取gbk则会报错,如果读取gbk需要进行设置解析编码
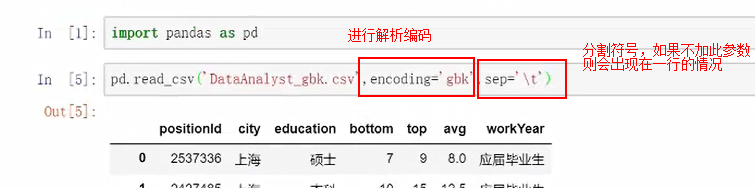
查看前几行:
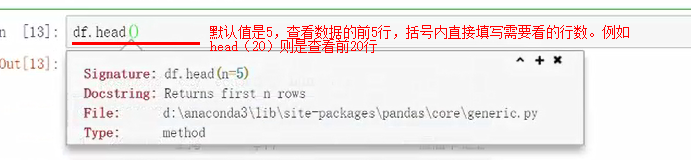
查看尾行:df.tail()
查看数据类型依然用:df.info()




还可以继续追加筛选过滤条件
8.数据的筛选
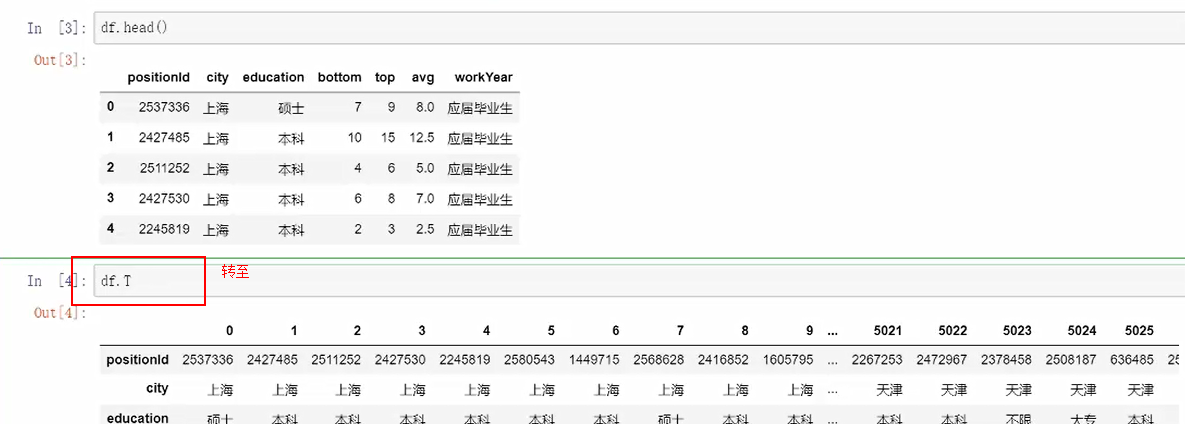
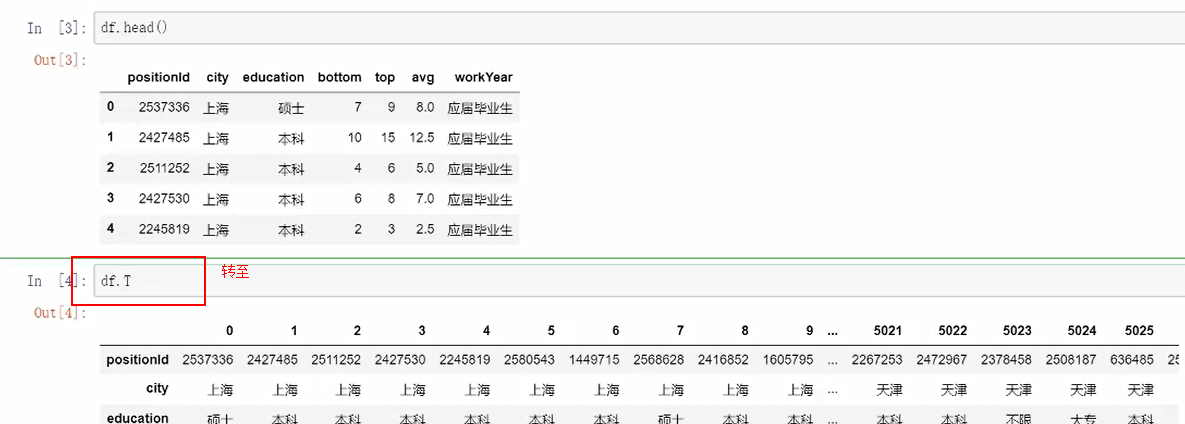
1.转至
表名称.T,可将表格快速的转至
2.排序
【values】函数
方法1:排序的依据by="排序依据"
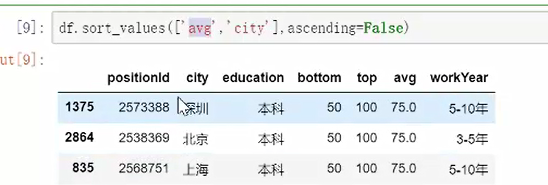
方法2:通过数组也可以进行排序
df.avg.sort_values()
二者区别是,如果用数组调,返回的是数组,在数据框里面调直接返回的是数据框。
ascending=False改变排序升序为降序
对字段进行排序:直接把条件加入
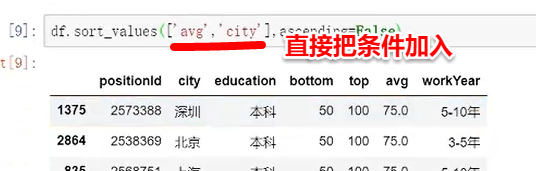
列出的表不是根据实际的中文顺序进行的,介意的话需建另一张表格进行调整。
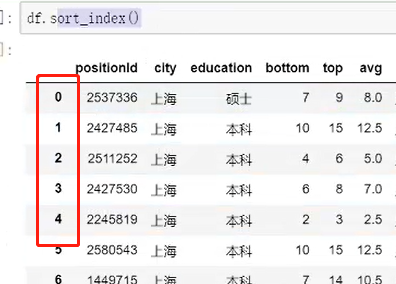
【index】按照索引的排序
【rank】函数
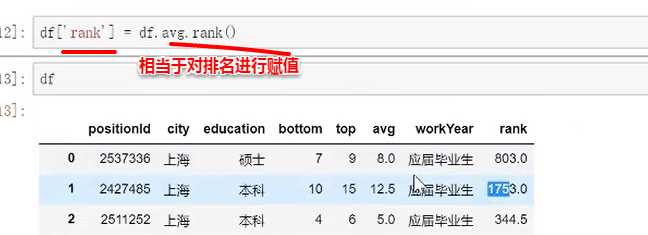

