# 导入re模块
import re
# 使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话,可以使用group方法来提取数据
result.group()
re.match用来进行正则匹配检查
若字符串匹配正则表达式,则match方法返回匹配对象(Match Object)
否则返回None
import re
result = re.match("itcast","itcast.cn")
result.group()
re.match() 能够匹配出以xxx开头的字符串

大写字母表示 非
w 匹配字母,数字,下划线
W 表示除了字母 数字 下划线的
import re
ret = re.match(".","a")
ret.group()
ret = re.match(".","b")
ret.group()
ret = re.match(".","M")
ret.group()

import re
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
ret.group()
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
ret.group()
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
ret.group()
ret = re.match("[hH]","Hello Python")
ret.group()
# 匹配0到9第一种写法
ret = re.match("[0123456789]","7Hello Python")
ret.group()
# 匹配0到9第二种写法
ret = re.match("[0-9]","7Hello Python")
ret.group()
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用d进行匹配
ret = re.match("嫦娥d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥d号","嫦娥3号发射成功")
print(ret.group())

正则表达式里使用""作为转义字符
需要匹配文本中的字符""
使用反斜杠"\"

import re
ret = re.match("[A-Z][a-z]*","Mm")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())

import re
ret = re.match("[a-zA-Z_]+[w_]*","name1")
print(ret.group())
ret = re.match("[a-zA-Z_]+[w_]*","_name")
print(ret.group())
ret = re.match("[a-zA-Z_]+[w_]*","2_name")
print(ret.group())

import re
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?[0-9]","33")
print(ret.group())
ret = re.match("[1-9]?[0-9]","09")
print(ret.group())

import re
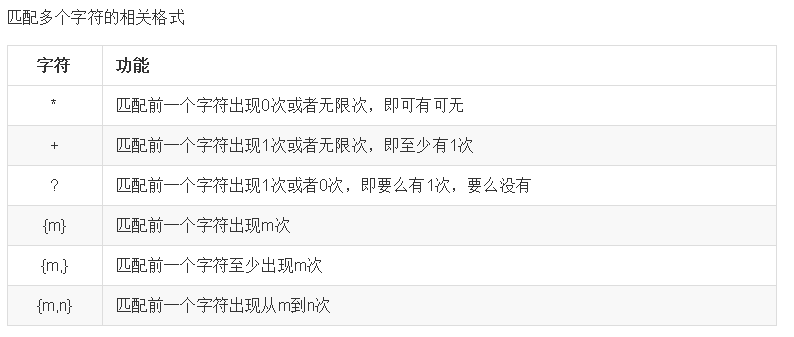
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
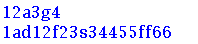

import re
# 正确的地址
ret = re.match("[w]{4,20}@163.com", "xiaoWang@163.com")
print(ret.group())
# 不正确的地址
ret = re.match("[w]{4,20}@163.com", "xiaoWang@163.comheihei")
print(ret.group())
# 通过$来确定末尾
ret = re.match("[w]{4,20}@163.com$", "xiaoWang@163.comheihei")
print(ret.group())

匹配一个单词的边界
B 匹配非单词边界

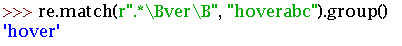
import re
ret = re.match("[1-9]?d","8")
print(ret.group())
ret = re.match("[1-9]?d","78")
print(ret.group())
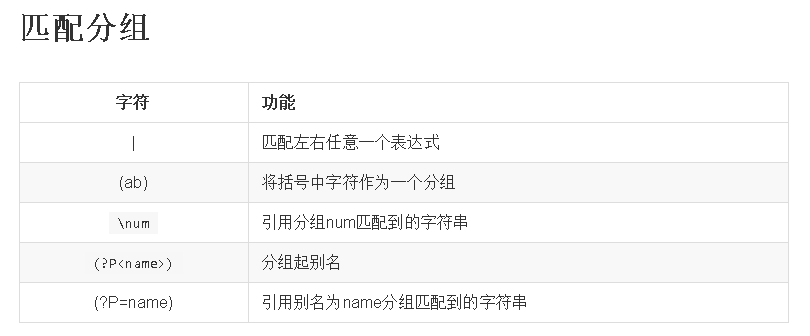
# 添加|
ret = re.match("[1-9]?d$|100","8")
print(ret.group())
ret = re.match("[1-9]?d$|100","78")
print(ret.group())
ret = re.match("[1-9]?d$|100","100")
print(ret.group())

import re
ret = re.match("w{4,20}@163.com", "test@163.com")
print(ret.group())
ret = re.match("w{4,20}@(163|126|qq).com", "test@126.com")
print(ret.group())
ret = re.match("w{4,20}@(163|126|qq).com", "test@qq.com")
print(ret.group())

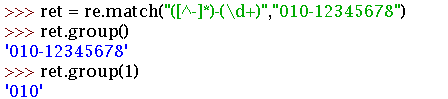
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</html>")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错
ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>w*</1>", "<html>hh</html>")
print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
ret = re.match(r"<([a-zA-Z]*)>w*</1>", "<html>hh</htmlbalabala>")
print(ret.group())

import re
ret = re.match(r"<(w*)><(w*)>.*</2></1>", "<html><h1>www.itcast.cn</h1></html>")
print(ret.group())
# 因为子标签不同,导致出错
ret = re.match(r"<(w*)><(w*)>.*</2></1>", "<html><h1>www.itcast.cn</h2></html>")
print(ret.group())

import re
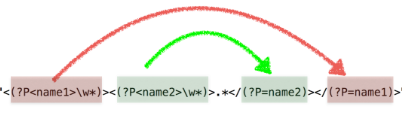
ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
print(ret.group())
ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")
print(ret.group())

import re
ret = re.search(r"d+", "阅读次数为 9999")
print(ret.group())

import re
ret = re.findall(r"d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)
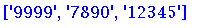
import re
ret = re.sub(r"d+", '998', "python = 997")
print(ret)

import re
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
# 替换的是 原数据 + 1
ret = re.sub(r"d+", add, "python = 997")
print(ret)
ret = re.sub(r"d+", add, "python = 99")
print(ret)
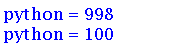
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
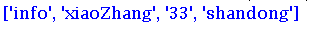
Python里数量词默认是贪婪的 匹配尽可能多的字符
非贪婪 总匹配尽可能少的字符。
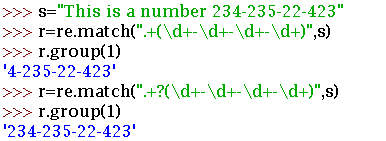

2020-06-02