默认顺序为升序排列,添加ascending参数改为降序
method参数默认为加权平均,改为min直接用排序第一个,符合现实使用的习惯。改为first则排序不考虑并列情况直接按照顺序来进行。
3.查找重复

直接可查出有多少个唯一值
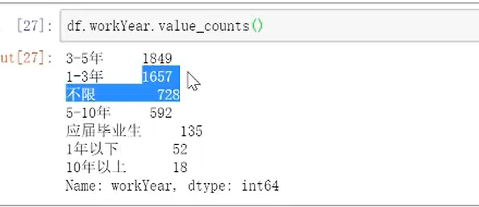
加个count可直接查找出合计数量
4.描述性统计
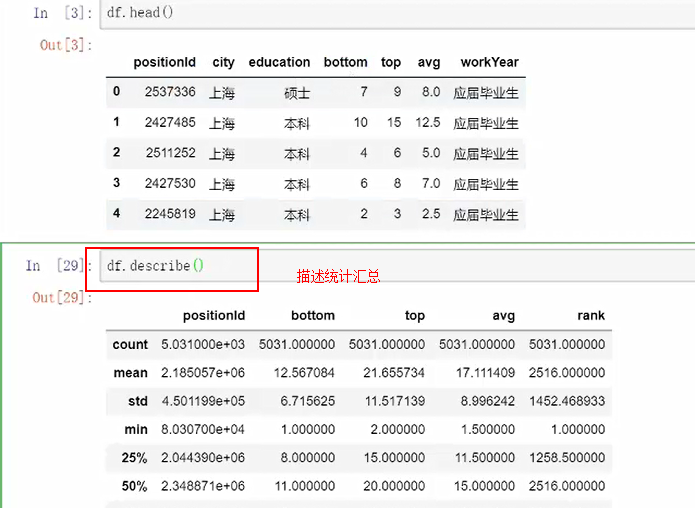
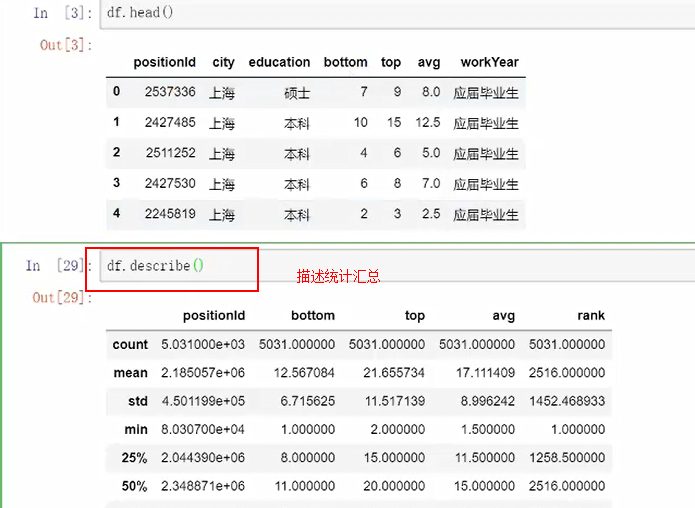
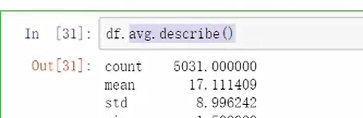
5.累计累加

6.分段统计
使用更加适合分段统计的cut函数
pd.cut(df.avg.bins=5) 系统自动分割成5部分
也可以自定义区间,然后命名

常用于用户分级、消费水平分割等使用场景
7.分位法进行分割统计
分位法函数:.qcut()

x具体的内容例如df.avg
q排名几等分
retbins是否包含开区间闭区间
precision分割出来的精度
duplicates是否要进行些去重操作
9.数据的聚合
聚合函数:mysql不支持分组排名,则可用此函数groupby
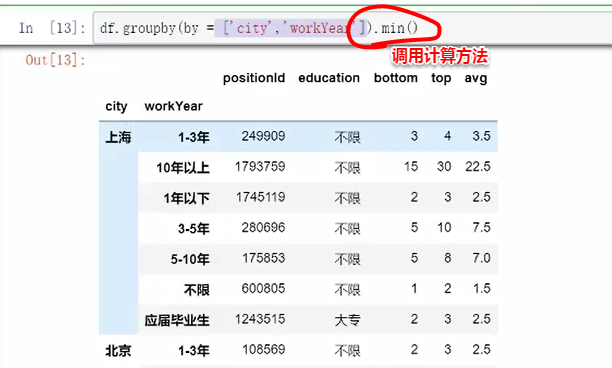
通过for循环可把分组内容打印出来进行查看

10.多表关联
三种关联方法
1.merge根据键值,对的是某一列

同名去重不同名保留
附加:
修改表的字段名称可用rename()函数
也可把行名提取出来,然后从0开始查其位置进行更改,再赋值的方法(一般用于只改一个,比较简单)
col=list(df.columns)
col[0]='all'
df.columns=col
2.join针对索引进行

针对的是固定的索引例如日期
3.concat堆叠,对应的是对象

两张表格上下放一起,“暴力组合”
之间是上下拼接,增加函数 .axis=1 进行左右拼接,对不上的默认为空值。
应用场景:例如1~12月份相同字段的销售统计的拼接汇总等。
11.多重索引
方法1:可用切片

方法2:数据框类型的
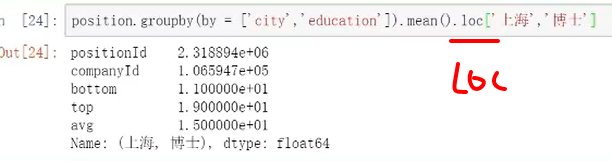
不借助groupby进行设置多重索引的方法:set_index

把列变成索引进行排序,输出可达到整理在一起的效果

反过来把索引变成列,增加函数reset_index()即可
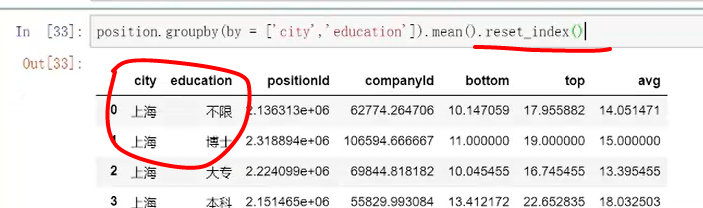
这时后面可直接[]去引用。
12.文本函数
pandas里面预处理函数
需求:想把表格内某一列带方括号的字段去掉方括号。
思路1:直接进行左右两边切掉(不成功,因为操作是针对数组进行的,是针对索引的切片)
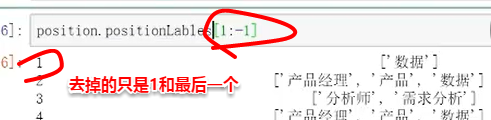
思路2:调用.str()(可行)
例如:.str.count统计字符串出现的次数
.str.find(“数据”)从哪个位置开始统计
.str都是针对值里面的字符串进行的操作

需求:继续把单引号排除
思路1:用空值替换单引号(不可行)

因为replace针对的是表格内具体的某一值进行替换,所以,上面对表格内字段进行替换并没有成功。
思路2:增加.str (可行)

13.空值&去重
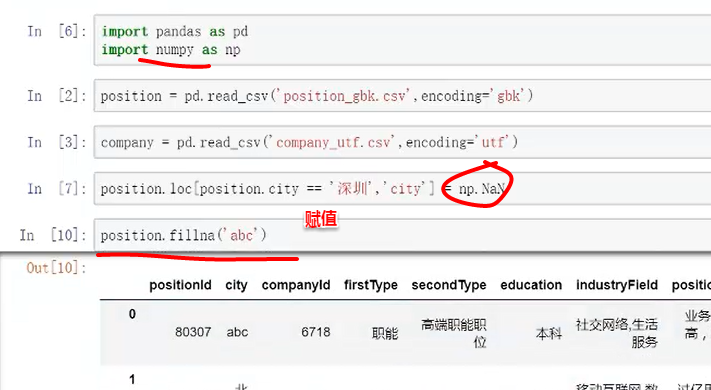
1.空值
对表赋予空值,及对空值进行再赋值

2.删除重复元素

去重方法1:
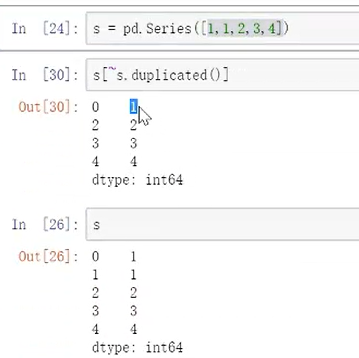
去重方法2:相对更简单

14.apply函数
帮助我们把一个函数或者自定义函数应用到所有的行或者列里面进行处理,可大大提高数据分析的效率。
需求示例:
薪资显示数值后面加上K,例如11.5K
方法1:

用 .str将浮点数据转成文本再进行拼接
方法2:
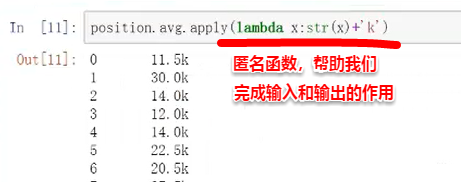
输入x,输出的是. str和k进行拼接
输入从position.avg来
apply的优点是特别快
方法3:等价方法2(在里面可加进去简单的判断)
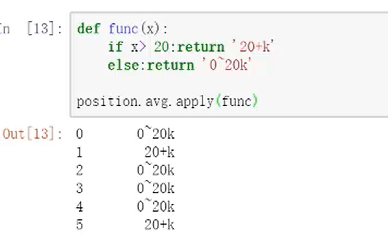
方法4:
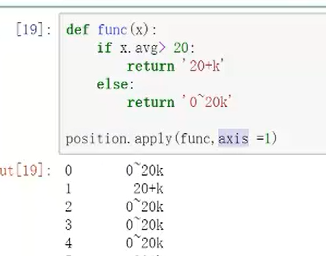
注意,直接position会直接报错,因为对象不能针对整个表,其中参数axis默认为0,是空值对应函数应用到列里面。需要把它设置为=1,说明函数设置应用到列,对这一列数组进行操作,指明是x.avvg则可成功。
1.apply聚合(分组)
需求:不同城市下面新增排名前5的职位。
分析需求:
①对不同城市--分组
②前5---排序

方法1:记住输入和输出

数据拆开后再合并
方法2:

通过控制参数,变成升序

agg和apply的区别:agg聚合后针对固定的行和列,apply的灵活性比较高,可以对数据进行拆分再组合,不涉及行数的变化用agg是可以的。
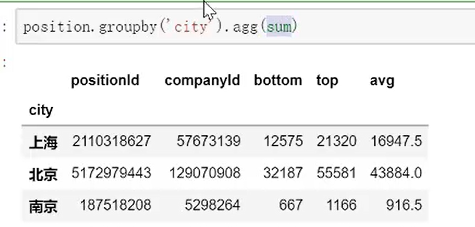
agg直接调用方法;

等价于:

比较高级的用法是,可以同时应用多个函数
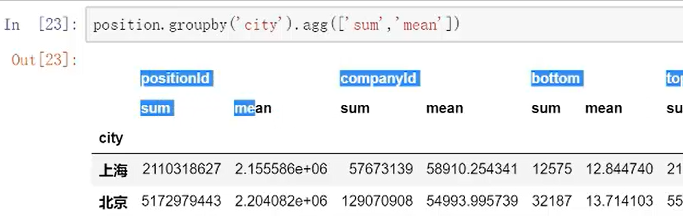
15.数据透视表
可以处理超大的数据对比Excel透视
首选要考虑“我想要的数据透视表形式是什么样子的”
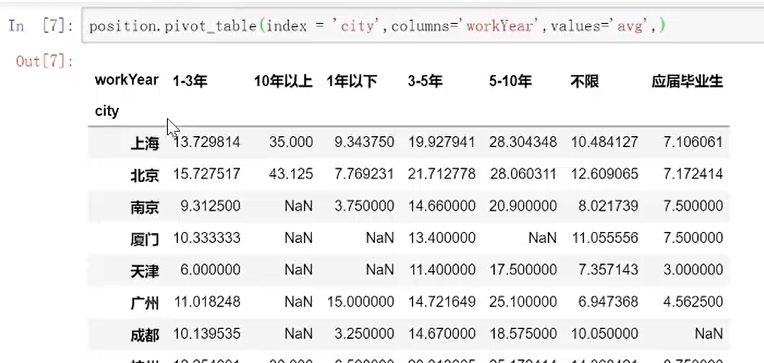
values:具体的哪个值进行计算
index:按照什么来进行聚合,例如“city”
columns:列是设什么样子的,例如“workyear”
aggfunc:具体形成什么样子的值,默认是“mean”
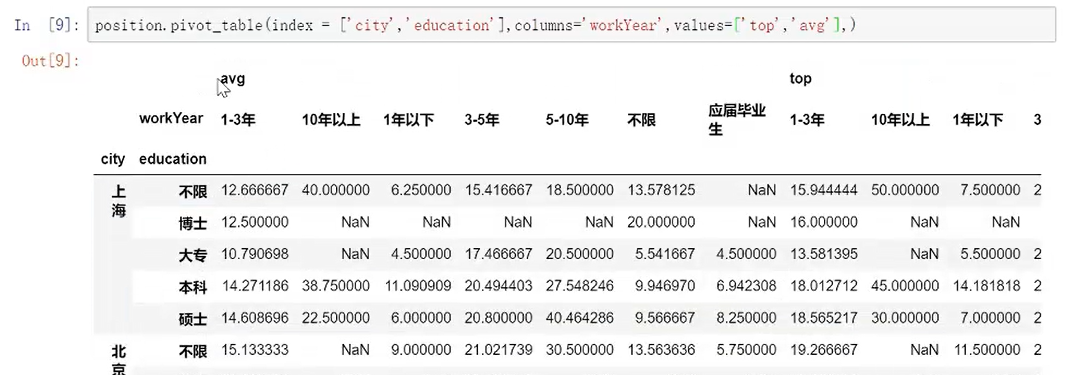
多重索引同样可以
调用np,所以要用np.mean等计算方式,直接mean则会报错
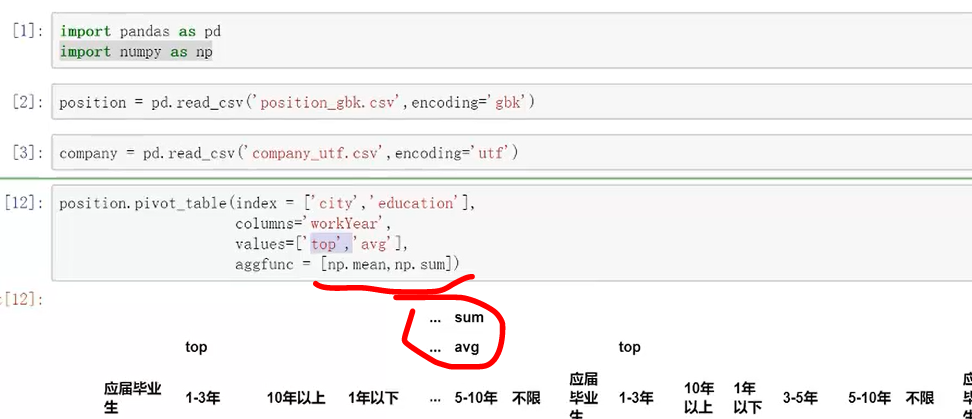
也可在此表格进行继续接片
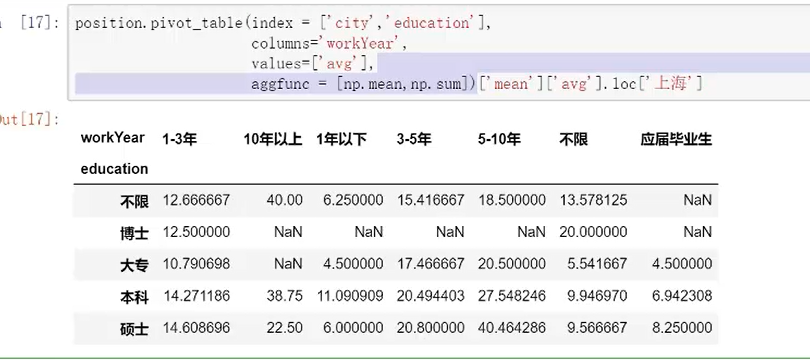
其中margins参数=Ture是在透视表下面添加汇总项目
dropna=Ture,就是把一些空值砍掉
透视表的一些高级用法:
需求:只想要对平均薪资进行平均,top进行求和,想要计算values的值是有针对性的。
方法:aggfuns里面把列表改成字典
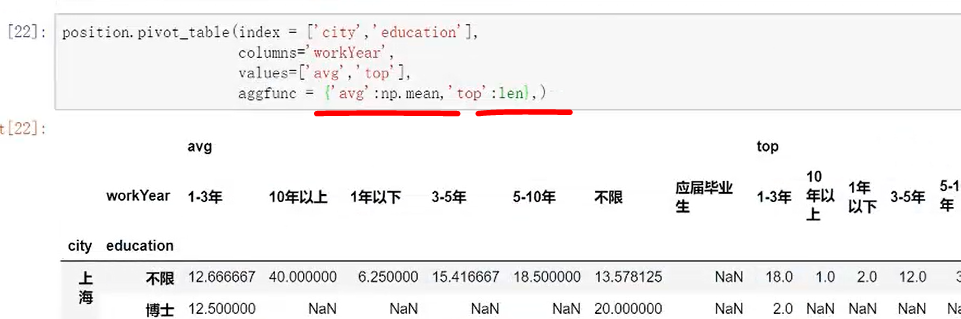
应用场景,对处理大数据量的统计提供很好的工具。
16.链接数据库
建议用pandas链接数据库,会比较方便
需要安装一依赖包
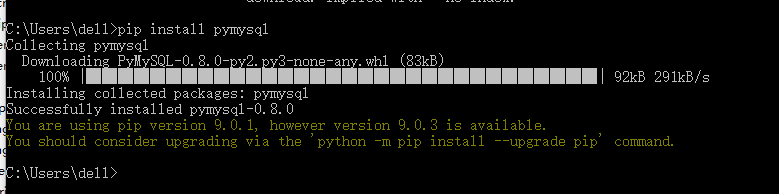
老师在讲的时候说新人在安装依赖包的时候回会遇到些问题,很幸运~我就遇到了~~~
安装包的时候出现“pip不是内部外部,或其他可执行的程序”的报错
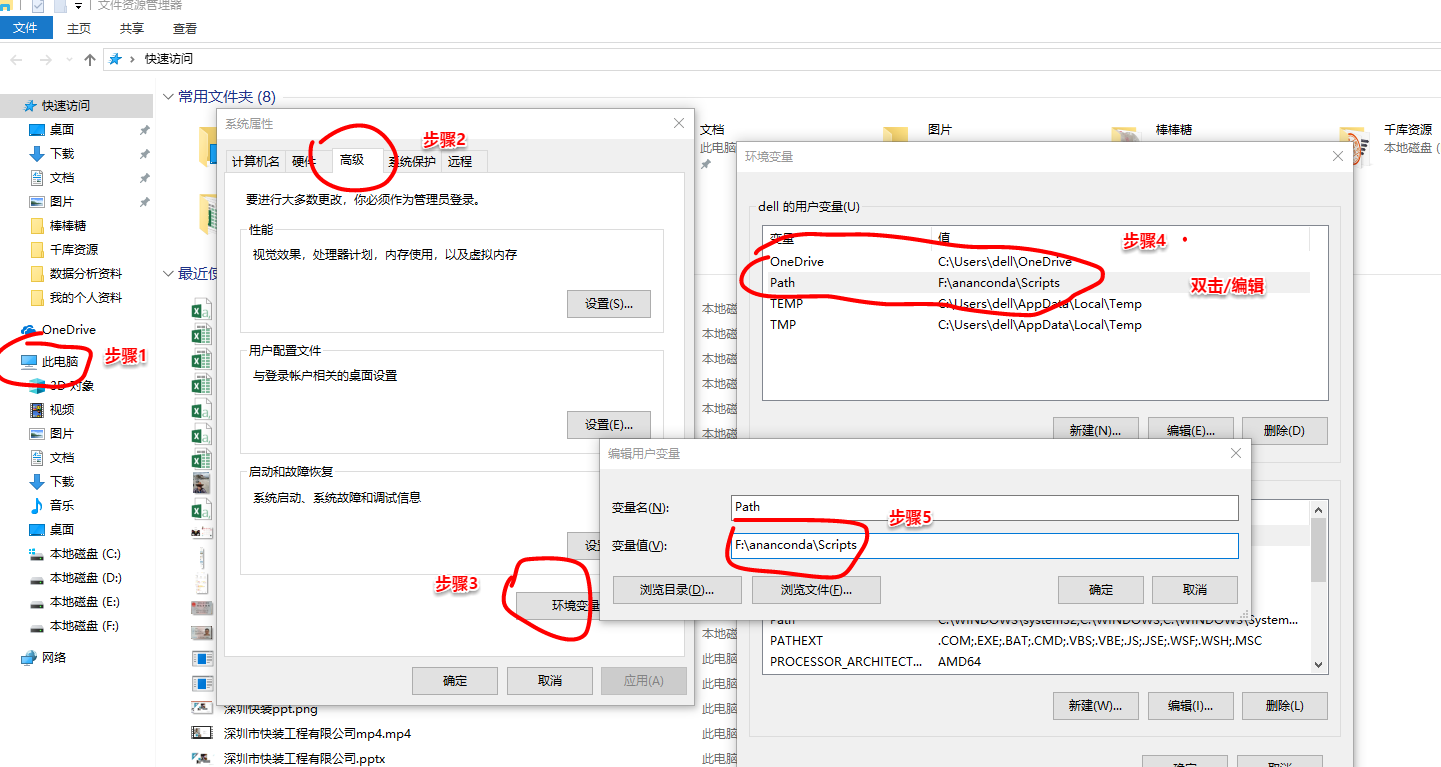
方法:需要把环境配置一下,
此电脑-->属性-->高级-->环境变量-->Path-->把ananconda里面含有pip程序的两个文件的位置路径放进去-->保存-->调用cmd(win+r,输入cmd)-->成功

1.链接数据库方式
import pymysql #加载变量
conn=pymysql.connect(
host='localhost', #定义新的变量链接,可以直接输入localhost,也可以直接输入本地的地址127.0.0.11因为mysql一般都是本地所以这两种方法均可
user='root', #数据库用户名称
password='12346', #账号密码
db='data', #想要链接的数据库
port=3306, #输入端口,默认的,如果有变化自己更改即可
charset='utf8' #文本编码如果是gbk则改成gbk对应
)
创建后调用一个方法(直接记住)
conn.cursor()
之后可以用 .execute()来进行sql语句的输入
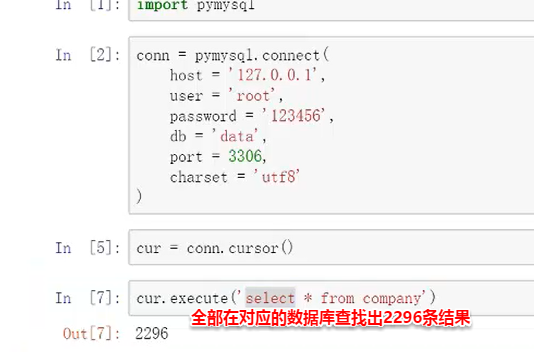
如果需要把所有的结果都执行出来
data=cur.fetchall()
不过会以元组的形式输出,需要简单处理一下
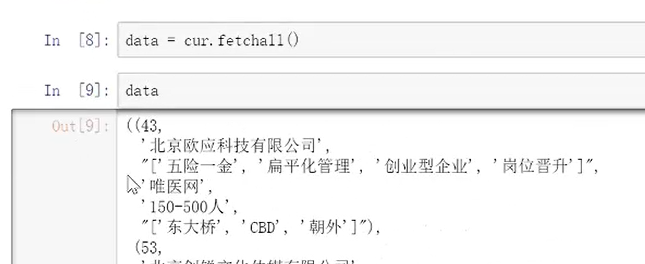
进行增删该查后的结果提交操作可用.conn.commit()方可提交
打开游标之后,需要养成好的习惯进行关闭
cur.close()
同样,数据库连接进行关闭
conn.close()
2.连接数据库方式
pandas在数据库的应用最关键的是sql和con
可直接先把sql语句写好
要注意的是链接是比较特殊的,新的链接方式 .orm帮助数据读写的sqlalchemy

从读取到处理然后到写入数据库的过程:
①读取表:
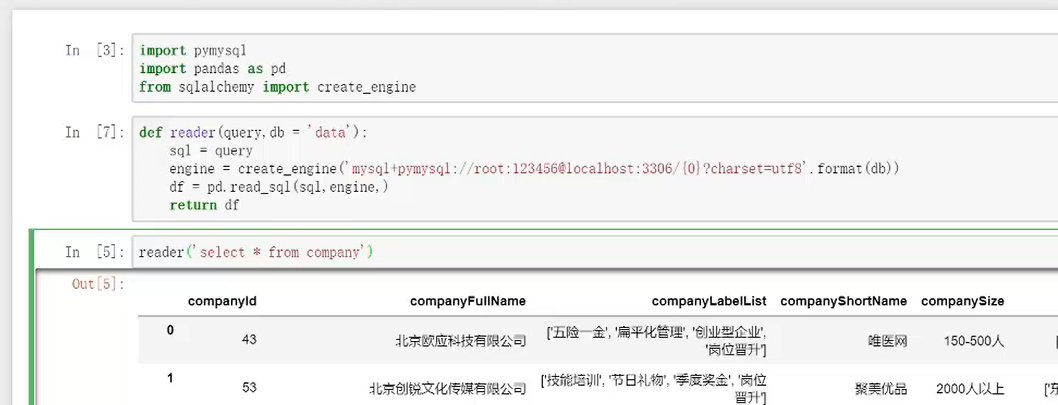
如果忘记数据库中有哪些表的具体名头可以用此函数进行查看
reader('show tables')
②处理合并多表格
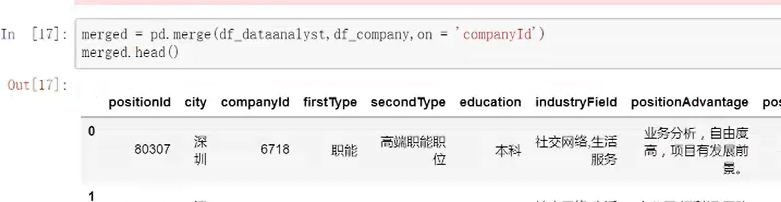
③按照需求条件,分组汇总,提取部分数值转换重置成数据框
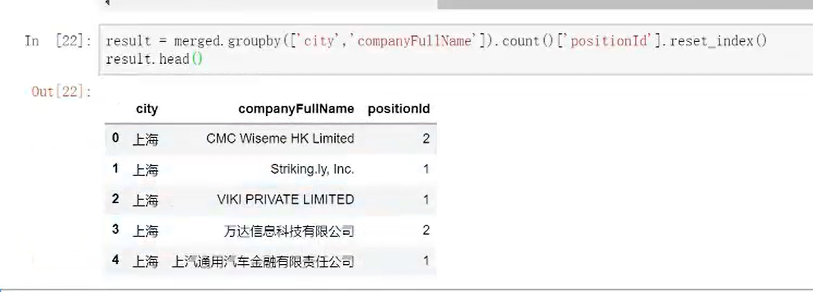
④查看数据类型是否需要更改
result.info()
⑤写入数据库

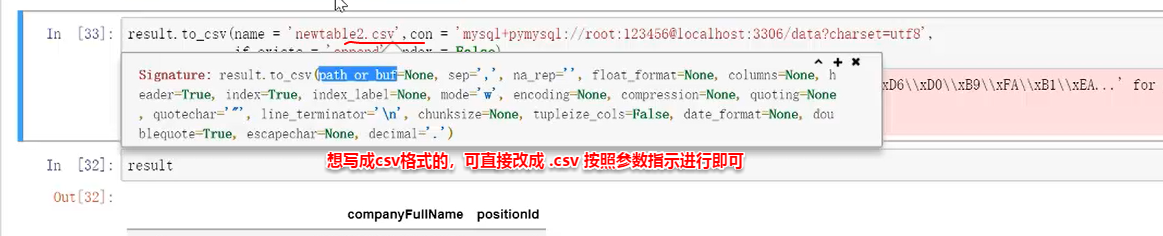
参数if_exists指的是他是否存在了='fail'是默认的,也就是说如果表存在的话,则写入是失败的。
把参数修改成 ='append' 是指插入数据,即表存在的话则是插入数据,表不存在的话则会是新建数据,
参数index,如果=True是代表写入的时候把数据框里面的索引变成一列进行存储;一般会更改为=False不写入。

返回mysql数据库查看
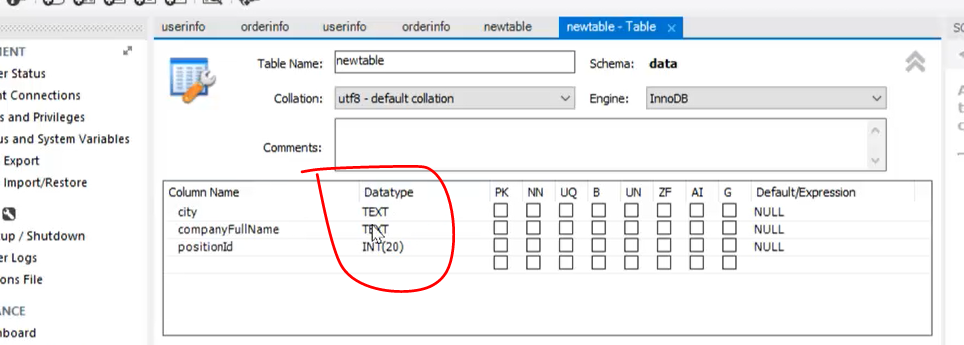
会发现新导入的表格的字段类型和之前的不太相符,不是预想的最优形式。
建议在开始做的时候,预先在数据库中建好,设置好新的表格表头及类型,然后再进行导入。
并且注意,在python导入运行步骤时候,如不小心执行了多次,则在数据库中也会相应的重复增加多次的数据,所以操作要小心谨慎。
当在数据库建表的时候字段小于导入字段的时候,python会报错。
当在数据库建表的时候字段大于导入字段的时候,python则可正常写入,在数据库中可自动匹配为空。
⑥写入 .csv